

TensorFlow Lite は 2017 年のリリース以来、オンデバイス機械学習のための強力なツールであり続けています。また、MediaPipe は 2019 年に完全な ML パイプラインをサポートし、その機能をさらに拡張しました。当初、これらのツールは、小さなオンデバイス モデルを対象としていました。しかし今回、試験運用版の MediaPipe LLM Inference API によって劇的な変化を遂げることになります。
今回の新しいリリースにより、プラットフォームを超えて大規模言語モデル(LLM)を完全にオンデバイスで実行できるようになります。LLM には従来のオンデバイス モデルの 100 倍以上のメモリと計算が必要になることを踏まえると、この新機能は特に大きな変化と言えます。これは、新しいオペレーション、量子化、キャッシュ、重みの共有など、オンデバイス スタック全体の最適化によって実現しています。
試験運用版のクロスプラットフォーム MediaPipe LLM Inference API は、ウェブ デベロッパーがオンデバイス LLM を効率的に組み込めるように設計されており、ウェブ、Android、iOS をサポートします。初期サポートされるのは、オープンに利用できる 4 つの LLM、すなわち Gemma、Phi 2、Falcon、Stable LM です。これにより、研究者やデベロッパーは、一般公開されている人気 LLM モデルのプロトタイプを柔軟に作成し、オンデバイスでテストできるようになります。
Android の MediaPipe LLM Inference API は、試験運用と研究的利用のみを目的としています。LLM を使う本番アプリケーションは、Gemini API または Android AICore から Gemini Nano オンデバイスを利用できます。AICore は、Gemini を利用したハイエンド デバイス向けのソリューションを提供するために Android 14 で導入された新しいシステムレベルの機能で、最新の ML アクセラレータ、ユースケースに最適化された LoRA アダプタ、セーフティ フィルタなどが組み込まれています。早期アクセス プレビューに申し込むと、アプリで Gemini Nano オンデバイスを使ってみることができます。
