
O Gemma é uma família de modelos abertos criados a partir da mesma pesquisa e tecnologia usadas para criar os modelos Gemini. Os modelos Gemma são capazes de executar uma grande variedade de tarefas, inclusive geração de texto, preenchimento e geração de códigos, ajuste para tarefas específicas e execução em vários dispositivos.
O Ray é um framework de código aberto para escalonar aplicativos Python e de IA. O Ray fornece a infraestrutura para executar a computação distribuída e o processamento em paralelo para fluxos de trabalho de aprendizado de máquina (ML, na sigla em inglês).
Ao final deste tutorial, você terá uma boa compreensão de como usar o ajuste supervisionado do Gemma no Ray na Vertex AI para treinar e disponibilizar modelos de aprendizado de máquina com eficiência e eficácia.
Você pode explorar o notebook do tutorial "Get started with Gemma on Ray on Vertex AI" no GitHub para saber mais sobre o Gemma no Ray. Todo o código abaixo está nesse notebook para facilitar sua jornada.
As etapas a seguir são obrigatórias, independentemente do ambiente.
2. Verifique se o faturamento está ativado para o projeto.
3. Ative as APIs.
Se você estiver executando este tutorial localmente, será necessário instalar o SDK Cloud.
Este tutorial usa componentes pagos do Google Cloud:
Para saber mais sobre preços, use a calculadora de preços para gerar uma estimativa de custo com base no uso projetado.
Usaremos o conjunto de dados Extreme Summarization (XSum), que é relacionado a sistemas abstrativos de resumo de documento único.
É necessário criar um bucket de armazenamento para armazenar artefatos intermediários, como conjuntos de dados.
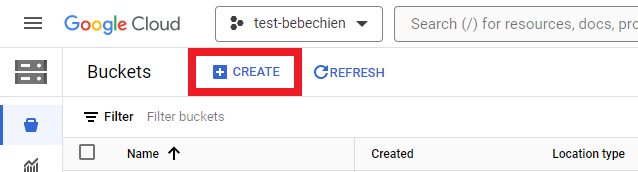
Ou com a Google Cloud CLI
gsutil mb -l {REGION} -p {PROJECT_ID} {BUCKET_URI}
# for example: gsutil mb -l asia-northeast1 -p test-bebechien gs://test-bebechien-ray-bucketPara armazenar a imagem de cluster personalizada, crie um repositório do Docker no Artifact Registry.
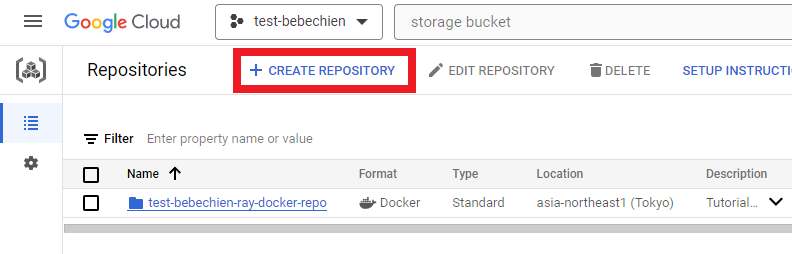
Ou com a Google Cloud CLI
gcloud artifacts repositories create your-repo --repository-format=docker --location=your-region --description="Tutorial repository"O objetivo de uma instância do TensorBoard é rastrear e monitorar jobs de ajuste. É possível criar uma em Experiments.
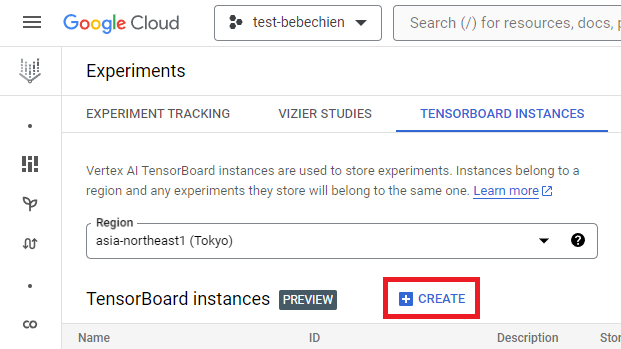
Ou com a Google Cloud CLI
gcloud ai tensorboards create --display-name your-tensorboard --project your-project --region your-regionPara começar a usar o Ray na Vertex AI, você pode optar por criar um Dockerfile do zero para uma imagem personalizada ou utilizar uma das imagens de base do Ray prontas. Essas imagens de base estão disponíveis aqui.
