

TensorFlow Lite has been a powerful tool for on-device machine learning since its release in 2017, and MediaPipe further extended that power in 2019 by supporting complete ML pipelines. While these tools initially focused on smaller on-device models, today marks a dramatic shift with the experimental MediaPipe LLM Inference API.
This new release enables Large Language Models (LLMs) to run fully on-device across platforms. This new capability is particularly transformative considering the memory and compute demands of LLMs, which are over a hundred times larger than traditional on-device models. Optimizations across the on-device stack make this possible, including new ops, quantization, caching, and weight sharing.
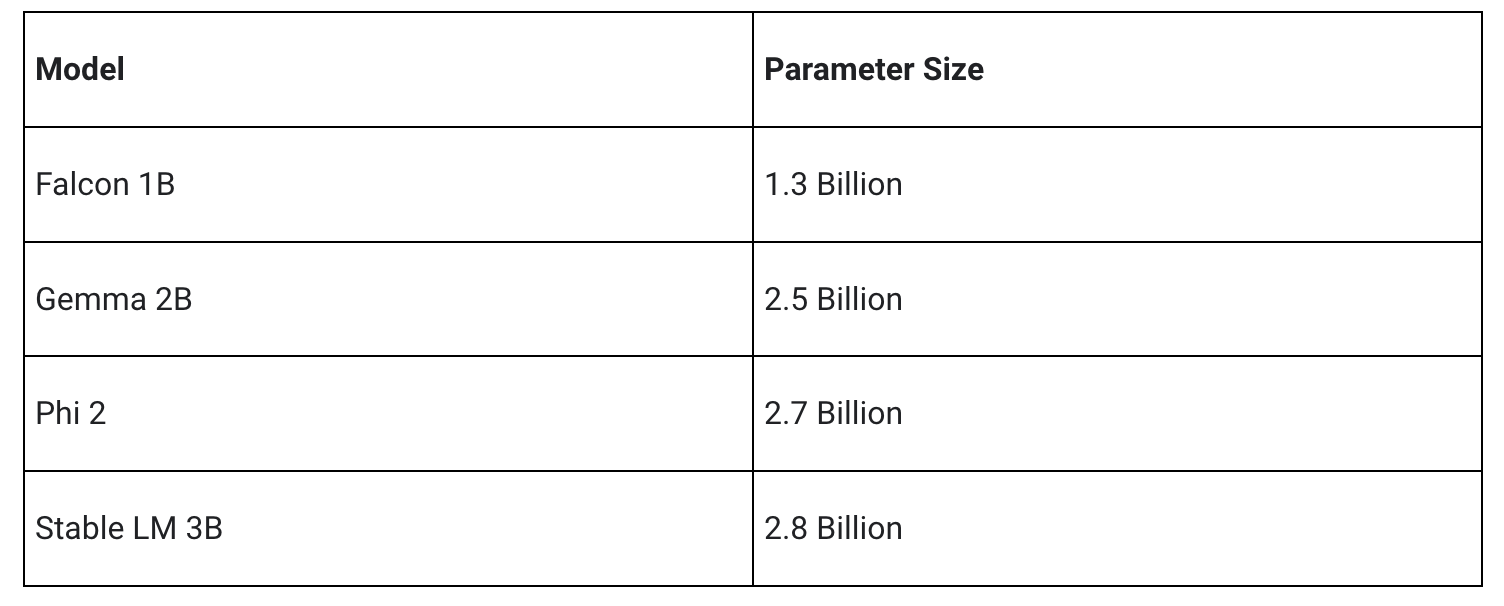
The experimental cross-platform MediaPipe LLM Inference API, designed to streamline on-device LLM integration for web developers, supports Web, Android, and iOS with initial support for four openly available LLMs: Gemma, Phi 2, Falcon, and Stable LM. It gives researchers and developers the flexibility to prototype and test popular openly available LLM models on-device.
On Android, the MediaPipe LLM Inference API is intended for experimental and research use only. Production applications with LLMs can use the Gemini API or Gemini Nano on-device through Android AICore. AICore is the new system-level capability introduced in Android 14 to provide Gemini-powered solutions for high-end devices, including integrations with the latest ML accelerators, use-case optimized LoRA adapters, and safety filters. To start using Gemini Nano on-device with your app, apply to the Early Access Preview.
