

TensorFlow Lite는 2017년 출시 이후 온디바이스 머신러닝을 위한 강력한 도구로 자리매김했으며, MediaPipe는 2019년에 완전한 ML 파이프라인을 지원함으로써 그 영향력을 더욱 확대했습니다. 이러한 도구들은 초기에는 소형 온디바이스 모델에 초점을 두었으나 현재는 실험용 MediaPipe LLM Inference API로 극적인 변화를 불러왔습니다.
이 새로운 릴리스를 통해 대규모 언어 모델(LLM)이 여러 플랫폼에서 온전히 온디바이스 모델로 작동할 수 있습니다. 기존의 온디바이스 모델보다 100배 이상 큰 LLM의 메모리 및 컴퓨팅 수요를 고려할 때 이 새로운 기능은 특히 더 혁신적입니다. 온디바이스 스택 전반에 걸친 최적화를 통해 새로운 운영, 양자화, 캐싱, 가중치 공유 등의 혁신을 이루어 냅니다.
웹 개발자를 위한 온디바이스 LLM 통합을 간소화하기 위해 설계된 실험용 크로스 플랫폼 MediaPipe LLM Inference API는 Gemma, Phi 2, Falcon, Stable LM의 네 가지 공개 LLM에 대한 초기 지원으로 Web, Android, iOS를 지원합니다. 이 API는 연구자와 개발자가 온디바이스에서 공개적으로 제공되는 인기 LLM 모델을 프로토타입으로 만들고 테스트할 수 있는 유연성을 제공합니다.
Android에서 MediaPipe LLM Inference API는 실험 및 연구용으로만 사용됩니다. LLM을 사용하는 Production 애플리케이션은 Gemini API 또는 Android AICore를 통해 온디바이스에서 Gemini Nano를 사용할 수 있습니다. AICore는 최신 ML 가속기, 사용 사례에 최적화된 LoRA 어댑터, 안전 필터와의 통합 등 하이엔드 기기를 위한 Gemini 기반 솔루션을 제공하기 위해 Android 14에 도입된 새로운 시스템 수준 기능입니다. 앱과 함께 온디바이스에서 Gemini Nano를 사용하려면 사전 체험판 미리보기를 신청하세요.
오늘부터 웹 데모를 통해 또는 샘플 데모 앱을 개발하여 MediaPipe LLM Inference API를 테스트할 수 있습니다. Web, Android 또는 iOS SDK를 통해 이 API를 실험하고 여러분의 프로젝트에 통합할 수 있습니다.
LLM Inference API를 사용하면 불과 몇 단계만에 LLM을 온디바이스로 가져올 수 있습니다. 이러한 단계는 웹, iOS, Android에 다 적용되지만 SDK와 네이티브 API는 플랫폼별로 다릅니다. 다음 코드 샘플이 웹 SDK를 보여줍니다.
2. MediaPipe Python Package를 사용하여 모델 가중치를 TensorFlow Lite Flatbuffer로 변환합니다.
from mediapipe.tasks.python.genai import converter
config = converter.ConversionConfig(...)
converter.convert_checkpoint(config)3. 애플리케이션에 LLM Inference SDK를 포함합니다.
import { FilesetResolver, LlmInference } from "https://cdn.jsdelivr.net/npm/@mediapipe/tasks-genai”4. 애플리케이션과 함께 TensorFlow Lite Flatbuffer를 호스팅합니다.