本日より、ウェブのデモを確認するか、サンプル デモアプリをビルドすることで、MediaPipe LLM Inference API をテストできるようになります。ウェブ、Android、iOS SDK を使うと、実際に試したり、プロジェクトに組み込んでみたりすることができます。
LLM Inference API を使うと、わずか数ステップでオンデバイス LLM を導入できます。ウェブ、iOS、Android で手順は同じですが、SDK とネイティブ API はプラットフォームによって異なります。次のコードサンプルは、ウェブ SDK のものです。
2. MediaPipe Python パッケージで、モデルの重みを TensorFlow Lite Flatbuffer に変換する
from mediapipe.tasks.python.genai import converter
config = converter.ConversionConfig(...)
converter.convert_checkpoint(config)3. アプリケーションに LLM Inference SDK を含める
import { FilesetResolver, LlmInference } from "https://cdn.jsdelivr.net/npm/@mediapipe/tasks-genai”4. アプリケーションと合わせて TensorFlow Lite Flatbuffer をホストする
5. LLM Inference API を使ってテキスト プロンプトを受け取り、モデルからテキスト応答を取得する
const fileset = await FilesetResolver.forGenAiTasks("https://cdn.jsdelivr.net/npm/@mediapipe/tasks-genai/wasm");
const llmInference = await LlmInference.createFromModelPath(fileset, “model.bin”);
