

The fields of AI and agents are evolving so fast, and we’ve always wanted all developers to feel productive for authoring their smart creations. That’s why Google has been offering its open source Agent Development Kit framework. What started with Python has now grown into a multi-language ecosystem: Python, Java, Go and Typescript.
Today, we’re happy to announce the release of version 1.0.0 of ADK for Java. Let’s have a look at some of the highlights in this new release, and take it for a spin!
But before reading more, please have a look at this video which illustrates a fun and concrete use case of an agent implemented with ADK for Java 1.0.0:
Link to Youtube Video (visible only when JS is disabled)
The release of ADK for Java 1.0.0 introduces several major enhancements to the framework:
GoogleMapsTool for location-based data and the UrlContextTool for fetching web content. It also features robust code execution via ContainerCodeExecutor and VertexAiCodeExecutor.Plugins for global execution control, such as logging or guardrails.ToolConfirmation workflows, allowing agents to pause for human approval or additional input.Time to zoom in on those features!
Agents are all about perceiving and interacting with the external world, beyond the confines of the intrinsic knowledge of the Large Language Models (LLM) that power them. For that purpose, agents can be equipped with useful tools.
To get more accurate answers from your agents, you probably know that you can ground your agent responses with search results from Google Search thanks to the GoogleSearchTool. Now it’s also possible to ground answers with information coming from Google Maps thanks to the GoogleMapsTool (in Gemini 2.5):
var restaurantGuide = LlmAgent.builder()
.name("restaurant-guide")
.description("A restaurant guide for the traveler")
.instruction("""
You are a restaurant guide for gourmet travelers.
Use the `google_maps` tool
when asked to search for restaurants
near a certain location.
""")
.model("gemini-2.5-flash")
.tools(new GoogleMapsTool())
.build();If you’d ask your restaurant guide about the most “gourmet” restaurant near the Eiffel tower in Paris, it would tell you about the famous Jules Vernes restaurant within the Eiffel tower itself, and would even tell you about its rating and reviews:
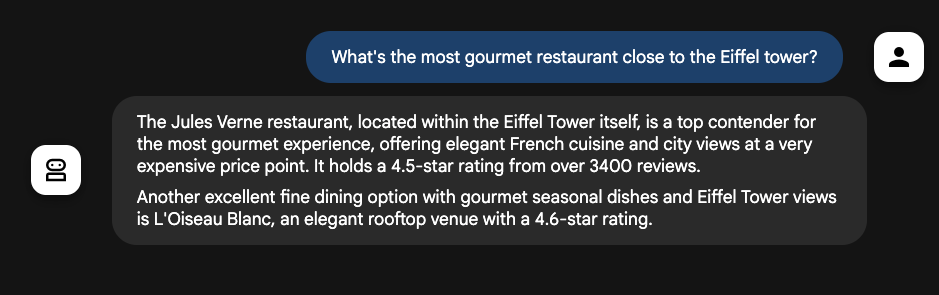
Another useful grounding tool is the UrlContextTool, which lets Gemini fetch the URLs given in the prompt. No need to create a web fetching pipeline to feed your agent, it’s built-in.
Passing new UrlContextTool() this time instead of the maps tool in our previous example, when asked: “Tell me more about: https://blog.google/innovation-and-ai/technology/ai/nano-banana-2/”, your agent would summarize the article as follows:
“Google DeepMind has introduced Nano Banana 2, an advanced image generation model that combines the sophisticated features of Nano Banana Pro with the rapid speed of Gemini Flash. This new model offers high-quality image generation, faster editing, and improved iteration across various Google products, including the Gemini app and Google Search. It provides enhanced creative control, including subject consistency for up to five characters and 14 objects, precise instruction following, and production-ready specifications for various aspect ratios and resolutions. Google is also enhancing its SynthID technology with C2PA Content Credentials to better identify AI-generated content.”