5. LLM Inference API를 사용하여 텍스트 프롬프트를 받고 모델에서 텍스트 응답을 받습니다.
const fileset = await FilesetResolver.forGenAiTasks("https://cdn.jsdelivr.net/npm/@mediapipe/tasks-genai/wasm");
const llmInference = await LlmInference.createFromModelPath(fileset, “model.bin”);
const responseText = await llmInference.generateResponse("Hello, nice to meet you");
document.getElementById('output').textContent = responseText;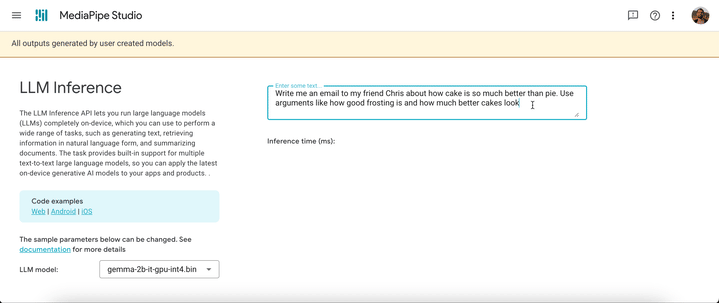
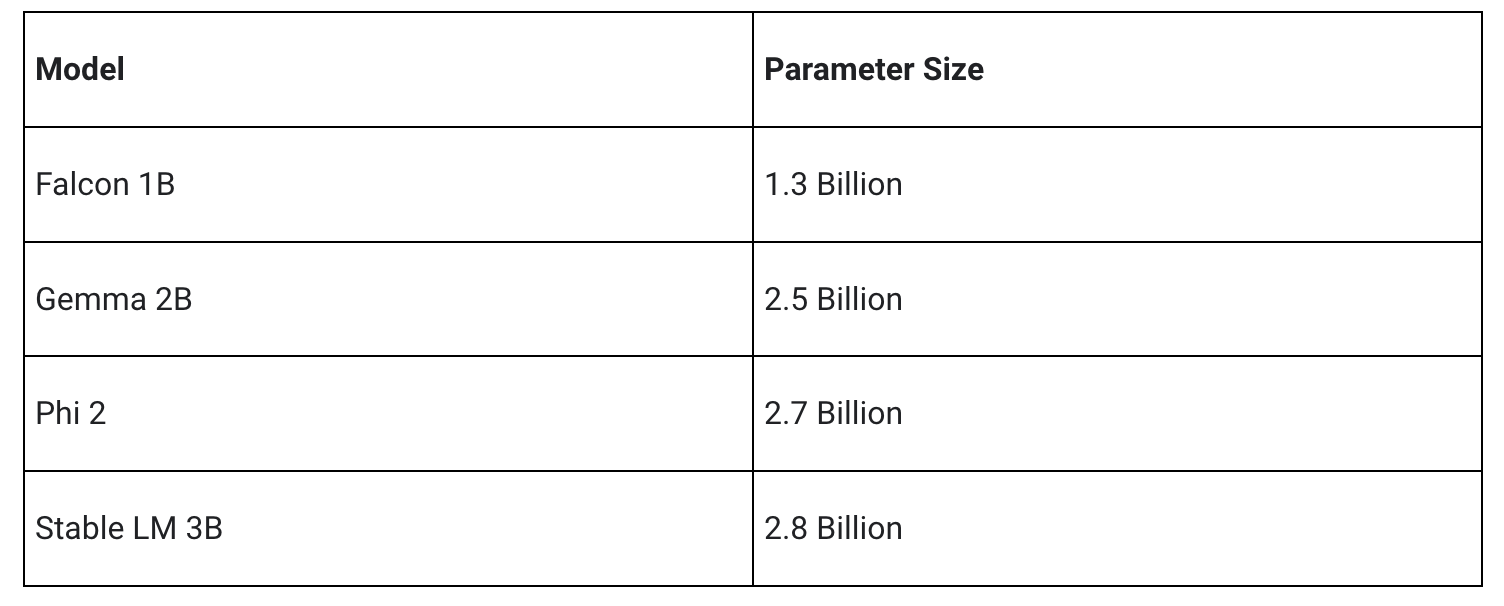
저희의 초기 릴리스는 다음 네 가지 모델 아키텍처를 지원합니다. 이러한 아키텍처와 호환되는 모든 모델 가중치는 LLM Inference API에서 작동합니다. 기본 모델 가중치를 사용하거나, 커뮤니티에서 미세 조정된 버전의 가중치를 사용하거나, 혹은 자체 데이터를 사용하여 가중치를 미세 조정하세요.
