

MediaPipe Solutions가 오늘 미리보기로 제공됩니다
이번 주 Google I/O 2023에서는 개발자 프로세스 간소화를 위한 새로운 온디바이스 머신러닝 도구 컬렉션인 MediaPipe Solutions를 소개했습니다. 이 컬렉션은 MediaPipe Studio, MediaPipe Tasks, MediaPipe Model Maker로 구성되어 있습니다. 이 도구들은 모바일, 웹, 데스크톱 및 IoT 개발자를 위해 오디오 분류, 세분화, 텍스트 삽입 같은 일반 온디바이스 머신러닝 작업에 대해 노코드부터 로우코드까지 다양한 솔루션을 제공합니다.

2022년 12월에 동작 인식과 핸드 랜드마커, 이미지 분류, 객체 감지, 텍스트 분류의 5가지 작업이 포함된 MediaPipe 미리보기가 출시되었습니다. Google I/O를 위해 9가지 작업이 추가로 출시되었음을 알릴 수 있어 매우 기쁩니다. 앞으로 더 많은 작업이 출시될 것입니다만 추가 출시된 9가지 작업 중 일부를 소개합니다.

최초로 제공하는 MediaPipe 도구를 사용하면 사용자 설정 테스트 애플리케이션을 만들 필요 없이 웹에서 MediaPipe 호환 모델을 확인하고 테스트할 수 있습니다. MediaPipe Studio 페이지를 방문하여 지금 바로 미리보기에서 MediaPipe Studio를 사용하여 여기 언급된 새로운 작업과 그 외 모든 작업을 시도해 볼 수도 있습니다.
뿐만 아니라 여러분이 많은 오버헤드 없이 새로운 모델을 만들 수 있도록 MediaPipe Studio를 확장해 노코드 모델 학습 솔루션을 제공할 계획입니다.
MediaPipe Tasks는 로우코드 라이브러리를 사용하여 웹, 모바일, IoT 및 데스크톱 개발자를 위한 온디바이스 ML 배포를 단순화합니다. 그러면 위 예시와 같은 온디바이스 머신러닝 솔루션을 애플리케이션에 쉽게 통합할 수 있습니다. 해당 솔루션 이면의 모든 구현 세부 정보를 학습할 필요 없이 코드만 몇 줄 있으면 됩니다. 비전과 오디오, 텍스트의 세 가지 카테고리를 위한 도구가 현재 여기에 포함됩니다.
MediaPipe Tasks 사용 방법에 대한 여러분의 이해를 돕기 위해, 동작 인식을 수행하는 Android 앱을 살펴보겠습니다.
다음 코드는 기본 제공 머신러닝 모델을 사용하여 GestureRecognizer 객체를 생성할 것입니다. 그렇게 생성된 객체는 입력 이미지를 기반으로 인식 결과 목록을 반환하기 위해 반복 사용될 수 있습니다.
// 1단계: 동작 인식기 만들기
val baseOptions = BaseOptions.builder().setModelAssetPath("gesture_recognizer.task") .build()
val gestureRecognizerOptions = GestureRecognizerOptions.builder() .setBaseOptions(baseOptions).build()
val gestureRecognizer = GestureRecognizer.createFromOptions( context, gestureRecognizerOptions)
// 2단계: 이미지 준비
val mpImage = BitmapImageBuilder(bitmap).build()
// 3단계: 유추 실행
val result = gestureRecognizer.recognize(mpImage)보시다시피, 코드 단 몇 줄로 복잡해 보이는 기능을 애플리케이션에 구현할 수 있습니다. CameraX 등 다른 Android 기능과 결합하면 사용자에게 즐거운 경험을 선사할 수 있습니다.
단순성과 더불어 MediaPipe Tasks 활용에 있어 주요 장점 중 하나는 사용 중인 작업에 관계없이 여러 플랫폼에서 코드가 비슷해 보인다는 점입니다. 즉, 각 애플리케이션에 대해 동일한 논리를 재사용할 수 있으므로 개발 시간 단축에 도움이 됩니다.
앱에서 동작을 인식하고 사용할 수 있다는 점은 좋지만, 기본 제공 모델에서 제공하는 동작 이외의 사용자 설정 동작을 인식해야 하는 상황에서는 어떻게 해야 할까요? 이런 경우를 대비해 만든 것이 MediaPipe Model Maker입니다. Model Maker를 사용하면 몇 백 개 정도의 새로운 손동작 예시만으로 데이터 세트에서 기본 제공 모델을 다시 학습시키고 필요에 맞는 새로운 모델을 빠르게 만들 수 있습니다. 예를 들어, 몇 줄의 코드만으로 가위바위보를 실행하는 모델을 사용자 설정할 수 있습니다.
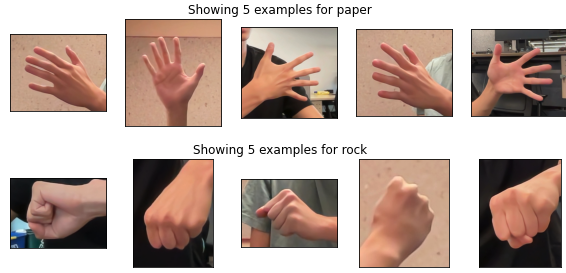
from mediapipe_model_maker import gesture_recognizer
# 1단계: 데이터 세트를 로드합니다.
data = gesture_recognizer.Dataset.from_folder(dirname='images') train_data, validation_data = data.split(0.8)
# 2단계: 사용자 설정 모델을 학습시킵니다.
model = gesture_recognizer.GestureRecognizer.create( train_data=train_data, validation_data=validation_data, hparams=gesture_recognizer.HParams(export_dir=export_dir) )
# 3단계: 미확인 데이터를 사용하여 평가합니다.
metric = model.evaluate(test_data)
# 4단계: 모델 애셋 번들로 내보냅니다. model.export_model(model_name='rock_paper_scissor.task')모델을 재학습시킨 후 MediaPipe Tasks로 앱에서 모델을 사용할 수 있어 훨씬 더 다양한 경험을 할 수 있습니다.
자세히 알아보려면 I/O 2023 세션 Easy on-device ML with MediaPipe(MediaPipe를 사용하는 간편한 온디바이스 ML), Supercharge your web app with machine learning and MediaPipe(머신러닝과 MediaPipe를 사용한 웹 앱 강화), What's new in machine learning(머신러닝의 새로운 기능)을 시청하고 developers.google.com/mediapipe에서 공식 문서를 확인해 보세요.
새로운 MediaPipe Tasks 및 MediaPipe Studio를 통한 노코드 학습을 포함해 MediaPipe Solutions의 새로운 기능을 지속적으로 제공 및 개선하겠습니다. 또한 신기능이 출시될 때 알려 드리는 MediaPipe Solutions 발표 그룹에 가입하면 최신 정보를 계속 받아보실 수 있습니다.
개발자 여러분이 어떤 흥미로운 결과물을 만들지 정말 기대됩니다. 여러분의 개발품들을 @googledevs 및 개발자 커뮤니티와 꼭 공유해 주세요!