

今年 2 月,我们宣布推出 Gemma,这是我们最先进的轻量级开源模型系列,利用创建 Gemini 模型所用的研究和技术创建而成。社区令人难以置信的反应确实令人鼓舞,包括给人留下深刻印象的微调变体、Kaggle Notebooks、可以集成到工具和服务中、使用 MongoDB 等数据库的 RAG 方案等等。
今天,我们很高兴地宣布推出第一轮为 Gemma 系列新增的内容,从而提高 ML 开发者以负责任方式进行创新的可能性:用于代码补全和生成任务以及指令跟随的 CodeGemma;以及用于研究实验的效率优化架构 RecurrentGemma。此外,我们还会分享我们根据社区和合作伙伴的宝贵反馈对 Gemma 和条款所作的一些改进更新。
以 Gemma 模型为基础,CodeGemma 为社区带来轻量但功能强大的编码功能。CodeGemma 模型有以下三种变体:专门用于代码补全和代码生成任务的 7B 预训练变体,经过指令调整、用于代码聊天和指令跟随的 7B 变体,以及适合在本地计算机上实现快速代码补全的 2B 预训练变体。CodeGemma 模型具有以下优点:
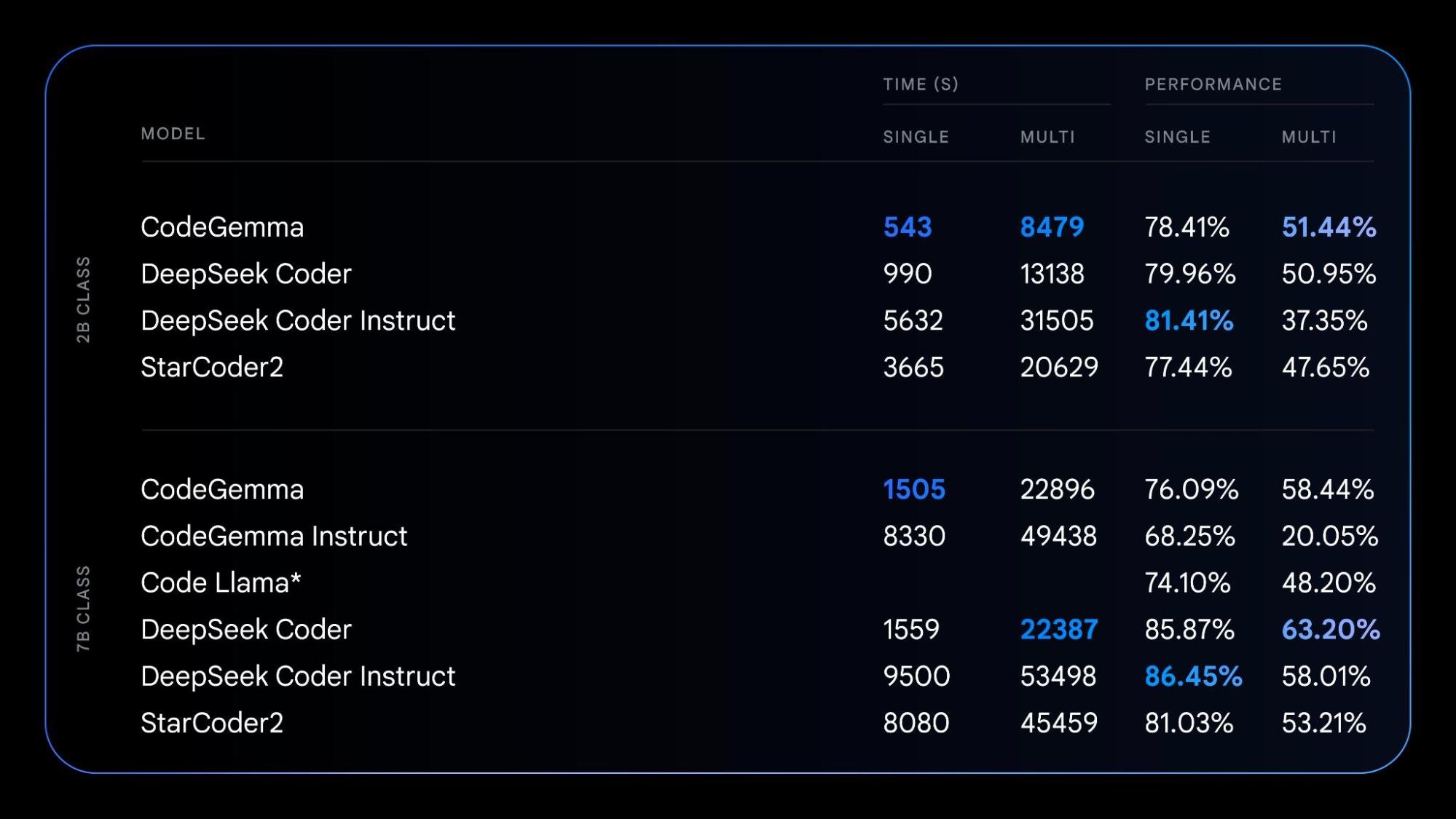
在我们的报告中了解有关 CodeGemma 的更多信息,或根据此快速入门指南进行试用。
RecurrentGemma 是采用独特技术开发的模型,利用循环神经网络和局部注意力来提高记忆效率。在达到与 Gemma 2B 模型相似的基准分数性能的同时,RecurrentGemma 独特的架构还具有以下优势:
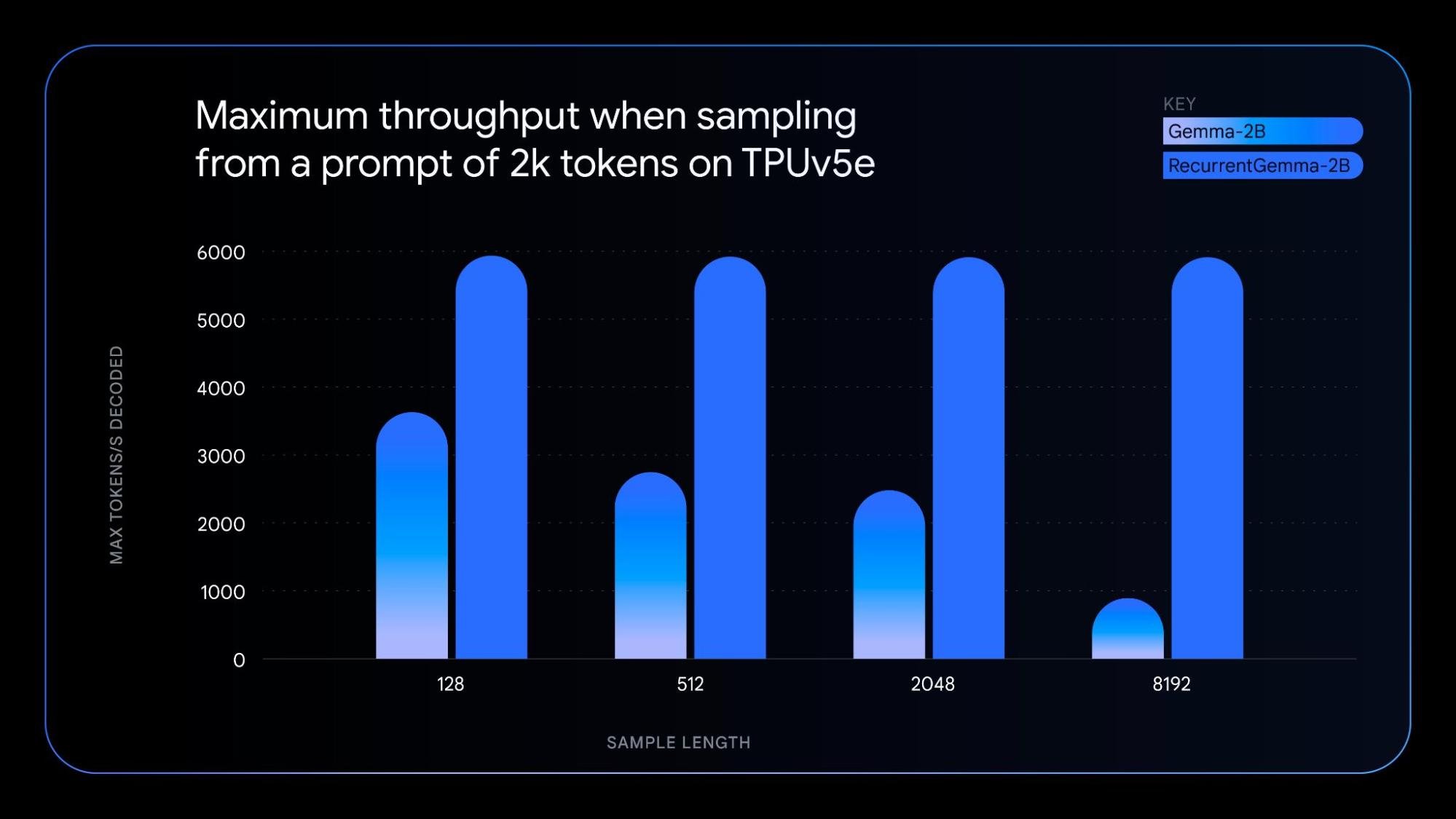
要了解基础技术,请查看我们的论文。如需进行实践探索,请尝试根据记事本中的模型微调方法进行操作。
以原始 Gemma 模型遵循的原理为指导,新模型变体具备以下优势:
- CodeGemma 和 RecurrentGemma:使用 JAX 构建而来,并且兼容 JAX、PyTorch、Hugging Face Transformer 和 Gemma.cpp。支持在各种硬件上进行本地实验和经济实惠的部署,包括笔记本电脑、台式机、NVIDIA GPU 和 Google Cloud TPU。
- CodeGemma:还兼容 Keras、NVIDIA NeMo、TensorRT-LLM、Optimum-NVIDIA、MediaPipe,并且可以在 Vertex AI 上使用。
- RecurrentGemma:将在未来几周提供对所有上述产品的支持。
除了新的模型变体,我们还发布了经过性能改进的 Gemma 1.1。此外,我们还听取了开发者的反馈意见,修复了错误,并更新了条款,以提供更大的灵活性。
从今天开始,全球各地的开发者都能在 Kaggle、Hugging Face 和 Vertex AI Model Garden 上使用首批 Gemma 模型变体。以下是开始使用的方法:
我们诚邀您试用 CodeGemma 和 RecurrentGemma 模型,并在 Kaggle 上分享您的反馈。让我们共同塑造基于 AI 的内容创作及相关知识经验的未来。