Starting today, you can test out the MediaPipe LLM Inference API via our web demo or by building our sample demo apps. You can experiment and integrate it into your projects via our Web, Android, or iOS SDKs.
Using the LLM Inference API allows you to bring LLMs on-device in just a few steps. These steps apply across web, iOS, and Android, though the SDK and native API will be platform specific. The following code samples show the web SDK.
2. Convert the model weights into a TensorFlow Lite Flatbuffer using the MediaPipe Python Package
from mediapipe.tasks.python.genai import converter
config = converter.ConversionConfig(...)
converter.convert_checkpoint(config)3. Include the LLM Inference SDK in your application
import { FilesetResolver, LlmInference } from "https://cdn.jsdelivr.net/npm/@mediapipe/tasks-genai”4. Host the TensorFlow Lite Flatbuffer along with your application.
5. Use the LLM Inference API to take a text prompt and get a text response from your model
const fileset = await FilesetResolver.forGenAiTasks("https://cdn.jsdelivr.net/npm/@mediapipe/tasks-genai/wasm");
const llmInference = await LlmInference.createFromModelPath(fileset, “model.bin”);
const responseText = await llmInference.generateResponse("Hello, nice to meet you");
document.getElementById('output').textContent = responseText;Please see our documentation and code examples for a detailed walk through of each of these steps.
Here are real time gifs of Gemma 2B running via the MediaPipe LLM Inference API.
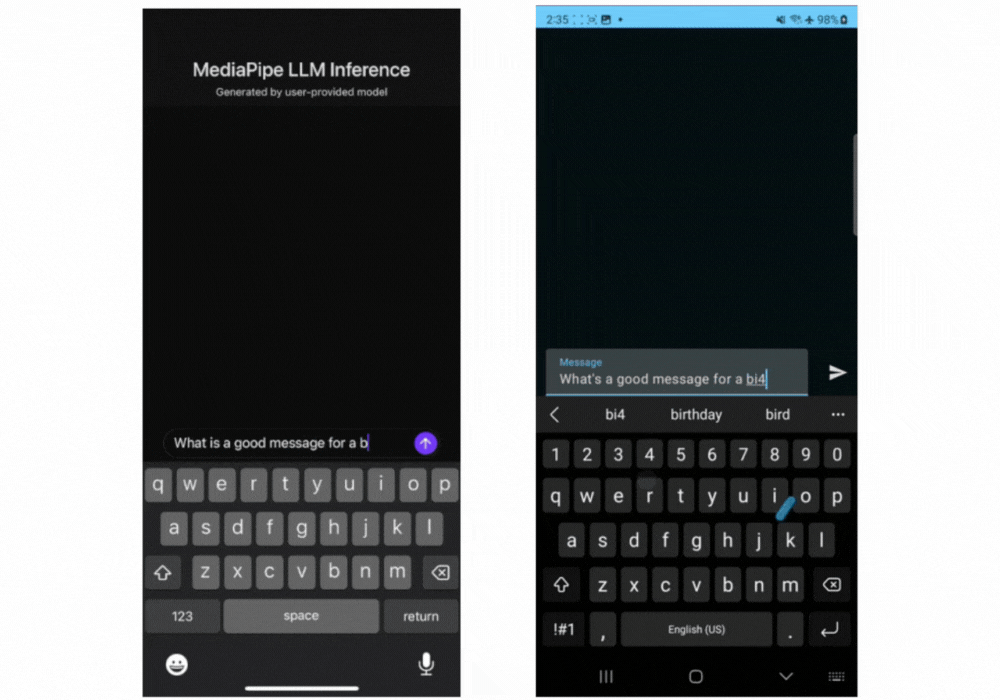
Our initial release supports the following four model architectures. Any model weights compatible with these architectures will work with the LLM Inference API. Use the base model weights, use a community fine-tuned version of the weights, or fine tune weights using your own data.
Through significant optimizations, some of which are detailed below, the MediaPipe LLM Inference API is able to deliver state-of-the-art latency on-device, focusing on CPU and GPU to support multiple platforms. For sustained performance in a production setting on select premium phones, Android AICore can take advantage of hardware-specific neural accelerators.
