

In February we announced Gemma, our family of lightweight, state-of-the-art open models built from the same research and technology used to create the Gemini models. The community's incredible response – including impressive fine-tuned variants, Kaggle notebooks, integration into tools and services, recipes for RAG using databases like MongoDB, and lots more – has been truly inspiring.
Today, we're excited to announce our first round of additions to the Gemma family, expanding the possibilities for ML developers to innovate responsibly: CodeGemma for code completion and generation tasks as well as instruction following, and RecurrentGemma, an efficiency-optimized architecture for research experimentation. Plus, we're sharing some updates to Gemma and our terms aimed at improvements based on invaluable feedback we've heard from the community and our partners.
Harnessing the foundation of our Gemma models, CodeGemma brings powerful yet lightweight coding capabilities to the community. CodeGemma models are available as a 7B pretrained variant that specializes in code completion and code generation tasks, a 7B instruction-tuned variant for code chat and instruction-following, and a 2B pretrained variant for fast code completion that fits on your local computer. CodeGemma models have several advantages:
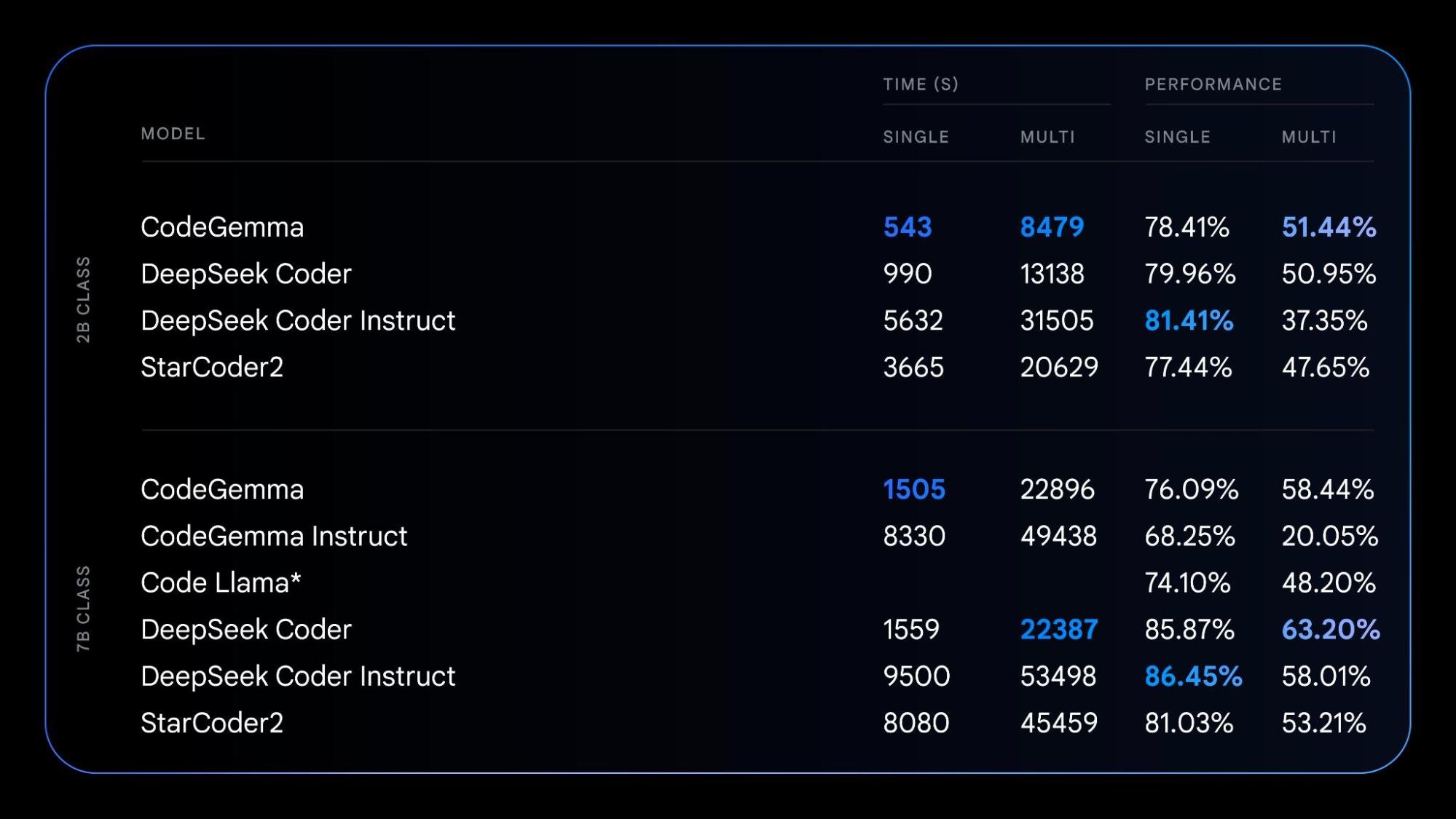
Learn more about CodeGemma in our report or try it in this quickstart guide.
RecurrentGemma is a technically distinct model that leverages recurrent neural networks and local attention to improve memory efficiency. While achieving similar benchmark score performance to the Gemma 2B model, RecurrentGemma's unique architecture results in several advantages:
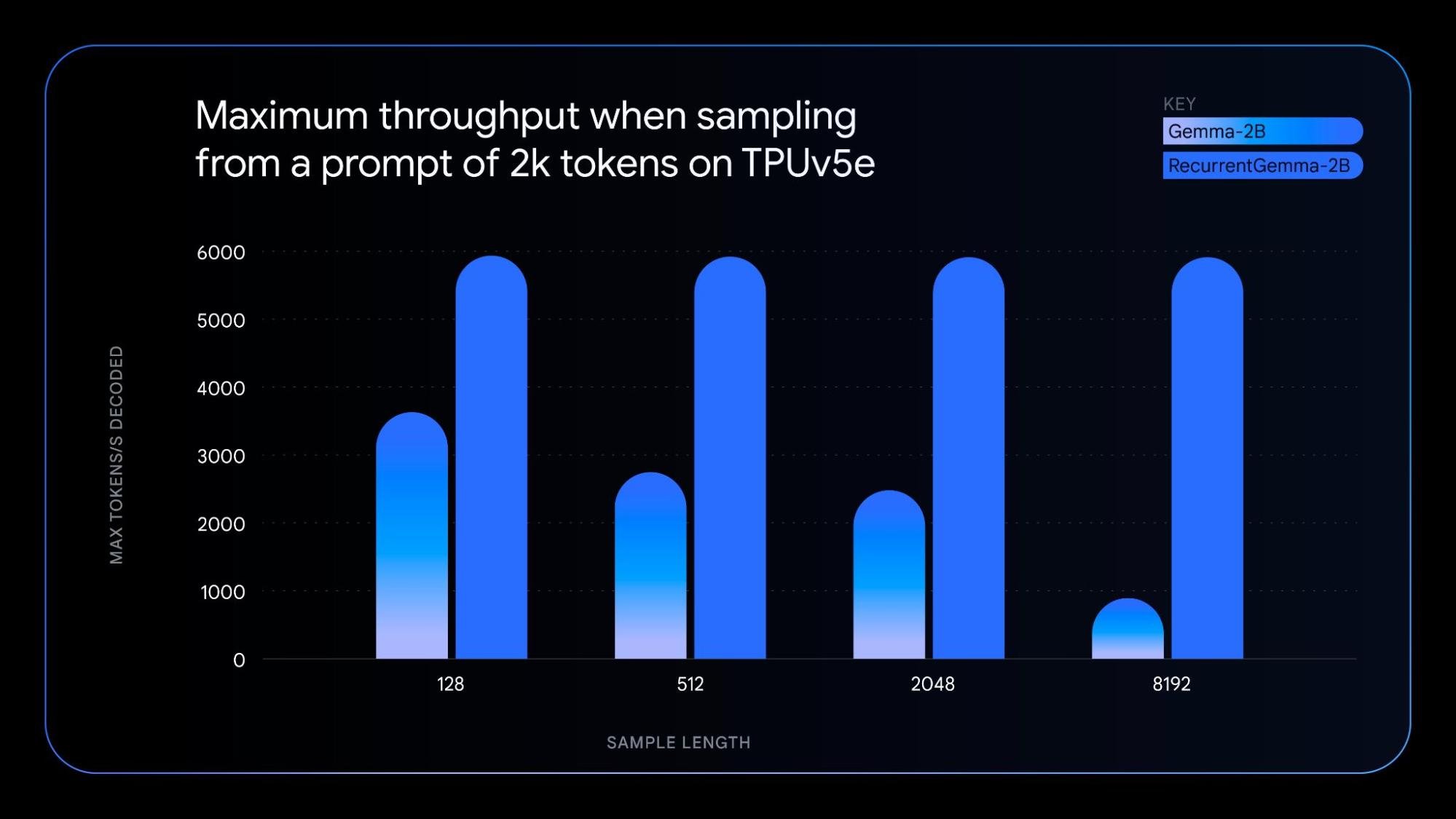
To understand the underlying technology, check out our paper. For practical exploration, try the notebook, which demonstrates how to fine-tune the model.
Guided by the same principles of the original Gemma models, the new model variants offer:
- Both CodeGemma and RecurrentGemma: Built with JAX and compatible with JAX, PyTorch, , Hugging Face Transformers, and Gemma.cpp. Enable local experimentation and cost-effective deployment across various hardware, including laptops, desktops, NVIDIA GPUs, and Google Cloud TPUs.
- CodeGemma: Additionally compatible with Keras, NVIDIA NeMo, TensorRT-LLM, Optimum-NVIDIA, MediaPipe, and availability on Vertex AI.
- RecurrentGemma: Support for all the aforementioned products will be available in the coming weeks.
Alongside the new model variants, we're releasing Gemma 1.1, which includes performance improvements. Additionally, we've listened to developer feedback, fixed bugs, and updated our terms to provide more flexibility.
These first Gemma model variants are available in various places worldwide, starting today on Kaggle, Hugging Face, and Vertex AI Model Garden. Here's how to get started:
We invite you to try the CodeGemma and RecurrentGemma models and share your feedback on Kaggle. Together, let's shape the future of AI-powered content creation and understanding.

Enable on-demand expertise with Agent Skills in Genkit Go

Run Ray on TPU, Part 2: Ray AI libraries

Agent and Model Evaluations in Gemini Enterprise Agent Platform are now GA

Turn creative prompts into interactive XR experiences with Gemini

How we built the Google I/O 2026 Save the Date experience