Primeiro, prepare o arquivo de requisitos que inclui as dependências que o aplicativo Ray precisa executar.
Em seguida, crie o Dockerfile para a imagem personalizada usando uma das imagens de base prontas do Ray na Vertex AI.
Por fim, crie a imagem personalizada do cluster do Ray usando o Cloud Build.
gcloud builds submit --region=your-region
--tag=your-region-docker.pkg.dev/your-project/your-repo/train --machine-type=E2_HIGHCPU_32 ./dockerfile-pathSe tudo funcionar bem, você verá que a imagem personalizada foi enviada com sucesso para o repositório de imagens do Docker.
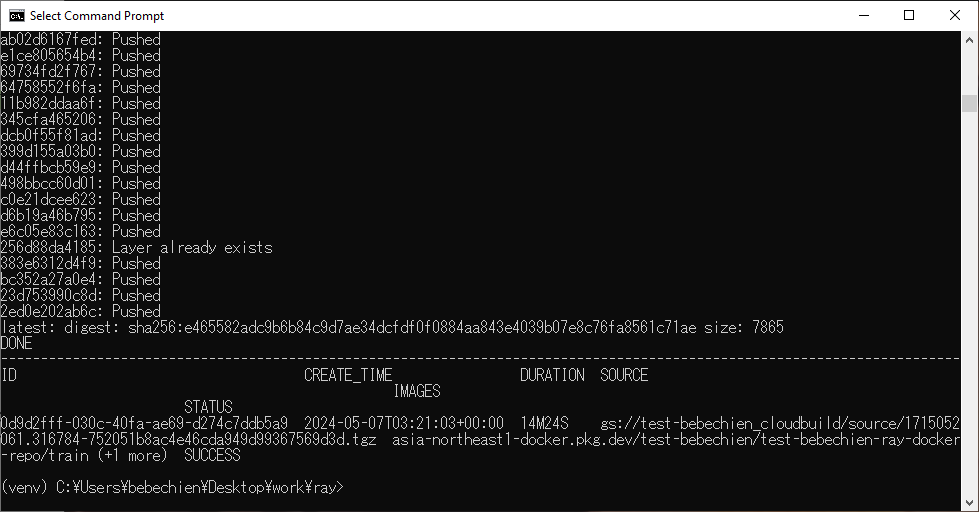
Também no Artifact Registry
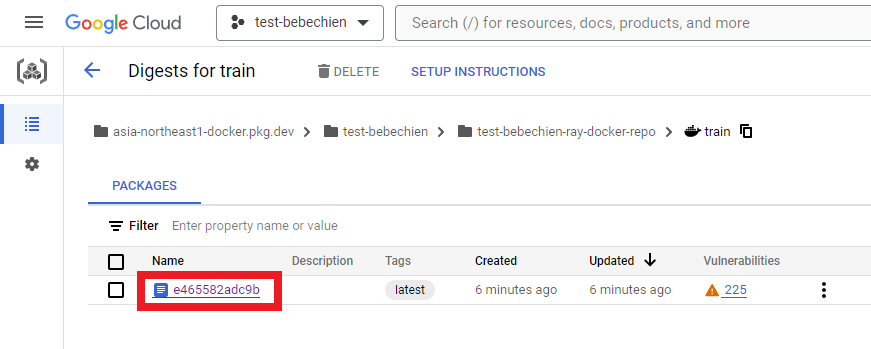
Você pode criar o cluster do Ray no Ray na Vertex AI.
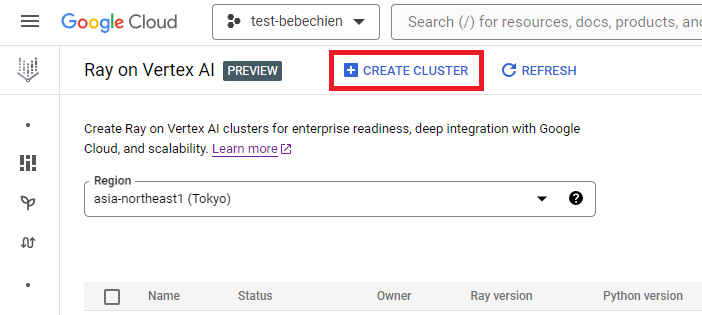
Ou use o SDK do Python da Vertex AI para criar um cluster do Ray com uma imagem personalizada e para personalizar a configuração do cluster. Para saber mais sobre a configuração do cluster, consulte a documentação.