When measuring latency for an LLM, there are a few terms and measurements to consider. Time to First Token and Decode Speed will be the two most meaningful as these measure how quickly you get the start of your response and how quickly the response generates once it starts.
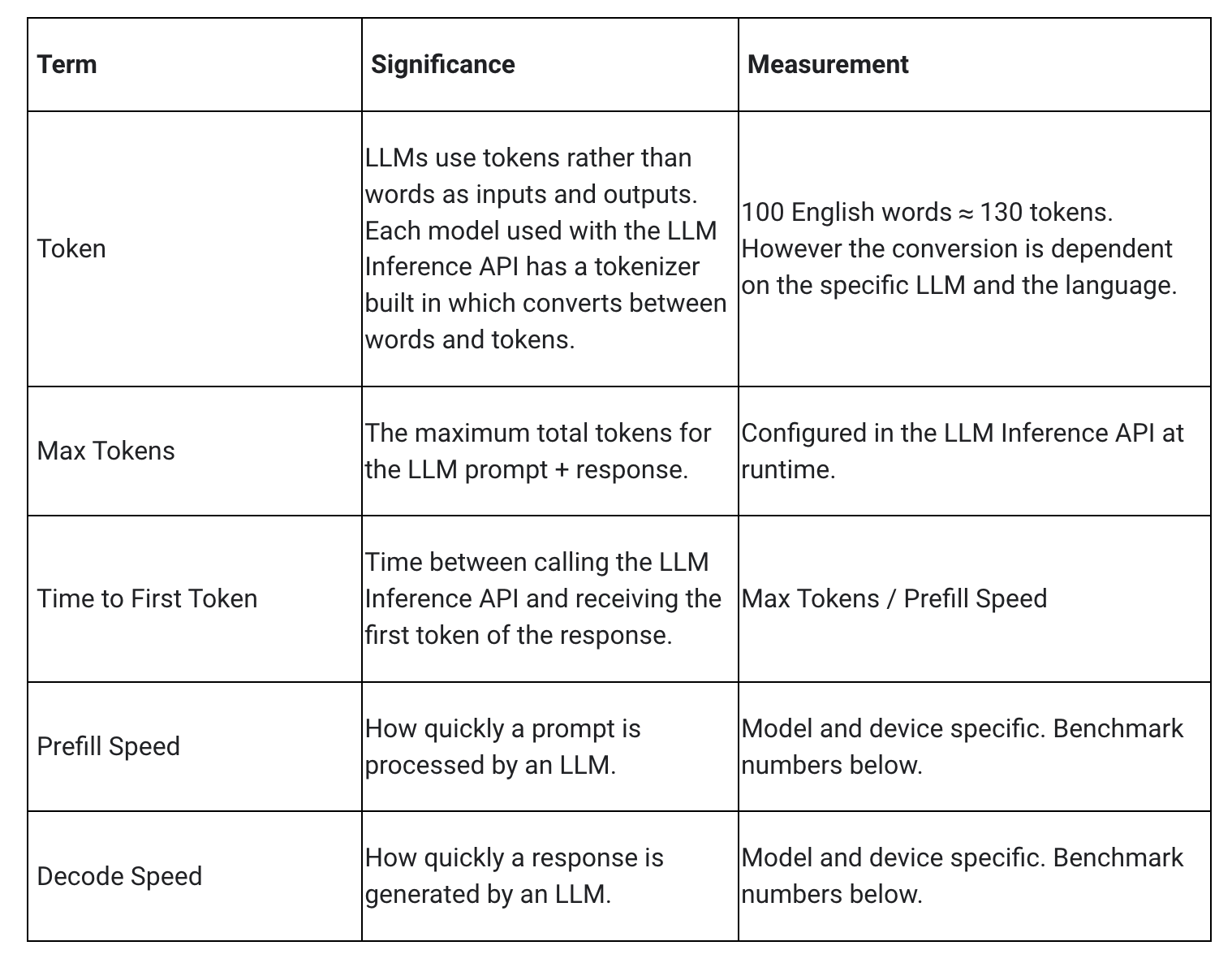
The Prefill Speed and Decode Speed are dependent on model, hardware, and max tokens. They can also change depending on the current load of the device.
