

MediaPipe ソリューションは現在プレビュー版として提供中
今週開催された Google I/O 2023 で、MediaPipe ソリューションを紹介しました。MediaPipe ソリューションは、新しいオンデバイス機械学習ツールのコレクションで、デベロッパーのプロセスを簡素化します。MediaPipe Studio、MediaPipe Tasks、MediaPipe Model Maker で構成されており、モバイル、ウェブ、PC、IoT のデベロッパーが利用できるノーコードまたはローコードのソリューションとして、オーディオ分類、セグメンテーション、テキスト埋め込みなどの一般的なオンデバイス機械学習タスクを実現できます。

MediaPipe のプレビューは、2022 年 12 月に、ジェスチャー認識、ハンド ランドマーカー、画像分類、オブジェクト検出、テキスト分類の 5 つのタスクで開始されました。本日は、Google I/O 向けにさらに 9 つのタスクを追加します。今後もさらに多くのタスクが追加される予定です。新しいタスクには、次のようなものがあります。

この最初の MediaPipe ツールを使うと、独自のカスタム テストアプリを作らなくても、ウェブで MediaPipe 互換モデルの表示やテストを行うことができます。MediaPipe Studio のページにアクセスして、MediaPipe Studio のプレビュー版を今すぐ使うこともできます。ここに記載されている新しいタスクやすべての追加機能を試せます。
多くのオーバーヘッドなしでまったく新しいモデルを作成できるようにするために、MediaPipe Studio を拡張して、ノーコード モデル トレーニング ソリューションを提供する計画もあります。
MediaPipe Tasks は、ローコード ライブラリを使って、ウェブ、モバイル、IoT、PC のデベロッパーが簡単にオンデバイス ML を導入できるようにするものです。上の例のようなオンデバイス機械学習ソリューションを、その背後にある詳しい実装を一切学習することなく、数行のコードでアプリに簡単に組み込むことができます。現在は、視覚、音声、テキストの 3 つのカテゴリに対応したツールが含まれています。
MediaPipe Tasks の使い方を深く理解していただくために、ジェスチャーを認識する Android アプリを見てみましょう。
次のコードは、組み込み機械学習モデルを使って GestureRecognizer オブジェクトを作成し、そのオブジェクトを繰り返し使って、入力画像に基づく認識結果リストを返します。
// 手順 1: ジェスチャ認識を作成する
val baseOptions = BaseOptions.builder().setModelAssetPath("gesture_recognizer.task") .build()
val gestureRecognizerOptions = GestureRecognizerOptions.builder() .setBaseOptions(baseOptions).build()
val gestureRecognizer = GestureRecognizer.createFromOptions( context, gestureRecognizerOptions)
// 手順 2: 画像を準備する
val mpImage = BitmapImageBuilder(bitmap).build()
// 手順 3: 推論を実行する
val result = gestureRecognizer.recognize(mpImage)ご覧のとおり、一見複雑な機能を、わずか数行のコードでアプリに実装できます。CameraX などの他の Android 機能と組み合わせると、ユーザーに快適な体験を提供できます。
MediaPipe Tasks を使う主な利点は、シンプルさだけではありません。使用するタスクに関係なく、複数のプラットフォームでコードが似たものになるので、それぞれのアプリで同じロジックを再利用でき、開発時間をさらに短縮できます。
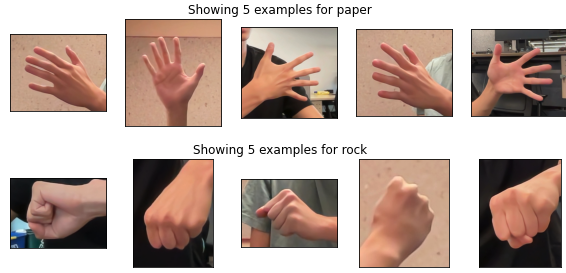
アプリでジェスチャーを認識して利用できるのはすばらしいことですが、組み込みモデルで提供されているジェスチャー以外のカスタム ジェスチャーを認識しなければならない場合もあるでしょう。そんなときは、MediaPipe Model Maker の出番です。Model Maker を使うと、新しいハンド ジェスチャーの例を数百個集めたデータセットだけで内蔵モデルを再トレーニングして、皆さんのニーズに特化したまったく新しいモデルを短時間で作成できます。たとえば、わずか数行のコードだけで、モデルをカスタマイズしてじゃんけんをすることができます。
from mediapipe_model_maker import gesture_recognizer
# 手順 1: データセットを読み込む。
data = gesture_recognizer.Dataset.from_folder(dirname='images') train_data, validation_data = data.split(0.8)
# 手順 2: カスタムモデルをトレーニングする。
model = gesture_recognizer.GestureRecognizer.create( train_data=train_data, validation_data=validation_data, hparams=gesture_recognizer.HParams(export_dir=export_dir) )
# 手順 3: 未知のデータで評価する。
metric = model.evaluate(test_data)
# 手順 4: モデルアセット バンドルとしてエクスポートする。 model.export_model(model_name='rock_paper_scissor.task')モデルを再トレーニングした後、MediaPipe Tasks でアプリを動作させると、さらに汎用性の高いエクスペリエンスが得られます。
詳細については、MediaPipe を使った簡単なオンデバイス ML、機械学習と MediaPipe でウェブアプリをパワーアップ、機械学習の新機能についての I/O 2023 セッションをご覧ください。また、developers.google.com/mediapipe の公式ドキュメントもご覧ください。
新しい MediaPipe Tasks や、MediaPipe Studio によるノーコード トレーニングなど、今後も MediaPipe ソリューションの改善と新機能の提供を続けます。MediaPipe ソリューションのお知らせグループに参加して、最新情報を入手しましょう。新しい機能が利用できるようになったら、ここでお知らせします。
皆さんが作るエキサイティングな作品を楽しみにしています。ぜひ @googledevs と所属するデベロッパー コミュニティで共有してください!