아래에 일부 상세히 설명된 중요한 최적화를 통해 MediaPipe LLM Inference API는 여러 플랫폼을 지원하기 위해 CPU와 GPU에 중점을 두고 최첨단 지연 온디바이스를 제공할 수 있습니다. 일부 프리미엄 스마트폰의 프로덕션 환경에서 지속적인 성능을 위해 Android AICore는 하드웨어별 신경 가속기를 활용할 수 있습니다.
LLM의 지연 시간을 측정할 때 고려해야 할 몇 가지 용어와 측정치가 있습니다. 얼마나 빨리 응답을 시작하는지와 응답이 시작된 후 얼마나 빨리 생성되는지를 측정하는 첫 번째 토큰까지의 시간과 디코딩 속도, 이 두 가지가 가장 의미 있는 수치가 될 것입니다.
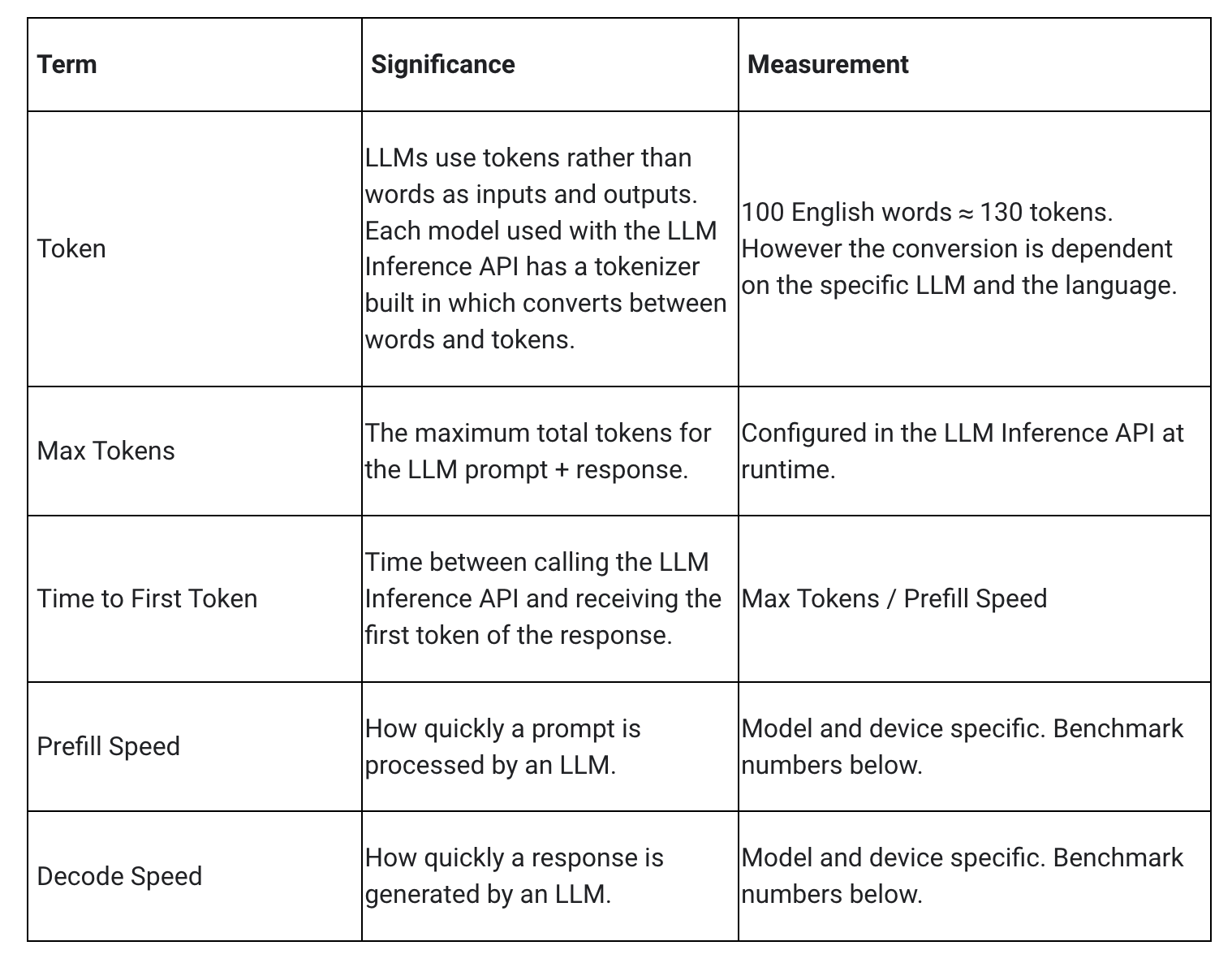
프리필 속도와 디코딩 속도는 모델, 하드웨어, 최대 토큰 수에 따라 다릅니다. 또한 기기의 현재 부하에 따라 달라질 수도 있습니다.