Abaixo está um exemplo de código do Python para criar o cluster do Ray com a configuração personalizada predefinida.
OBSERVAÇÃO: a criação de um cluster pode levar vários minutos, dependendo da configuração.
# Set up Ray on Vertex AI
import vertex_ray
from google.cloud import aiplatform as vertex_ai
from vertex_ray import NodeImages, Resources
# Retrieves an existing managed tensorboard given a tensorboard ID
tensorboard = vertex_ai.Tensorboard(your-tensorboard-id, project=your-project, location=your-region)
# Initialize the Vertex AI SDK for Python for your project
vertex_ai.init(project=your-project, location=your-region, staging_bucket=your-bucket-uri, experiment_tensorboard=tensorboard)
HEAD_NODE_TYPE = Resources(
machine_type= "n1-standard-16",
node_count=1,
)
WORKER_NODE_TYPES = [
Resources(
machine_type="n1-standard-16",
node_count=1,
accelerator_type="NVIDIA_TESLA_T4",
accelerator_count=2,
)
]
CUSTOM_IMAGES = NodeImages(
head="your-region-docker.pkg.dev/your-project/your-repo/train",
worker="your-region-docker.pkg.dev/your-project/your-repo/train",
)
ray_cluster_name = vertex_ray.create_ray_cluster(
head_node_type=HEAD_NODE_TYPE,
worker_node_types=WORKER_NODE_TYPES,
custom_images=CUSTOM_IMAGES,
cluster_name=”your-cluster-name”,
)Agora, você pode obter o cluster do Ray com get_ray_cluster(). Use list_ray_clusters() se quiser visualizar todos os clusters associados ao projeto.
ray_clusters = vertex_ray.list_ray_clusters()
ray_cluster_resource_name = ray_clusters[-1].cluster_resource_name
ray_cluster = vertex_ray.get_ray_cluster(ray_cluster_resource_name)
print("Ray cluster on Vertex AI:", ray_cluster_resource_name)Para ajustar o Gemma com o Ray na Vertex AI, você pode usar o Ray Train para distribuir Transformers do Hugging Face com o treinamento do PyTorch, conforme mostrado abaixo.
Com o Ray Train, você define uma função de treinamento que contém o código dos Transformers do Hugging Face para ajustar o Gemma que você deseja distribuir. Em seguida, você define a configuração de escalonamento para especificar o número desejado de workers e indicar se o processo de treinamento distribuído requer GPUs. Além disso, você pode definir uma configuração de tempo de execução para especificar comportamentos de ponto de verificação e sincronização. Por fim, você envia o ajuste iniciando um TorchTrainer e executa-o usando seu método fit.
Neste tutorial, ajustaremos o Gemma 2B (gemma-2b-it) para resumir matérias de jornal usando o Transformer do Hugging Face no Ray na Vertex AI. Escrevemos um script trainer.py simples do Python e enviaremos esse script para o cluster do Ray.
Vamos preparar o script de treinamento. Abaixo, está um exemplo de script do Python para inicializar o ajuste do Gemma usando a biblioteca Hugging Face TRL.
Em seguida, prepare o script de treinamento distribuído. Abaixo, está um exemplo de script do Python para executar o job do treinamento distribuído do Ray.
Agora, enviamos o script para o cluster do Ray usando a API Ray Jobs por meio do endereço do painel do Ray. O endereço do painel também está disponível na página de detalhes do cluster, conforme mostrado abaixo.
