

MediaPipe Solutions is available in preview today
This week at Google I/O 2023, we introduced MediaPipe Solutions, a new collection of on-device machine learning tools to simplify the developer process. This is made up of MediaPipe Studio, MediaPipe Tasks, and MediaPipe Model Maker. These tools provide no-code to low-code solutions to common on-device machine learning tasks, such as audio classification, segmentation, and text embedding, for mobile, web, desktop, and IoT developers.

In December 2022, we launched the MediaPipe preview with five tasks: gesture recognition, hand landmarker, image classification, object detection, and text classification. Today we’re happy to announce that we have launched an additional nine tasks for Google I/O, with many more to come. Some of these new tasks include:

Our first MediaPipe tool lets you view and test MediaPipe-compatible models on the web, rather than having to create your own custom testing applications. You can even use MediaPipe Studio in preview right now to try out the new tasks mentioned here, and all the extras, by visiting the MediaPipe Studio page.
In addition, we have plans to expand MediaPipe Studio to provide a no-code model training solution so you can create brand new models without a lot of overhead.
MediaPipe Tasks simplifies on-device ML deployment for web, mobile, IoT, and desktop developers with low-code libraries. You can easily integrate on-device machine learning solutions, like the examples above, into your applications in a few lines of code without having to learn all the implementation details behind those solutions. These currently include tools for three categories: vision, audio, and text.
To give you a better idea of how to use MediaPipe Tasks, let’s take a look at an Android app that performs gesture recognition.
The following code will create a GestureRecognizer object using a built-in machine learning model, then that object can be used repeatedly to return a list of recognition results based on an input image:
// STEP 1: Create a gesture recognizer
val baseOptions = BaseOptions.builder().setModelAssetPath("gesture_recognizer.task") .build()
val gestureRecognizerOptions = GestureRecognizerOptions.builder() .setBaseOptions(baseOptions).build()
val gestureRecognizer = GestureRecognizer.createFromOptions( context, gestureRecognizerOptions)
// STEP 2: Prepare the image
val mpImage = BitmapImageBuilder(bitmap).build()
// STEP 3: Run inference
val result = gestureRecognizer.recognize(mpImage)As you can see, with just a few lines of code you can implement seemingly complex features in your applications. Combined with other Android features, like CameraX, you can provide delightful experiences for your users.
Along with simplicity, one of the other major advantages to using MediaPipe Tasks is that your code will look similar across multiple platforms, regardless of the task you’re using. This will help you develop even faster as you can reuse the same logic for each application.
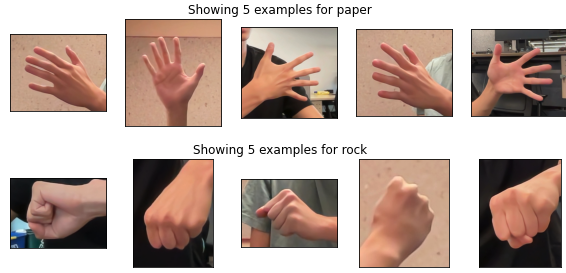
While being able to recognize and use gestures in your apps is great, what if you have a situation where you need to recognize custom gestures outside of the ones provided by the built-in model? That’s where MediaPipe Model Maker comes in. With Model Maker, you can retrain the built-in model on a dataset with only a few hundred examples of new hand gestures, and quickly create a brand new model specific to your needs. For example, with just a few lines of code you can customize a model to play Rock, Paper, Scissors.
from mediapipe_model_maker import gesture_recognizer
# STEP 1: Load the dataset.
data = gesture_recognizer.Dataset.from_folder(dirname='images') train_data, validation_data = data.split(0.8)
# STEP 2: Train the custom model.
model = gesture_recognizer.GestureRecognizer.create( train_data=train_data, validation_data=validation_data, hparams=gesture_recognizer.HParams(export_dir=export_dir) )
# STEP 3: Evaluate using unseen data.
metric = model.evaluate(test_data)
# STEP 4: Export as a model asset bundle. model.export_model(model_name='rock_paper_scissor.task')After retraining your model, you can use it in your apps with MediaPipe Tasks for an even more versatile experience.
To learn more, watch our I/O 2023 sessions: Easy on-device ML with MediaPipe, Supercharge your web app with machine learning and MediaPipe, and What's new in machine learning, and check out the official documentation over on developers.google.com/mediapipe.
We will continue to improve and provide new features for MediaPipe Solutions, including new MediaPipe Tasks and no-code training through MediaPipe Studio. You can also keep up to date by joining the MediaPipe Solutions announcement group, where we send out announcements as new features are available.
We look forward to all the exciting things you make, so be sure to share them with @googledevs and your developer communities!