1,280개의 최대 토큰과 1,024개 토큰의 입력 프롬프트, int8 가중치 양자화를 사용하여 하이엔드 기기에서 다음과 같은 속도가 나왔습니다. 예외는 혼합된 4/8비트 가중치 양자화를 사용하는 Kaggle에서 보이는 Gemma 2B(int4)입니다.
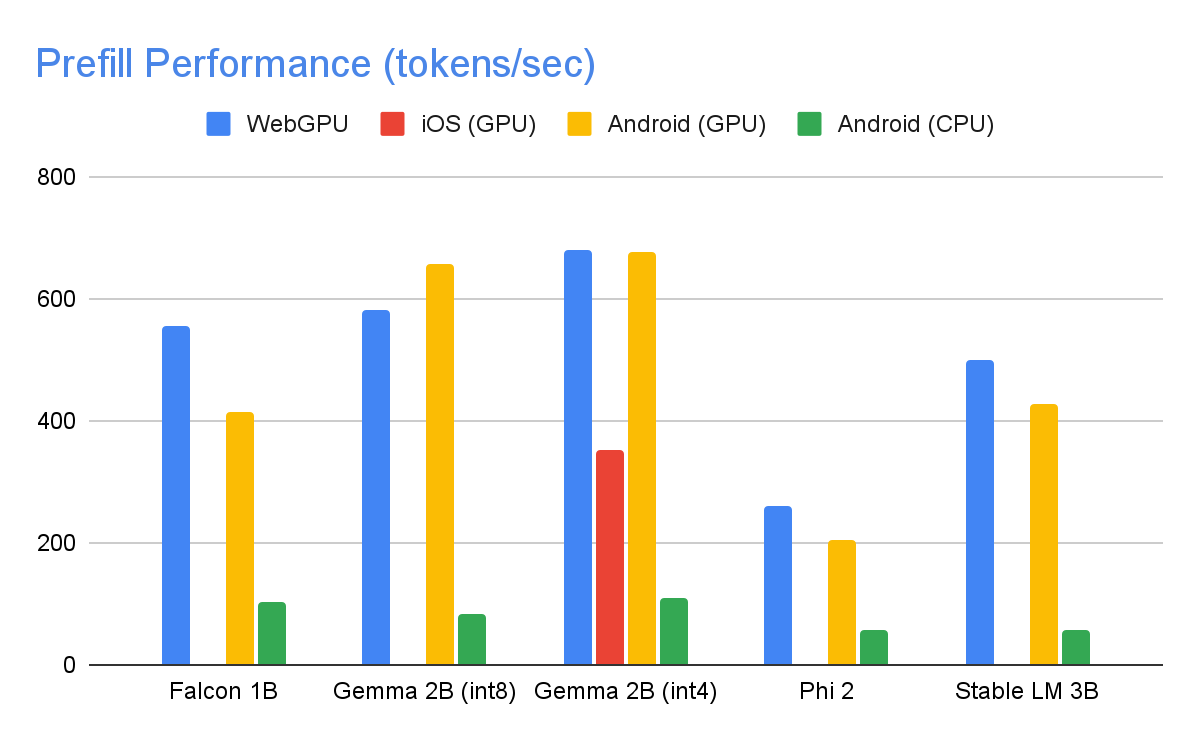