const responseText = await llmInference.generateResponse("Hello, nice to meet you");
document.getElementById('output').textContent = responseText;
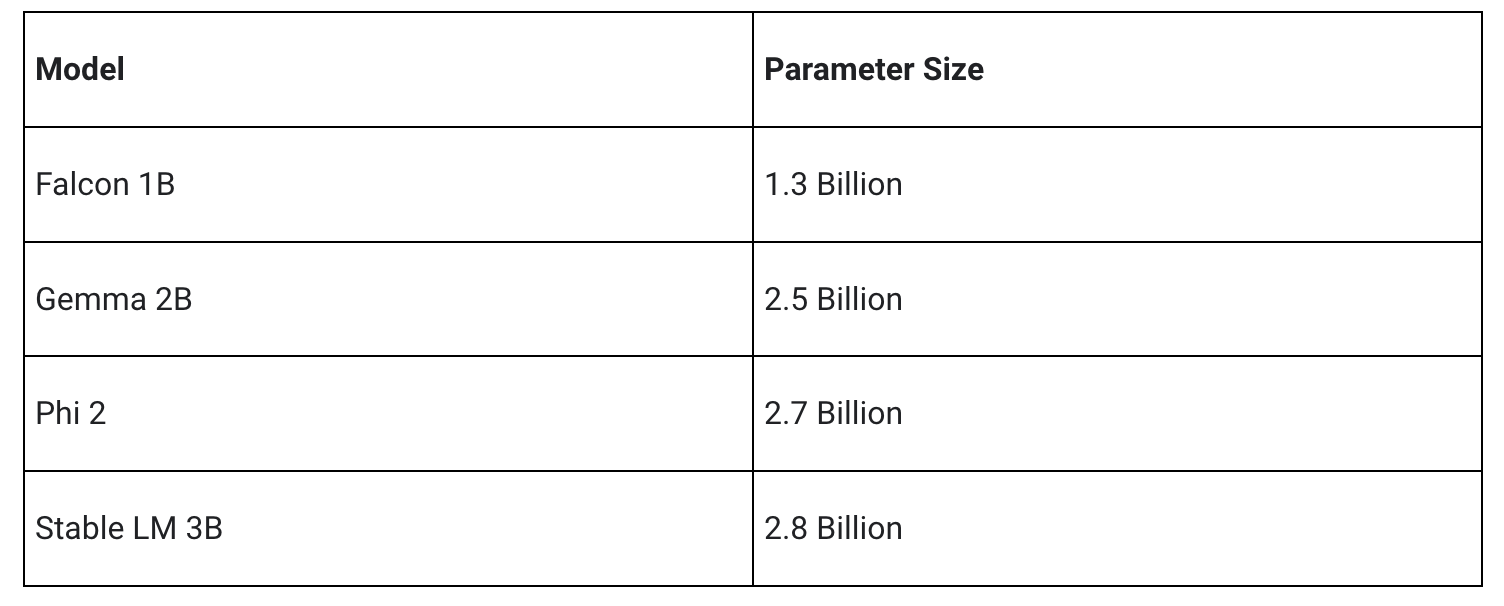
初回リリースでは、次の 4 つのモデル アーキテクチャをサポートします。LLM Inference API では、これらのアーキテクチャと互換性のある重みのモデルが動作します。基本モデルの重みを使うことも、コミュニティで微調整されたバージョンの重みを使うことも、独自データで重みを微調整することもできます。
一部について後ほど詳しく説明しますが、MediaPipe LLM Inference API では、大幅な最適化が行われており、CPU や GPU をはじめとする複数のプラットフォームをサポートしています。そのため、オンデバイスで最高水準のレイテンシを実現できます。一部のプレミアム スマートフォンでは、Android AICore でハードウェア固有のニューラル アクセラレータを活用し、実稼働環境の設定でパフォーマンスを持続できるようになっています。
LLM のレイテンシを測定するときには、いくつかの用語や測定値を考慮する必要があります。最初のトークンまでの時間(Time to First Token)とデコード速度(Decode Speed)の 2 つは、応答の開始速度と応答開始後の応答の生成速度を表すものなので、特に重要です。
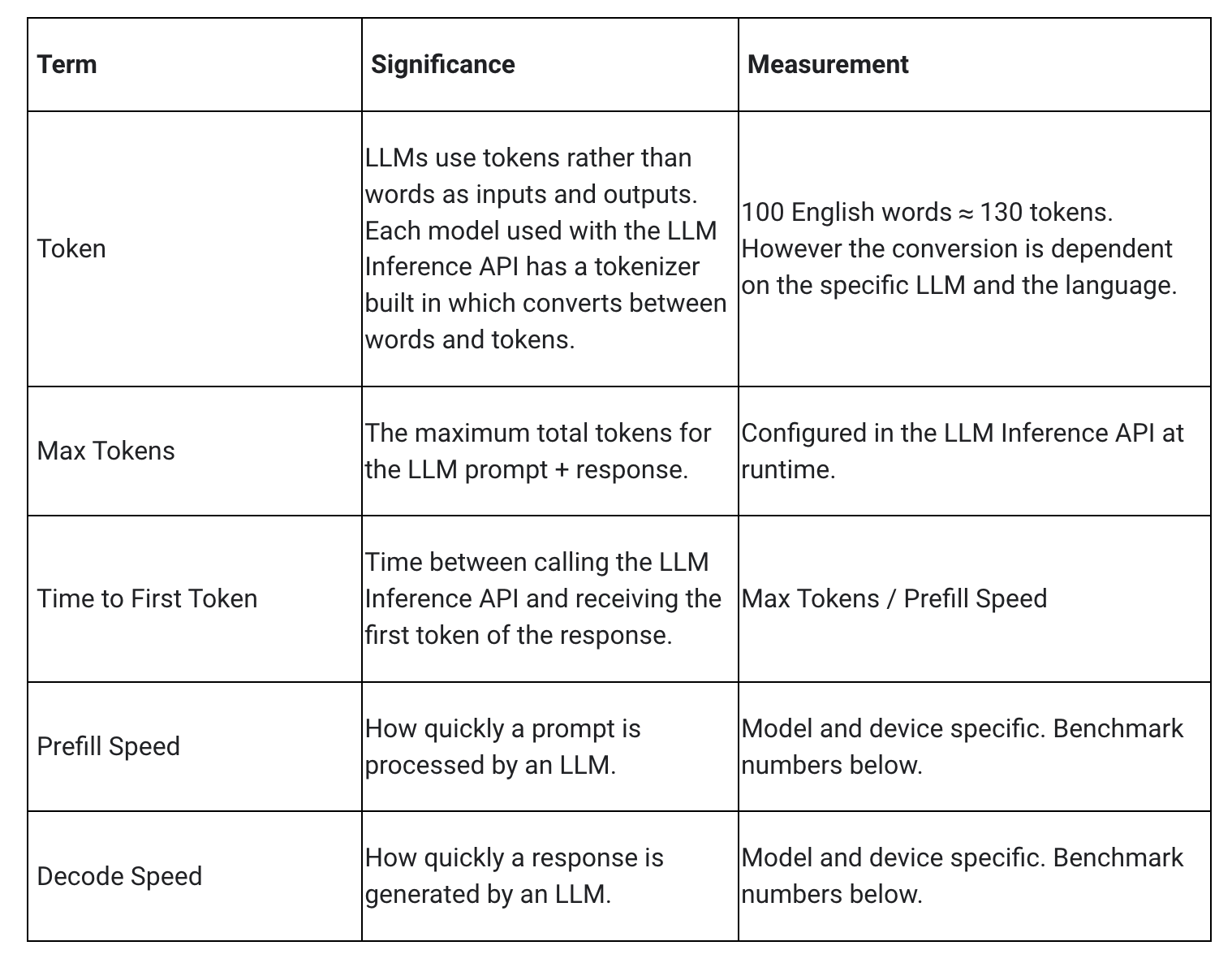
プレフィル速度(Prefill Speed)とデコード速度(Decode Speed)は、モデル、ハードウェア、最大トークン数によって異なります。また、デバイスの現在の負荷に応じて変化することもあります。
以下に示すのは、int8 重み量子化を利用し、最大トークン数が 1280、入力プロンプトのトークン数が 1024 の場合のハイエンド デバイスでの速度です。Gemma 2B (int4)は例外で、Kaggle で公開されているものを利用しています。これは、4 / 8 ビット混合重み量子化を使っています。