The following speeds were taken on high end devices using a max tokens of 1280 tokens, an input prompt of 1024 tokens, and int8 weight quantization. The exception being Gemma 2B (int4), found here on Kaggle, which uses a mixed 4/8-bit weight quantization.
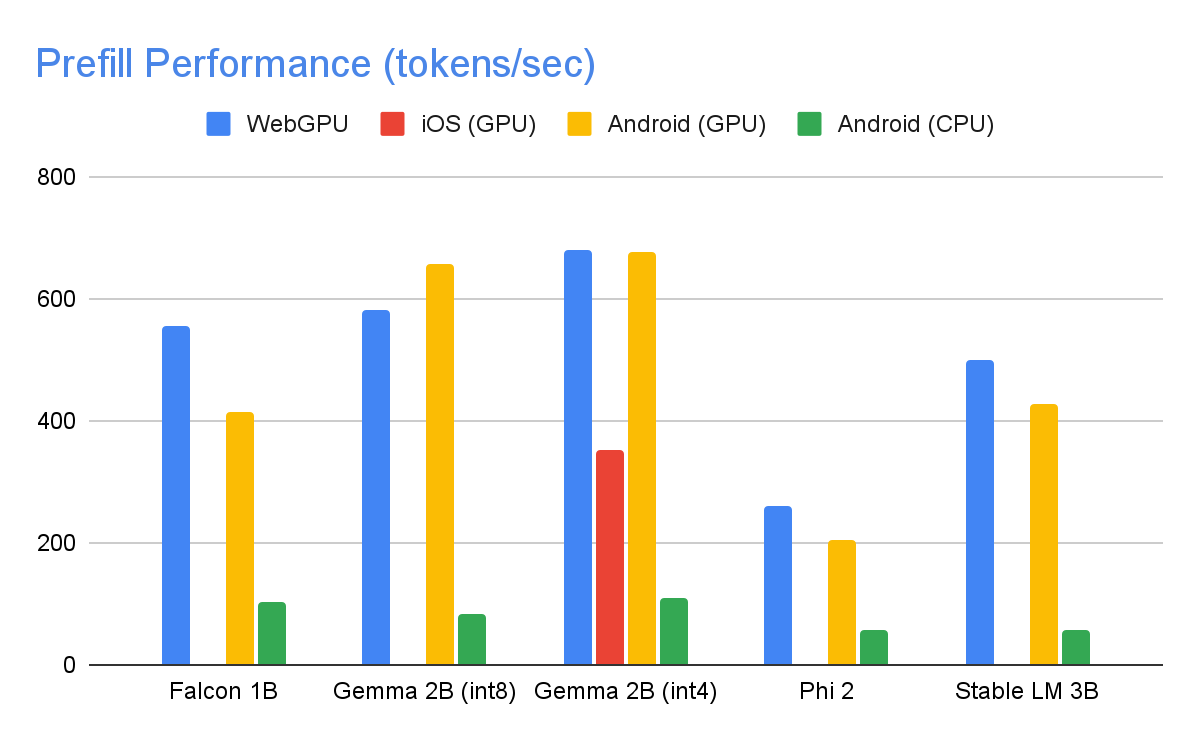
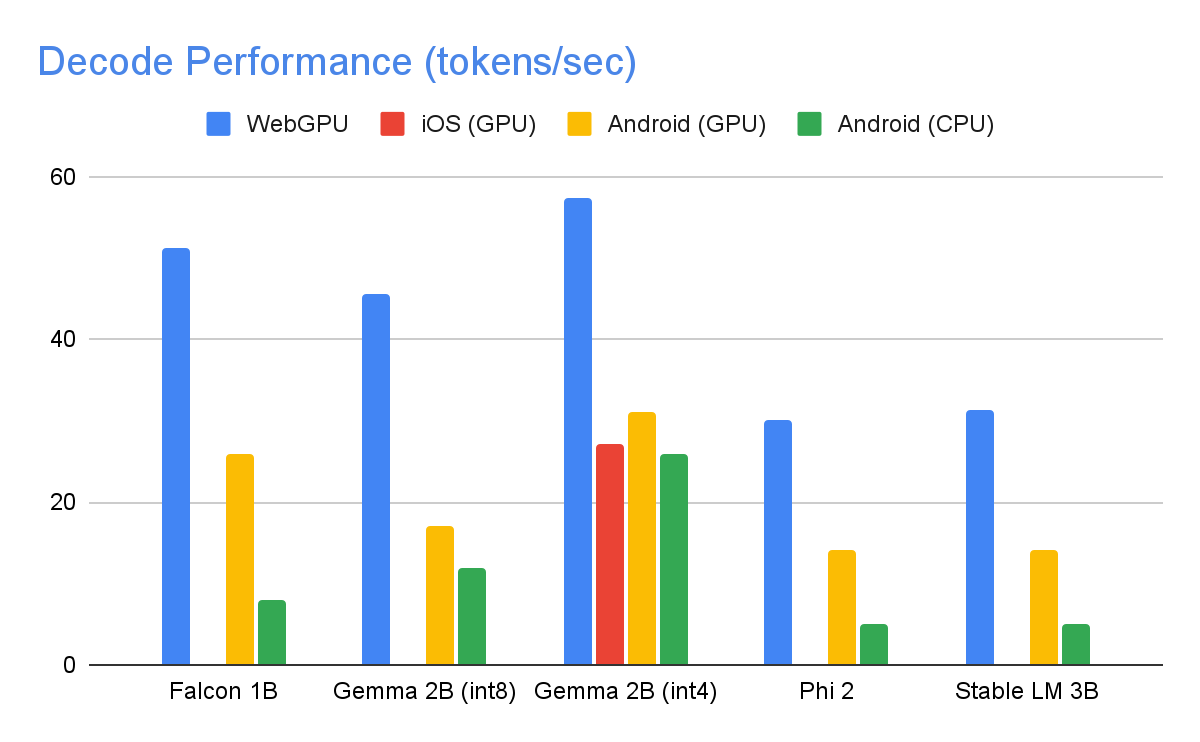
To achieve the performance numbers above, countless optimizations were made across MediaPipe, TensorFlow Lite, XNNPack (our CPU neural network operator library), and our GPU-accelerated runtime. The following are a select few that resulted in meaningful performance improvements.
Weights Sharing: The LLM inference process comprises 2 phases: a prefill phase and a decode phase. Traditionally, this setup would require 2 separate inference contexts, each independently managing resources for its corresponding ML model. Given the memory demands of LLMs, we've added a feature that allows sharing the weights and the KV cache across inference contexts. Although sharing weights might seem straightforward, it has significant performance implications when sharing between compute-bound and memory-bound operations. In typical ML inference scenarios, where weights are not shared with other operators, they are meticulously configured for each fully connected operator separately to ensure optimal performance. Sharing weights with another operator implies a loss of per-operator optimization and this mandates the authoring of new kernel implementations that can run efficiently even on sub-optimal weights.
Optimized Fully Connected Ops: XNNPack’s FULLY_CONNECTED operation has undergone two significant optimizations for LLM inference. First, dynamic range quantization seamlessly merges the computational and memory benefits of full integer quantization with the precision advantages of floating-point inference. The utilization of int8/int4 weights not only enhances memory throughput but also achieves remarkable performance, especially with the efficient, in-register decoding of 4-bit weights requiring only one additional instruction. Second, we actively leverage the I8MM instructions in ARM v9 CPUs which enable the multiplication of a 2x8 int8 matrix by an 8x2 int8 matrix in a single instruction, resulting in twice the speed of the NEON dot product-based implementation.
Balancing Compute and Memory: Upon profiling the LLM inference, we identified distinct limitations for both phases: the prefill phase faces restrictions imposed by the compute capacity, while the decode phase is constrained by memory bandwidth. Consequently, each phase employs different strategies for dequantization of the shared int8/int4 weights. In the prefill phase, each convolution operator first dequantizes the weights into floating-point values before the primary computation, ensuring optimal performance for computationally intensive convolutions. Conversely, the decode phase minimizes memory bandwidth by adding the dequantization computation to the main mathematical convolution operations.