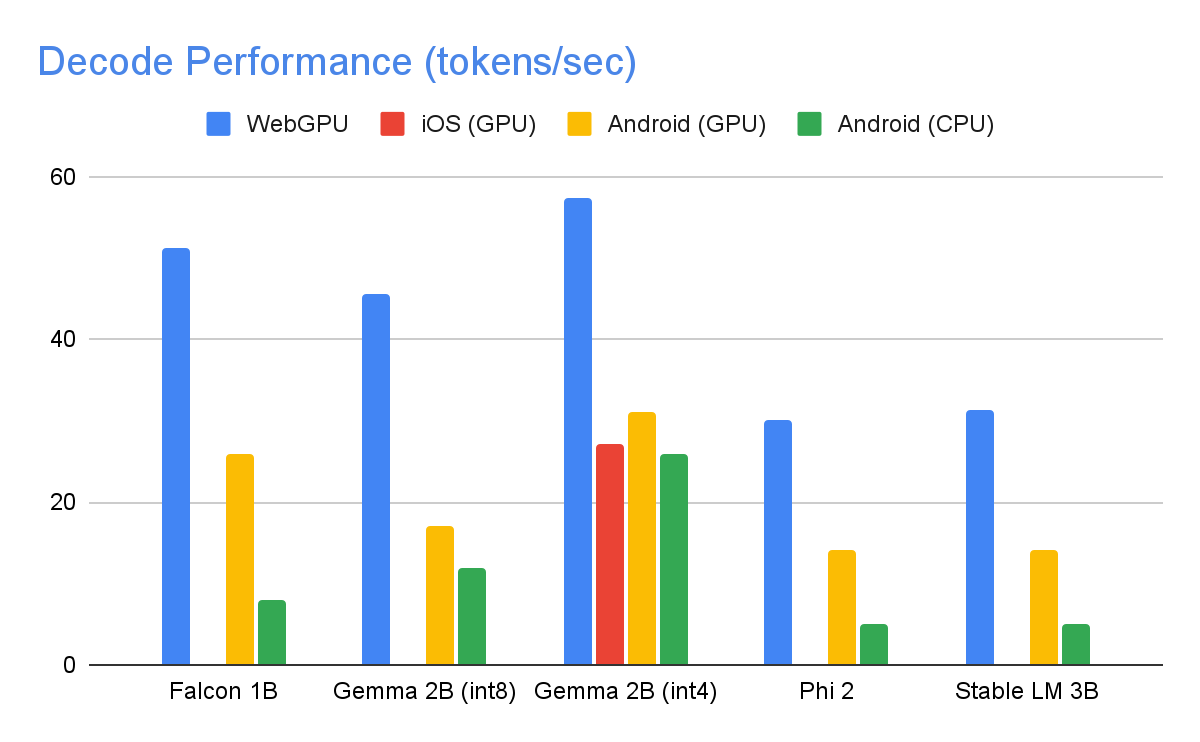
위의 성능 수치를 달성하기 위해 MediaPipe와 TensorFlow Lite, XNNPack(CPU 신경망 연산자 라이브러리), GPU 가속 런타임 전반에서 수많은 최적화가 이루어졌습니다. 다음은 의미 있는 성능 향상을 보여준 몇 가지 사례입니다.