There are several other tools you might be interested in:
ContainerCodeExecutor and VertexAiCodeExecutor can respectively execute code locally against Docker containers or in the cloud within Vertex AI.ComputerUseTool abstraction can be used to drive a real web browser or computer (but you’ll have to implement a concrete implementation of BaseComputer to drive, for example, the Chrome browser, via a Playwright integration.)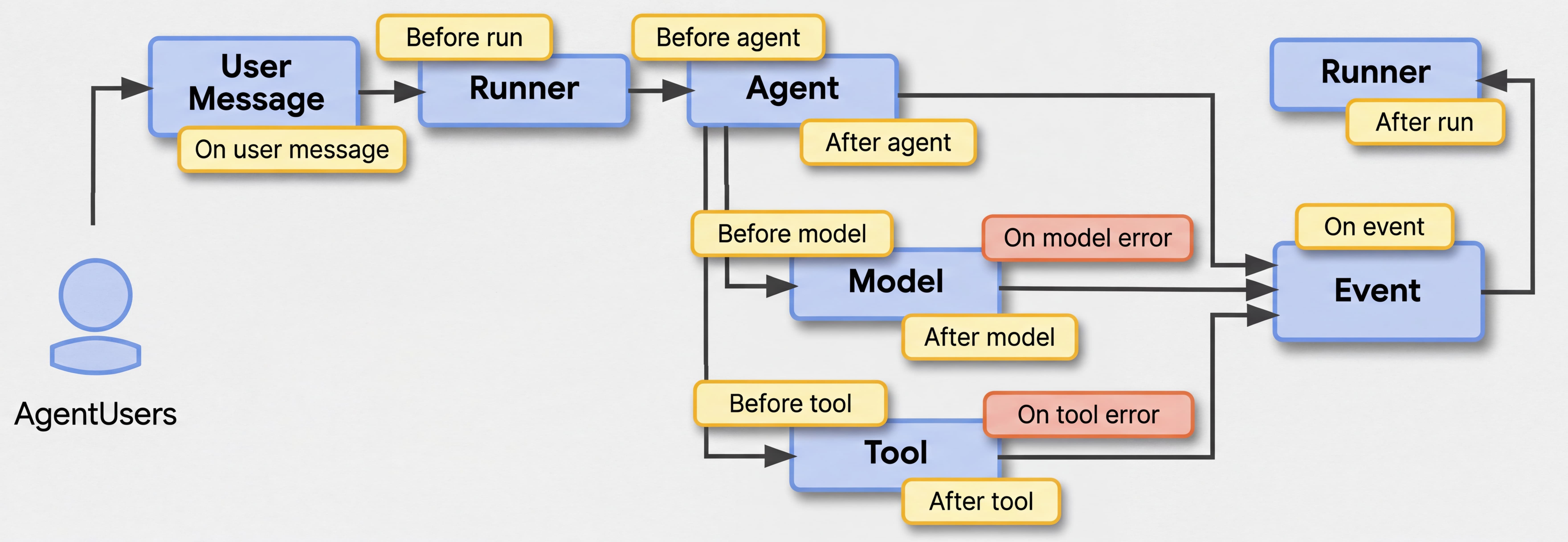
When defining your agents, you used callbacks at different points in the lifecycle of an agent interaction. Typically, with a beforeToolCallback(), you can either log the tool that is being invoked by the agent, or even prevent its execution and return a canned response instead.
Callbacks are very useful, but have to be applied at the level of each agent and sub-agent that you define. What if you need to apply some sane logging practices throughout your agent hierarchy? That’s where the notion of App and Plugins come into play.
The App class is the new top-level container for an agentic application. It anchors the root agent, holds global configurations (like event compaction that we’ll talk about later), and manages application-wide plugins.
Plugins provide a powerful, aspect-oriented way to intercept and modify agent, tool, and LLM behaviors globally across all agents within the App or Runner and provide additional extension points beyond the existing callbacks.
A handful of plugins are available out of the box:
LoggingPlugin: Provides detailed, structured logging of agent executions, LLM requests/responses, tool calls, and errors.ContextFilterPlugin: Keeps the LLM context window manageable by intelligently filtering out older conversation turns while safely preserving required function call/response pairs.GlobalInstructionPlugin: Applies a consistent, application-wide instruction (e.g., identity, safety rules, personality) to all agents dynamically.Let’s say you want your support agent to always write in ALL CAPS, configure the app and plugin by defining your own Runner loop:
// Define plugins
List<Plugin> plugins = List.of(
new LoggingPlugin(),
new GlobalInstructionPlugin("ALWAYS WRITE IN ALL CAPS")
);
// Build the App
App myApp = App.builder()
.name("customer-support-app")
.rootAgent(supportAssistant)
.plugins(plugins)
.build();
// Run the application
Runner runner = Runner.builder()
.app(myApp) // the App!
.artifactService(artifactService)
.sessionService(sessionService)
.memoryService(memoryService)
.build();Beyond the existing plugins, you might want to extend the BasePlugin abstract class yourself, to apply your own rules to your agentic application and its agents.
In the previous section, we uncovered the App concept, and it has another important configuration method that we’ll study now: eventsCompactionConfig().
Event compaction allows you to manage the size of an agent's event stream (history) by keeping only a sliding window of the last events and/or summarizing older events, preventing context windows from exceeding token limits and reducing latency/costs on long-running sessions. This is a common practice of context engineering.
In the example below, we configure the event compaction strategy. Not all parameters are mandatory, but they illustrate the level of control you can have, on the compaction interval, the overlap size, a summarizer to summarize the events that will be discarded, a threshold with a number of tokens, and the event retention size.