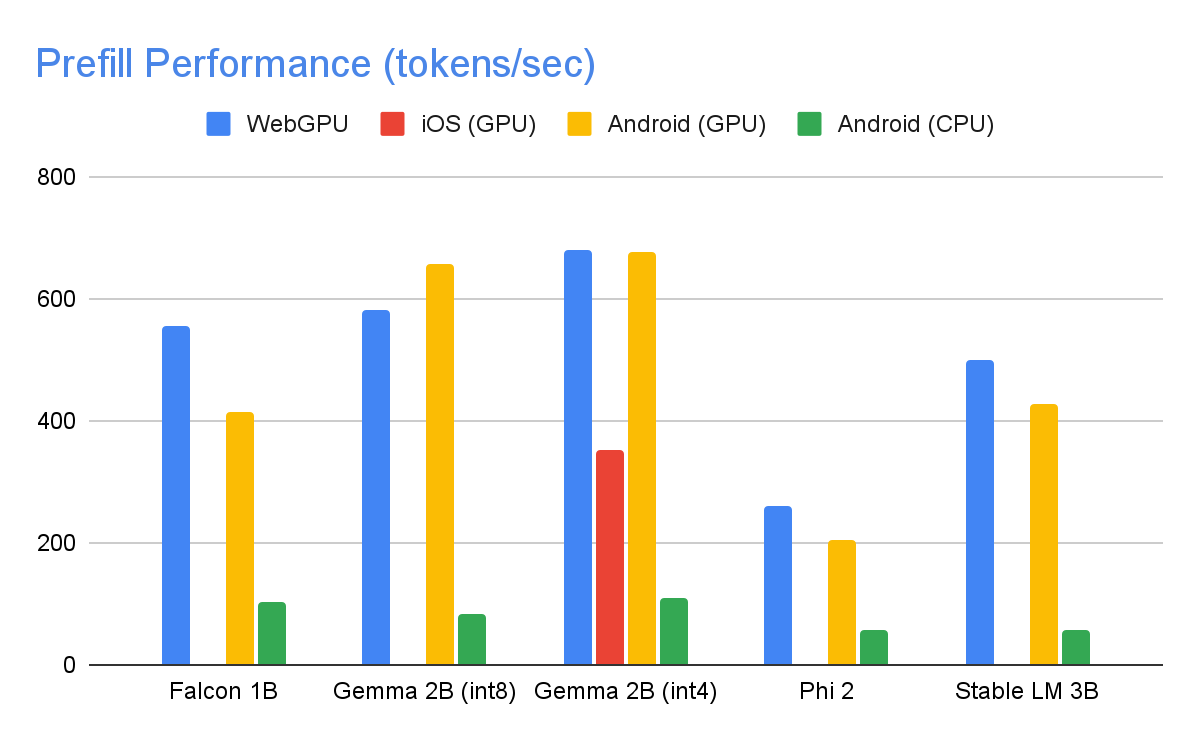
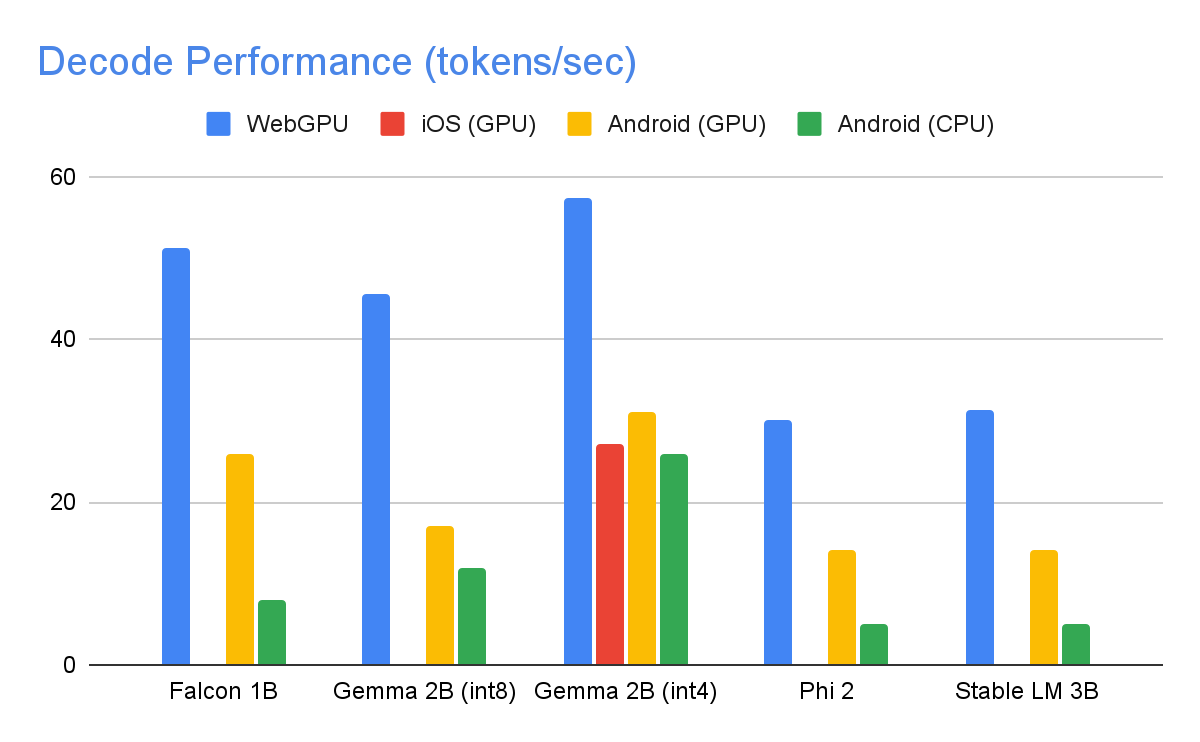
上記のパフォーマンス数値を達成するために、MediaPipe、TensorFlow Lite、XNNPack(Google の CPU ニューラル ネットワーク オペレータ ライブラリ)、GPU アクセラレーション ランタイムで、数え切れないほどの最適化を行いました。以下では、大きなパフォーマンスの向上につながったものをいくつか紹介します。
重みの共有: LLM 推論プロセスは、プレフィル フェーズとデコード フェーズの 2 つのフェーズで構成されます。従来、この設定では、2 つの別々の推論コンテキストで、対応する ML モデルのリソースを独立して管理する必要がありました。そこで、LLM のメモリ要件を考慮し、推論コンテキスト間で重みと KV キャッシュを共有できる機能を追加しました。重みの共有は簡単に思えるかもしれませんが、計算に制約があるオペレーションとメモリに制約があるオペレーションとの間で共有を行うと、パフォーマンスに大きな影響を与えます。一般的な ML 推論シナリオでは、重みは他の操作と共有されることはなく、全結合オペレータそれぞれに対して個別かつ綿密に設定され、最適なパフォーマンスを確保できるようになっています。別のオペレータと重みを共有すると、オペレータごとの最適化ができなくなります。そのため、最適でない重みでも効率的に実行できる新しいカーネル実装が必要になります。
全結合オペレーションの最適化: XNNPack の FULLY_CONNECTED オペレーションで、LLM 推論で重要になる 2 つの最適化を行っています。第一に、ダイナミック レンジ量子化によって、完全な整数量子化による計算上の利点とメモリ上の利点、そして浮動小数点推論の精度上の利点を、シームレスに融合させました。int8 / int4 の重みを利用することで、メモリのスループットが向上します。それだけでなく、特に、4 ビット重みは、1 つの追加命令だけで効率的にレジスタでデコードできるので、パフォーマンスが大幅に向上します。第二に、ARM v9 CPU の I8MM 命令を積極的に活用し、1 つの命令で 2x8 int8 行列と 8x2 int8 行列の乗算を行えるようにしました。これにより、NEON ドット積ベースの実装の 2 倍の速度を実現しています。