가중치 공유: LLM 추론 프로세스는 프리필 단계와 디코딩 단계라는 두 단계로 구성됩니다. 전통적으로 이 설정에는 2가지 개별 추론 컨텍스트가 필요한데, 각 컨텍스트는 해당 ML 모델에 대한 리소스를 독립적으로 관리합니다. LLM의 메모리 수요를 고려하여 추론 컨텍스트에서 가중치와 KV 캐시를 공유할 수 있는 기능을 추가했습니다. 가중치 공유는 간단해 보일 수 있지만, 컴퓨팅 바인딩 연산과 메모리 바인딩 연산 간 공유 시 성능에 상당한 영향을 미칩니다. 가중치가 다른 연산자와 공유되지 않는 일반적인 ML 추론 시나리오에서는 최적의 성능을 보장하기 위해 완전히 연결된 각 연산자에 대해 별도로 꼼꼼하게 구성됩니다. 다른 연산자와 가중치를 공유하는 것은 연산자별 최적화의 손실을 의미합니다. 따라서 차선의 가중치에서도 효율적으로 실행할 수 있는 새 커널 구현을 반드시 작성해야 합니다.
최적화된 완전 연결 연산: XNNPack의 FULLY_CONNECTED 연산은 LLM 추론을 위해 두 가지 중요한 최적화를 거쳤습니다. 첫째, 동적 범위 양자화는 완전한 정수 양자화의 계산 및 메모리 이점과 부동 소수점 추론의 정밀도 이점을 원활하게 병합합니다. int8/int4 가중치를 활용하면 메모리 처리량이 향상될 뿐 아니라 특히 하나의 추가 명령만 필요한 4비트 가중치의 효율적인 레지스터 내 디코딩으로 놀라운 성능을 달성할 수 있습니다. 둘째, ARM v9 CPU의 I8MM 명령을 적극적으로 활용하여 단일 명령에서 2x8 int8 행렬과 8x2 int8 행렬을 곱할 수 있으므로 NEON 내적(dot product) 기반 구현의 속도가 두 배로 빨라집니다.
컴퓨팅과 메모리의 밸런싱: LLM 추론을 프로파일링 해 보니 두 단계 모두에 뚜렷한 별개의 제한이 발견되었습니다. 프리필 단계는 컴퓨팅 용량으로 인한 제약을 받는 반면, 디코딩 단계는 메모리 대역폭에 의한 제약을 받습니다. 결과적으로, 각 단계는 공유된 int8/int4 가중치의 역양자화를 위해 상이한 전략을 사용합니다. 프리필 단계에서 각 컨볼루션 연산자는 먼저 가중치를 1차 계산 전에 부동 소수점 값으로 역양자화하여 계산 집약적 컨볼루션에 대해 최적의 성능을 보장합니다. 반대로, 디코딩 단계는 기본 수학적 컨볼루션 연산에 역양자화 계산을 추가함으로써 메모리 대역폭을 최소화합니다.