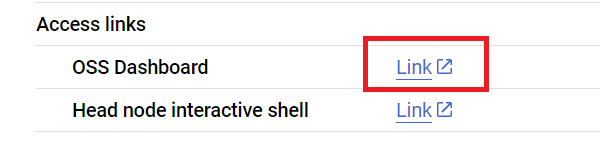
Primeiro, inicie o cliente para enviar o job.
import ray
from ray.job_submission import JobSubmissionClient
client = JobSubmissionClient(
address="vertex_ray://{}".format(ray_cluster.dashboard_address)
)Vamos definir algumas configurações do job, incluindo o caminho do modelo, o ID do job, o ponto de entrada de previsão e muito mais.
import random, string, datasets, transformers
from etils import epath
from huggingface_hub import login
# Initialize some libraries settings
login(token=”your-hf-token”)
datasets.disable_progress_bar()
transformers.set_seed(8)
train_experiment_name = “your-experiment-name”
train_submission_id = “your-submission-id”
train_entrypoint = f"python3 trainer.py --experiment-name={train_experiment_name} --logging-dir=”your-bucket-uri/logs” --num-workers=2 --use-gpu"
train_runtime_env = {
"working_dir": "your-working-dir",
"env_vars": {"HF_TOKEN": ”your-hf-token”, "TORCH_NCCL_ASYNC_ERROR_HANDLING": "3"},
}Envie o job
train_job_id = client.submit_job(
submission_id=train_submission_id,
entrypoint=train_entrypoint,
runtime_env=train_runtime_env,
)Verifique o status do job no painel do OSS.
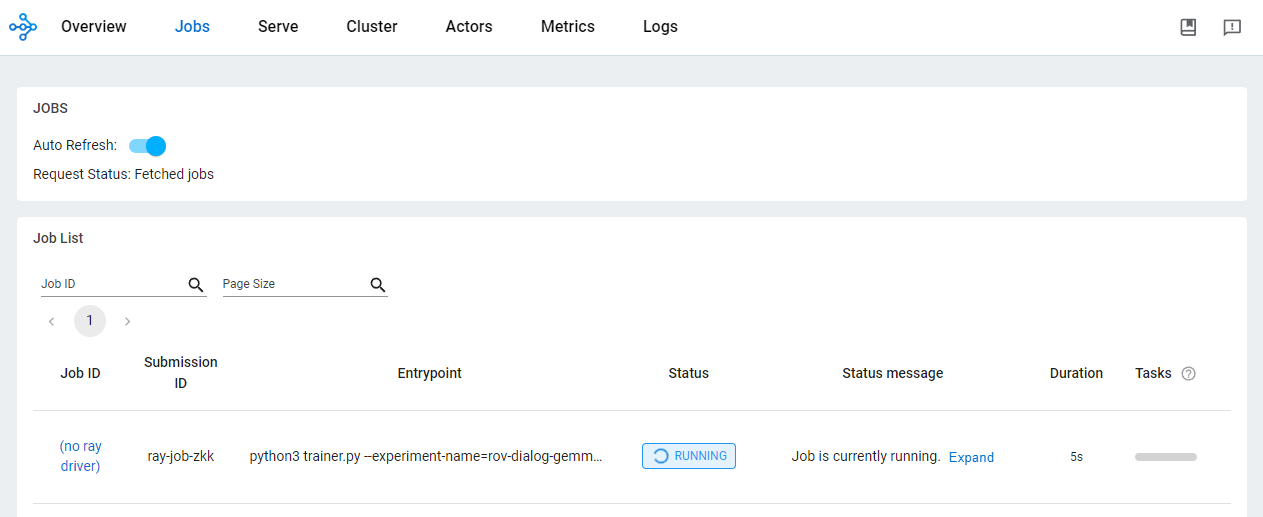
O uso do Ray na Vertex AI para desenvolver aplicativos de IA/ML proporciona vários benefícios. Nesse cenário, você pode usar o Cloud Storage para armazenar adequadamente pontos de verificação do modelo, métricas e muito mais. Isso permite o consumo rápido do modelo para tarefas de downstream de IA/ML, incluindo o monitoramento do processo de treinamento usando o TensorBoard da Vertex AI ou a geração de previsões em lote usando o Ray Data.