計算とメモリのバランス: LLM 推論をプロファイリングしたところ、プレフィルとデコードの両方のフェーズに、明確な制約があることがわかりました。プレフィル フェーズは計算能力による制約、デコード フェーズはメモリ帯域幅による制約を受けます。そのため、共有された int8 / int4 重みを逆量子化する際に、それぞれのフェーズで異なる戦略を採用します。プレフィル フェーズでは、計算量の多い畳み込みで最適なパフォーマンスが得られるように、各畳み込みオペレータで一次計算の前に重みを浮動小数点値に逆量子化します。逆に、デコード フェーズでは、主要な畳み込み計算オペレーションに逆量子化計算を追加することによって、メモリ帯域幅を最小化します。
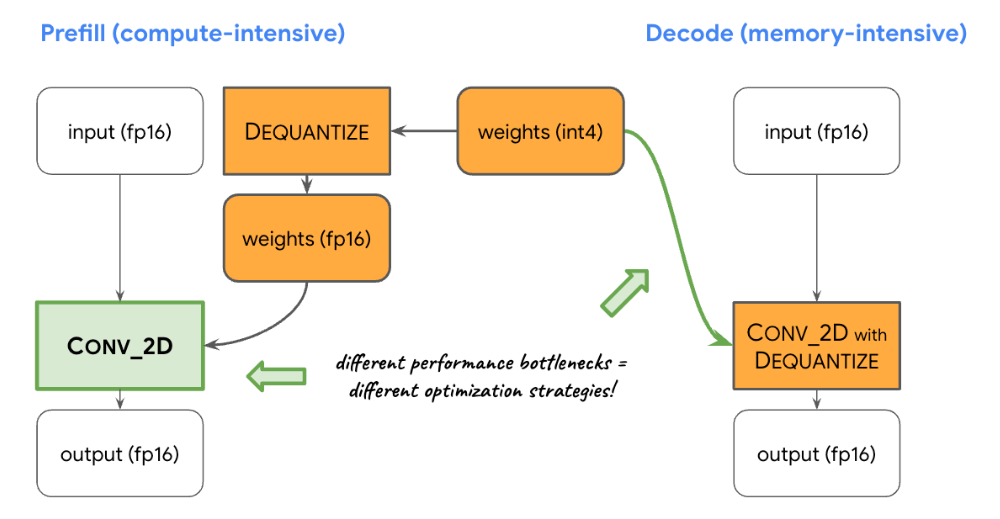
カスタム オペレータ: GPU アクセラレーションを使ってオンデバイス LLM 推論を行う場合、カスタム オペレーションを多用して、大量の小さなシェーダーを使うことによる非効率性を軽減しています。このカスタム オペレーションで、特殊なオペレータを融合します。また、トークン ID、シーケンス パッチサイズ、サンプリング パラメータなどのさまざまな LLM パラメータを特殊なカスタム テンソルにまとめ、主に特殊なオペレーション内で利用します。
疑似ダイナミズム: アテンション ブロックでは、コンテキストが大きくなるにつれて、時間の経過とともに動的なオペレーションが増加します。GPU ランタイムでは、動的なオペレーションやテンソルがサポートされていないため、最大キャッシュ サイズがあらかじめ定義されている固定のオペレーションを使います。そのため、特定の値の計算をスキップしたり、縮小したデータを処理したりできるようにするパラメータを導入し、複雑な計算を軽減します。
KV キャッシュ レイアウトの最適化: KV キャッシュのエントリは、最終的に行列乗算の代わりに利用する畳み込みの重みとして動作するので、畳み込みの重みに合わせた特別なレイアウトで保存します。この戦略的な調整により、追加の変換を行ったり、最適化されていないレイアウトを使ったりする必要がなくなるため、プロセスを効率化できます。