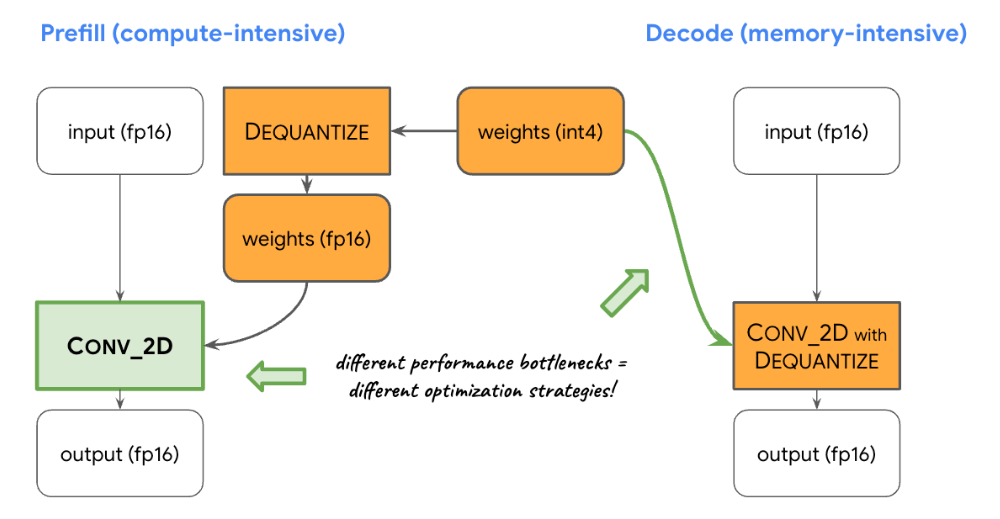
사용자 지정 연산자: 온디바이스 방식 GPU 가속 LLM 추론의 경우, 수많은 소형 셰이더로 인한 비효율을 완화하기 위해 사용자 지정 연산에 크게 의존합니다. 이러한 사용자 지정 연산을 사용하면 토큰 ID, 시퀀스 패치 크기, 샘플링 매개변수 같은 다양한 LLM 매개변수와 특수한 연산자 융합을 이러한 전문적인 연산 내에서 주로 사용되는 전문적인 사용자 지정 텐서에 넣을 수 있습니다.
유사 역동성: 관심 블록에서 컨텍스트가 늘어나면서 시간이 지남에 따라 동적 연산이 증가하는 문제가 생깁니다. GPU 런타임은 동적 연산/텐서에 대한 지원이 부족하므로 미리 정의된 최대 캐시 크기로 고정 연산을 선택합니다. 계산 복잡도를 줄이기 위해 특정 값 계산을 건너뛰거나 축소된 데이터를 처리할 수 있는 매개변수를 도입합니다.
최적화된 KV 캐시 레이아웃: KV 캐시의 항목은 궁극적으로 행렬 곱셈 대신 사용되는 컨볼루션의 가중치 역할을 하기 때문에 컨볼루션 가중치에 맞게 특화된 레이아웃에 이러한 항목을 저장합니다. 이러한 전략적 조정은 최적화되지 않은 레이아웃에 대한 추가 변환 또는 의존의 필요성을 제거하므로 프로세스를 보다 효율적이고 간소화하는데 기여합니다.
현재 실험 중인 MediaPipe LLM Inference API 릴리스에서 보여준 최적화와 성능이 무척 고무적입니다. 이는 시작에 불과합니다. 2024년에는 더 많은 플랫폼과 모델로 확장하고, 더 광범위한 변환 도구와 무료 온디바이스 구성요소, 높은 수준의 작업 등을 제공할 예정입니다.
GitHub에서 방금 학습한 모든 내용을 보여주는 공식 샘플을 확인하고 공식 설명서를 통해 자세한 내용을 확인할 수 있습니다. Google for Developers YouTube 채널에서 최신 정보와 튜토리얼을 살펴보세요.
이 작업에 기여해 주신 T.J. Alumbaugh, Alek Andreev, Frank Ban, Jeanine Banks, Frank Barchard, Pulkit Bhuwalka, Buck Bourdon, Maxime Brénon, Chuo-Ling Chang, Lin Chen, Linkun Chen, Yu-hui Chen, Nikolai Chinaev, Clark Duvall, Rosário Fernandes, Mig Gerard, Matthias Grundmann, Ayush Gupta, Mohammadreza Heydary, Ekaterina Ignasheva, Ram Iyengar, Grant Jensen, Alex Kanaukou, Prianka Liz Kariat, Alan Kelly, Kathleen Kenealy, Ho Ko, Sachin Kotwani, Andrei Kulik, Yi-Chun Kuo, Khanh LeViet, Yang Lu, Lalit Singh Manral, Tyler Mullen, Karthik Raveendran, Raman Sarokin, Sebastian Schmidt, Kris Tonthat, Lu Wang, Zoe Wang, Tris Warkentin, Geng Yan, Tenghui Zhu 등 모든 팀원 여러분과 Gemma 팀에 감사드립니다.