Enquanto o job de treinamento do Ray estiver em execução e após a conclusão, você verá os artefatos do modelo no local do Cloud Storage com a Google Cloud CLI.
gsutil ls -l your-bucket-uri/your-experiments/your-experiment-nameVocê pode usar o TensorBoard da Vertex AI para validar seu job de treinamento registrando as métricas resultantes.
vertex_ai.upload_tb_log(
tensorboard_id=tensorboard.name,
tensorboard_experiment_name=train_experiment_name,
logdir=./experiments,
)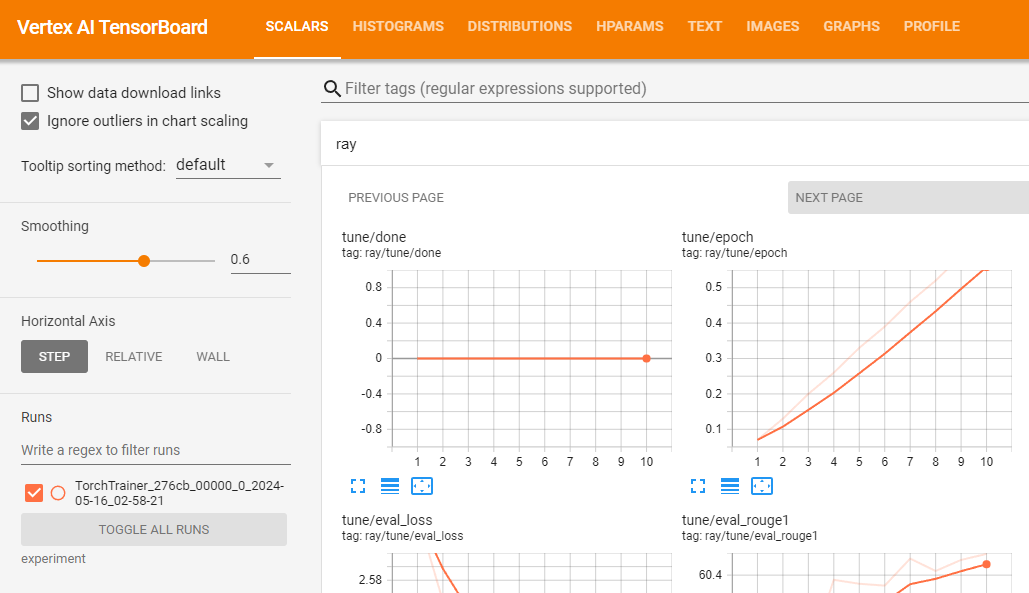
Se o treinamento for executado com sucesso, você poderá gerar previsões localmente para validar o modelo ajustado.
Primeiro, faça o download de todos os pontos de verificação resultantes do job do Ray com a Google Cloud CLI.
# copy all artifacts
gsutil ls -l your-bucket-uri/your-experiments/your-experiment-name ./your-experiment-pathUse o método ExperimentAnalysis para recuperar o melhor ponto de verificação de acordo com as métricas e o modo relevantes.
import ray
from ray.tune import ExperimentAnalysis
experiment_analysis = ExperimentAnalysis(“./your-experiment-path”)
log_path = experiment_analysis.get_best_trial(metric="eval_rougeLsum", mode="max")
best_checkpoint = experiment_analysis.get_best_checkpoint(
log_path, metric="eval_rougeLsum", mode="max"
)Agora você sabe qual é o melhor ponto de verificação. Abaixo, temos um exemplo de saída.

E carregue o modelo ajustado conforme descrito na documentação do Hugging Face.
Abaixo, temos um exemplo de código do Python para carregar o modelo de base e mesclar os adaptadores com esse modelo para que você possa usá-lo como um modelo normal de transformadores. O modelo ajustado salvo está disponível em tuned_model_path. Por exemplo, "tutorial/models/xsum-tuned-gemma-it".
import torch
from etils import epath
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import PeftModel
base_model_path = "google/gemma-2b-it"
peft_model_path = epath.Path(best_checkpoint.path) / "checkpoint"
tuned_model_path = models_path / "xsum-tuned-gemma-it"
tokenizer = AutoTokenizer.from_pretrained(base_model_path)
tokenizer.padding_side = "right"
base_model = AutoModelForCausalLM.from_pretrained(
base_model_path, device_map="auto", torch_dtype=torch.float16
)
peft_model = PeftModel.from_pretrained(
base_model,
peft_model_path,
device_map="auto",
torch_dtype=torch.bfloat16,
is_trainable=False,
)
tuned_model = peft_model.merge_and_unload()
tuned_model.save_pretrained(tuned_model_path)Curiosidade: como você ajustou um modelo, também poderá publicá-lo no Hugging Face Hub usando esta única linha de código:
tuned_model.push_to_hub("my-awesome-model")Para gerar resumos com o modelo ajustado, usaremos o conjunto de validação do conjunto de dados do tutorial.