App myApp = App.builder()
.name("customer-support-app")
.rootAgent(assistant)
.plugins(plugins)
.eventsCompactionConfig(
EventsCompactionConfig.builder()
.compactionInterval(5)
.overlapSize(2)
.tokenThreshold(4000)
.eventRetentionSize(1000)
.summarizer(new LlmEventSummarizer(llm))
.build())
.build();For even more control, you can implement the interfaces BaseEventSummarizer and EventCompactor to completely customize the way events are summarized and compacted.
The LLM is the brain of your agent, but oftentimes it needs your approval to proceed further in its quest to reach its goal. There are many valid reasons for an agent to request your feedback, like accepting to execute a dangerous operation, or because there are certain actions that have to be validated by a person as demanded by laws, regulations, or simply the rules of your company processes.
The Human-in-the-Loop (HITL) workflow in ADK is built around the concept of ToolConfirmation. When a tool requires human intervention, it can pause the execution flow and ask the user for confirmation. Once the user provides the necessary approval (and optional payload data), the execution correctly resumes.
The process works as follows:
ToolContext and call requestConfirmation(). This automatically intercepts the run, pausing the LLM flow until input is received.ToolConfirmation (approval and optional payload), the ADK resumes the flow.Imagine we need a custom tool for handling user confirmation before an agent is allowed to take on any action, it may be implemented in that way:
@Schema(name = "request_confirmation")
public String requestConfirmation(
@Schema(name = "request_action",
description = "Description of the action to be confirmed or denied")
String actionRequest,
@Schema(name = "toolContext")
ToolContext toolContext) {
boolean isConfirmed = toolContext.toolConfirmation()
.map(ToolConfirmation::confirmed)
.orElse(false);
if (!isConfirmed) {
toolContext.requestConfirmation(
"Should I execute the following action? " + actionRequest, null);
return "Confirmation requested.";
}
return "The following action has been confirmed: " + actionRequest;
}Now let’s see what it looks like from the perspective of the agent definition, where I’m combining a GoogleSearchAgentTool with this confirmation tool, to allow a report agent to use the search tool to create a report:
LlmAgent assistant = LlmAgent.builder()
.name("helpful-report-assistant")
.description("A report assistant")
.instruction("""
You are a helpful and friendly report assistant.
You can use the `google_search_agent` tool to search the internet
in order to create detailed reports about user's requested topics.
Before taking any action, ask the user for confirmation first,
using the `request_confirmation` tool.
""")
.model("gemini-2.5-flash")
.tools(
// a Google Search agent tool
GoogleSearchAgentTool.create(
Gemini.builder().modelName("gemini-2.5-flash").build()),
// our newly created user confirmation tool
FunctionTool.create(this, "requestConfirmation", true)
)
.build();As you can see in the following screenshot of my exchange with the report assistant, it requested my confirmation before using the research agent to prepare a report:
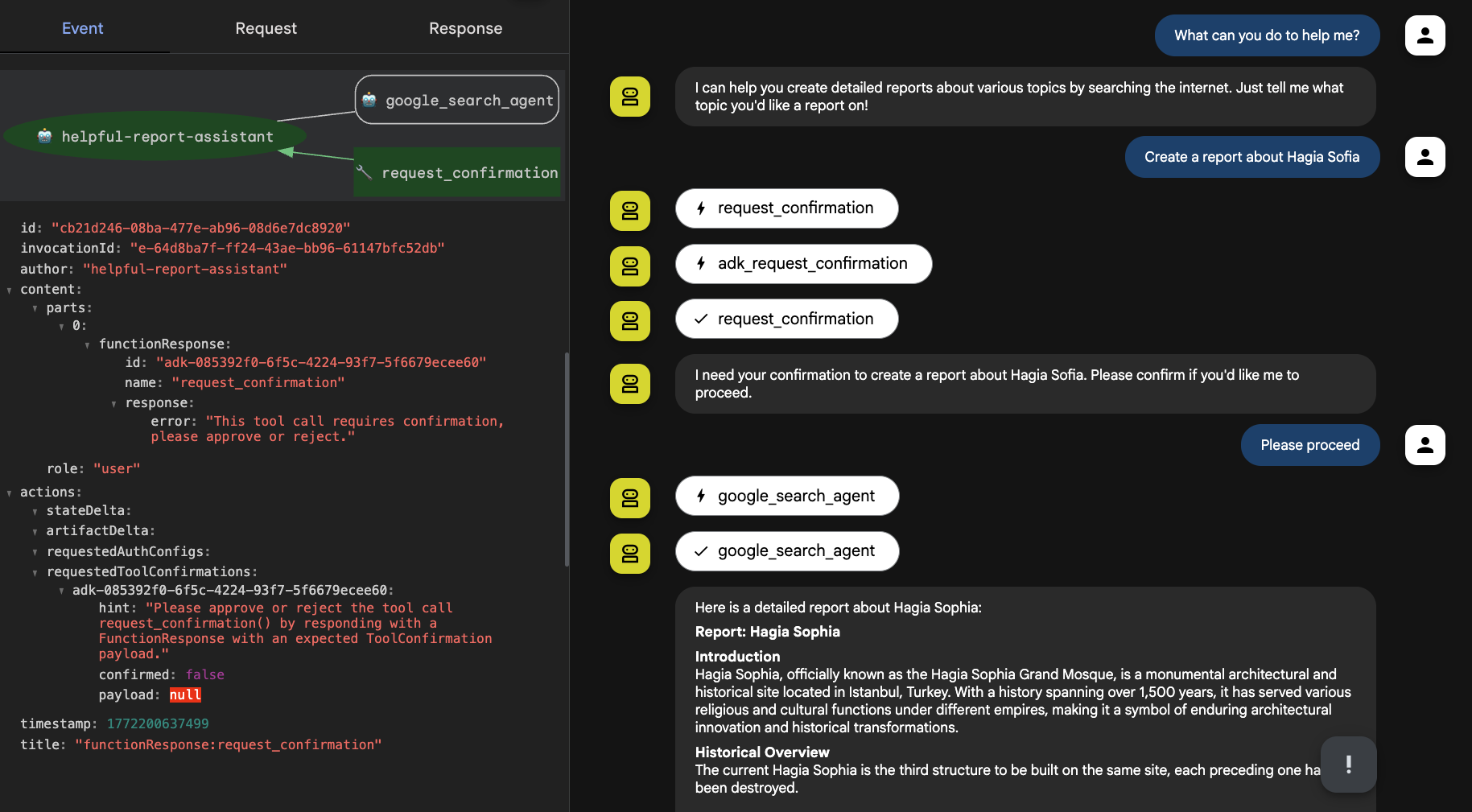
Agents may require your help, once in a while, for validation, clarification, and more. ADK now offers the ability to configure precisely how and when to interact with your friendly humans.
ADK defines clear contracts for managing state, history, and files across conversations.
In order to manage the lifecycle of a single conversation and its state, the session services below can be configured in your runner loop:
InMemorySessionService: Lightweight, in-memory, local development storage.VertexAiSessionService: Backed by Google Cloud's managed Vertex AI Session API.FirestoreSessionService: A robust, scalable implementation backed by Google Cloud Firestore (generously contributed by the community!)To give your agents long-term "conversational memory" across multiple sessions, the below services exist:
InMemoryMemoryService: Simple keyword matching for local tests.FirestoreMemoryService: Persistent memory utilizing Firestore.In terms of integration, simply attach the LoadMemoryTool to your agent, and it will automatically know how to query the configured Memory Service for historical context.
Beyond the conversation, your agents handle large data blobs (images, PDFs) shared during a session, with:
InMemoryArtifactService: Local, in-memory storage.GcsArtifactService: Persistent, versioned artifact management using Google Cloud Storage.Never miss details about the ongoing conversation, the key events from past sessions, and keep track of all the important files that have been exchanged.
ADK for Java now natively supports the official Agent2Agent (A2A) Protocol, allowing your ADK agents to seamlessly communicate with remote agents built in any language or framework.
The ADK has migrated to use the official A2A Java SDK Client. You can now resolve an AgentCard (the URL of the identity of the agent, representing its abilities and communication preferences) from a remote endpoint, construct the client, and wrap it in a RemoteA2AAgent. This remote agent can then be placed into your ADK agent hierarchy and acts exactly like a local agent, streaming events natively back to the Runner.
To expose your own ADK agents via the A2A Protocol, you create an A2A AgentExecutor. It wraps your ADK agents and exposes them via a JSON-RPC REST endpoint, instantly making your ADK creations accessible to the wider A2A ecosystem.
Your agents are now ready to interact with the world more broadly, to discover new agent friends along the way, to build an ecosystem of interoperable agents. You can check the documentation to learn more about A2A support in Java.
Today, with the release of ADK for Java v1.0.0, and with this article, we hope you had a glimpse of the feature highlights of this new version. We encourage you to explore all the new features in this release to enhance your agents. In upcoming articles and videos, we’ll go a little deeper in some of those topics, as there’s more to say.
Be sure to check out the official ADK documentation to continue on your learning journey, and in particular the getting started guide if you’re discovering ADK.
Your feedback is invaluable to us!
Happy agent building! With a cup of Java!