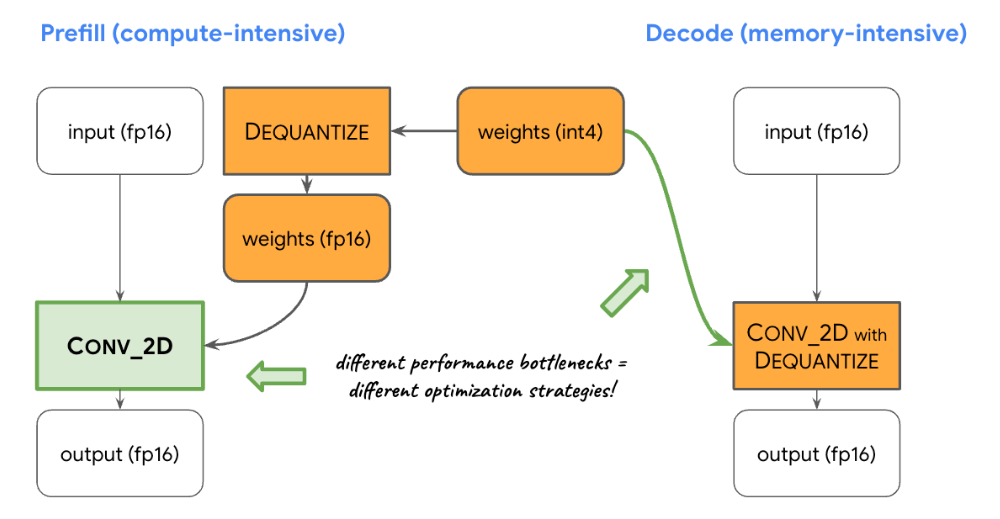
Custom Operators: For GPU-accelerated LLM inference on-device, we rely extensively on custom operations to mitigate the inefficiency caused by numerous small shaders. These custom ops allow for special operator fusions and various LLM parameters such as token ID, sequence patch size, sampling parameters, to be packed into a specialized custom tensor used mostly within these specialized operations.
Pseudo-Dynamism: In the attention block, we encounter dynamic operations that increase over time as the context grows. Since our GPU runtime lacks support for dynamic ops/tensors, we opt for fixed operations with a predefined maximum cache size. To reduce the computational complexity, we introduce a parameter enabling the skipping of certain value calculations or the processing of reduced data.
Optimized KV Cache Layout: Since the entries in the KV cache ultimately serve as weights for convolutions, employed in lieu of matrix multiplications, we store these in a specialized layout tailored for convolution weights. This strategic adjustment eliminates the necessity for extra conversions or reliance on unoptimized layouts, and therefore contributes to a more efficient and streamlined process.
We are thrilled with the optimizations and the performance in today’s experimental release of the MediaPipe LLM Inference API. This is just the start. Over 2024, we will expand to more platforms and models, offer broader conversion tools, complimentary on-device components, high level tasks, and more.
You can check out the official sample on GitHub demonstrating everything you’ve just learned about and read through our official documentation for even more details. Keep an eye on the Google for Developers YouTube channel for updates and tutorials.
We’d like to thank all team members who contributed to this work: T.J. Alumbaugh, Alek Andreev, Frank Ban, Jeanine Banks, Frank Barchard, Pulkit Bhuwalka, Buck Bourdon, Maxime Brénon, Chuo-Ling Chang, Lin Chen, Linkun Chen, Yu-hui Chen, Nikolai Chinaev, Clark Duvall, Rosário Fernandes, Mig Gerard, Matthias Grundmann, Ayush Gupta, Mohammadreza Heydary, Ekaterina Ignasheva, Ram Iyengar, Grant Jensen, Alex Kanaukou, Prianka Liz Kariat, Alan Kelly, Kathleen Kenealy, Ho Ko, Sachin Kotwani, Andrei Kulik, Yi-Chun Kuo, Khanh LeViet, Yang Lu, Lalit Singh Manral, Tyler Mullen, Karthik Raveendran, Raman Sarokin, Sebastian Schmidt, Kris Tonthat, Lu Wang, Zoe Wang, Tris Warkentin, Geng Yan, Tenghui Zhu, and the Gemma team.