O exemplo de código do Python a seguir demonstra como obter uma amostra de uma matéria de um conjunto de dados para criar um resumo. Depois, ele gera o resumo associado e exibe lado a lado o resumo de referência do conjunto de dados e o resumo gerado.
import random, datasets
from transformers import pipeline
dataset = datasets.load_dataset(
"xsum", split="validation", cache_dir=”./data”, trust_remote_code=True
)
sample = dataset.select([random.randint(0, len(dataset) - 1)])
document = sample["document"][0]
reference_summary = sample["summary"][0]
messages = [
{
"role": "user",
"content": f"Summarize the following ARTICLE in one sentence.\n###ARTICLE: {document}",
},
]
prompt = tokenizer.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
tuned_gemma_pipeline = pipeline(
"text-generation", model=tuned_model, tokenizer=tokenizer, max_new_tokens=50
)
generated_tuned_gemma_summary = tuned_gemma_pipeline(
prompt, do_sample=True, temperature=0.1, add_special_tokens=True
)[0]["generated_text"][len(prompt) :]
print(f"Reference summary: {reference_summary}")
print("-" * 100)
print(f"Tuned generated summary: {generated_tuned_gemma_summary}")Abaixo, temos um exemplo de saída do modelo ajustado. Observe que o resultado ajustado pode exigir mais refinamento. Para alcançar a qualidade ideal, é necessário iterar o processo várias vezes, ajustando fatores como a taxa de aprendizado e o número de etapas de treinamento.

Como etapa adicional, você pode avaliar o modelo ajustado. Para isso, compare os modelos de maneira qualitativa e quantitativa.
Em um caso, você compara as respostas geradas pelo modelo de base do Gemma com aquelas geradas pelo modelo ajustado do Gemma. No outro caso, você calcula as métricas ROUGE e suas melhorias, o que possibilitará saber se o modelo ajustado será capaz de reproduzir os resumos de referência corretamente em relação ao modelo de base.
Abaixo, temos um código do Python para avaliar modelos por meio da comparação dos resumos gerados.
gemma_pipeline = pipeline(
"text-generation", model=base_model, tokenizer=tokenizer, max_new_tokens=50
)
generated_gemma_summary = gemma_pipeline(
prompt, do_sample=True, temperature=0.1, add_special_tokens=True
)[0]["generated_text"][len(prompt) :]
print(f"Reference summary: {reference_summary}")
print("-" * 100)
print(f"Base generated summary: {generated_gemma_summary}")
print("-" * 100)
print(f"Tuned generated summary: {generated_tuned_gemma_summary}")Abaixo, está um exemplo de saída do modelo de base e do modelo ajustado.