本日の MediaPipe LLM Inference API の試験運用版リリースで行った最適化とパフォーマンスは、刺激的なものです。これはほんの始まりに過ぎません。2024 年を通して、さらに多くのプラットフォームやモデルに拡大し、さまざまな変換ツール、オンデバイス補完コンポーネント、高レベルのタスクなどを提供する予定です。
ここで説明したすべてのことは、GitHub の公式サンプルで確認できます。さらに詳しく知りたい方は、公式ドキュメントをお読みください。最新情報やチュートリアルは、Google for Developers YouTube チャンネルでご覧いただけます。
今回の作業に協力いただいたすべてのチームメンバー、T.J. Alumbaugh、Alek Andreev、Frank Ban、Jeanine Banks、Frank Barchard、Pulkit Bhuwalka、Buck Bourdon、Maxime Brénon、Chuo-Ling Chang、Lin Chen、Linkun Chen、Yu-hui Chen、Nikolai Chinaev、Clark Duvall、Rosário Fernandes、Mig Gerard、Matthias Grundmann、Ayush Gupta、Mohammadreza Heydary、Ekaterina Ignasheva、Ram Iyengar、Grant Jensen、Alex Kanaukou、Prianka Liz Kariat、Alan Kelly、Kathleen Kenealy、Ho Ko、Sachin Kotwani、Andrei Kulik、Yi-Chun Kuo、Khanh LeViet、Yang Lu、Lalit Singh Manral、Tyler Mullen、Karthik Raveendran、Raman Sarokin、Sebastian Schmidt、Kris Tonthat、Lu Wang、Zoe Wang、Tris Warkentin、Geng Yan、Tenghui Zhu、そして Gemma チームに感謝いたします。