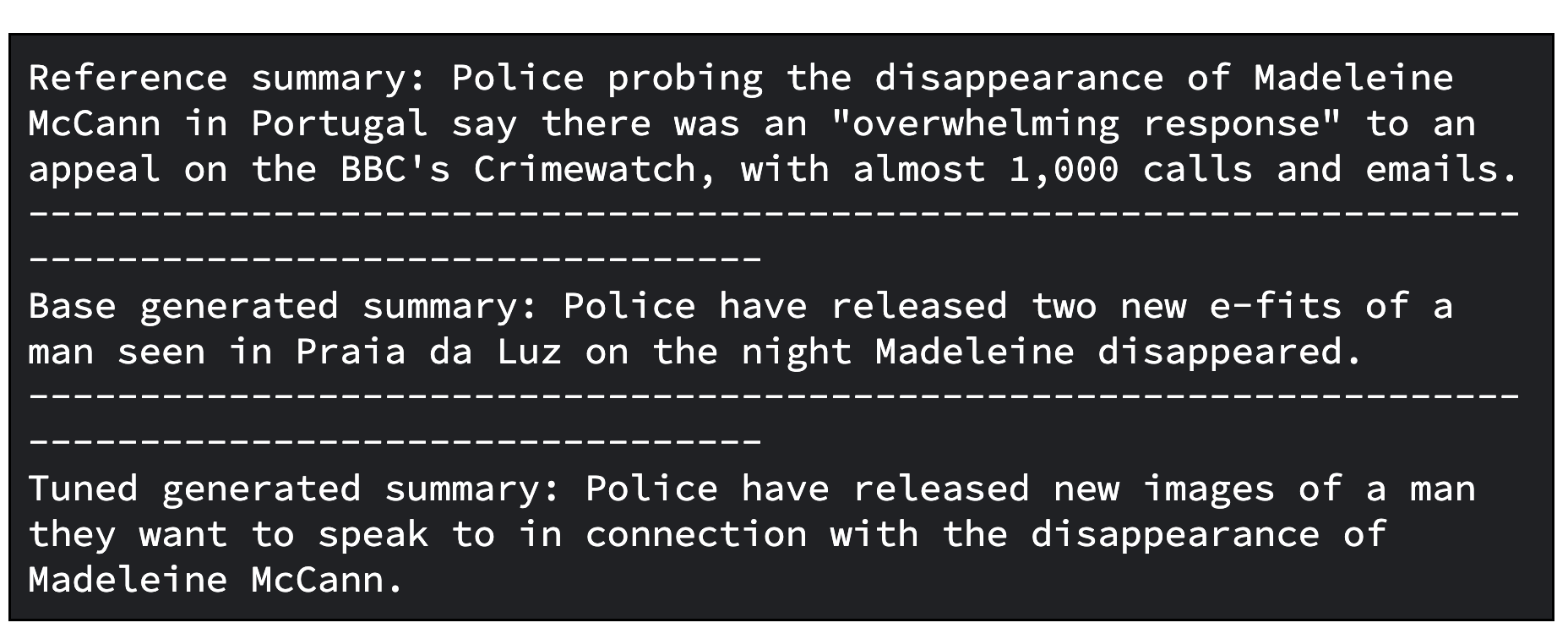
E, abaixo, temos um código para avaliar modelos por meio do cálculo das métricas ROUGE e de suas melhorias.
import evaluate
rouge = evaluate.load("rouge")
gemma_results = rouge.compute(
predictions=[generated_gemma_summary],
references=[reference_summary],
rouge_types=["rouge1", "rouge2", "rougeL", "rougeLsum"],
use_aggregator=True,
use_stemmer=True,
)
tuned_gemma_results = rouge.compute(
predictions=[generated_tuned_gemma_summary],
references=[reference_summary],
rouge_types=["rouge1", "rouge2", "rougeL", "rougeLsum"],
use_aggregator=True,
use_stemmer=True,
)
improvements = {}
for rouge_metric, gemma_rouge in gemma_results.items():
tuned_gemma_rouge = tuned_gemma_results[rouge_metric]
if gemma_rouge != 0:
improvement = ((tuned_gemma_rouge - gemma_rouge) / gemma_rouge) * 100
else:
improvement = None
improvements[rouge_metric] = improvement
print("Base Gemma vs Tuned Gemma - ROUGE improvements")
for rouge_metric, improvement in improvements.items():
print(f"{rouge_metric}: {improvement:.3f}%")E o exemplo de saída da avaliação.

Para gerar previsões off-line em escala com o Gemma ajustado no Ray na Vertex AI, você pode usar o Ray Data, uma biblioteca de processamento de dados escalonável para cargas de trabalho de ML.
Ao usar o Ray Data para gerar previsões off-line com o Gemma, você precisa definir uma classe do Python para carregar o modelo ajustado no Pipeline do Hugging Face. Depois, dependendo da fonte de dados e de seu formato, usamos o Ray Data para realizar a leitura de dados distribuídos e usamos um método de conjunto de dados do Ray para aplicar a classe do Python e realizar previsões em paralelo a vários lotes de dados.
Para gerar a previsão em lote com o modelo ajustado usando o Ray Data na Vertex AI, é necessário que você tenha um conjunto de dados para gerar previsões e que o modelo ajustado esteja armazenado no bucket do Cloud.
Em seguida, você pode usar o Ray Data, que fornece uma API fácil de usar, para fazer a inferência em lote off-line.
Primeiro, faça upload do modelo ajustado no Cloud Storage com a Google Cloud CLI
gsutil -q cp -r “./models” “your-bucket-uri/models”Prepare o arquivo de script de treinamento de previsão em lote para executar o job de previsão em lote do Ray.
Novamente, você pode iniciar o cliente para enviar o job conforme mostrado abaixo usando a API Ray Jobs por meio do endereço do painel do Ray.
import ray
from ray.job_submission import JobSubmissionClient
client = JobSubmissionClient(
address="vertex_ray://{}".format(ray_cluster.dashboard_address)
)Vamos definir algumas configurações do job, incluindo o caminho do modelo, o ID do job, o ponto de entrada de previsão e muito mais.
import random, string
batch_predict_submission_id = "your-batch-prediction-job"
tuned_model_uri_path = "/gcs/your-bucket-uri/models"
batch_predict_entrypoint = f"python3 batch_predictor.py --tuned_model_path={tuned_model_uri_path} --num_gpus=1 --output_dir=”your-bucket-uri/predictions”"
batch_predict_runtime_env = {
"working_dir": "tutorial/src",
"env_vars": {"HF_TOKEN": “your-hf-token”},
}Com o argumento "--num_gpus", você pode especificar o número de GPUs a serem usadas. Esse número deve ser um valor igual a ou menor que o número de GPUs disponíveis no cluster do Ray.
Envie o job.
batch_predict_job_id = client.submit_job(
submission_id=batch_predict_submission_id,
entrypoint=batch_predict_entrypoint,
runtime_env=batch_predict_runtime_env,
)Agora, vamos dar uma olhada rápida nos resumos gerados usando um DataFrame do Pandas.
import io
import pandas as pd
from google.cloud import storage
def read_json_files(bucket_name, prefix=None):
"""Reads JSON files from a cloud storage bucket and returns a Pandas DataFrame"""
# Set up storage client
storage_client = storage.Client()
bucket = storage_client.bucket(bucket_name)
blobs = bucket.list_blobs(prefix=prefix)
dfs = []
for blob in blobs:
if blob.name.endswith(".json"):
file_bytes = blob.download_as_bytes()
file_string = file_bytes.decode("utf-8")
with io.StringIO(file_string) as json_file:
df = pd.read_json(json_file, lines=True)
dfs.append(df)
return pd.concat(dfs, ignore_index=True)
predictions_df = read_json_files(prefix="predictions/", bucket_name=”your-bucket-uri”)
predictions_df = predictions_df[
["id", "document", "prompt", "summary", "generated_summary"]
]
predictions_df.head()Abaixo, temos um exemplo de saída. O número padrão de matérias a serem resumidas é 20. É possível especificar o número com o argumento "--sample_size".

Você já aprendeu bastante, incluindo:
Esperamos que este tutorial tenha sido esclarecedor e fornecido insights úteis.
Recomendamos que você participe do servidor Discord da comunidade de desenvolvedores do Google. Lá, você pode compartilhar seus projetos, conectar-se a outros desenvolvedores e participar de discussões colaborativas.
E não se esqueça de limpar todos os recursos do Google Cloud usados neste projeto. Basta excluir o projeto do Google Cloud que você usou no tutorial ou, ainda, excluir os recursos individuais criados.
# Delete tensorboard
tensorboard_list = vertex_ai.Tensorboard.list()
for tensorboard in tensorboard_list:
tensorboard.delete()
# Delete experiments
experiment_list = vertex_ai.Experiment.list()
for experiment in experiment_list:
experiment.delete()
# Delete ray on vertex cluster
ray_cluster_list = vertex_ray.list_ray_clusters()
for ray_cluster in ray_cluster_list:
vertex_ray.delete_ray_cluster(ray_cluster.cluster_resource_name)# Delete artifacts repo
gcloud artifacts repositories delete “your-repo” -q
# Delete Cloud Storage objects that were created
gsutil -q -m rm -r “your-bucker-uri”Agradecemos a leitura!

Vertex AI RAG Engine: uma ferramenta para desenvolvedores
Uso do KerasHub para fluxos de trabalho simples de aprendizado de máquina de ponta a ponta com o Hugging Face

Advancing agentic AI development with Firebase Studio

Apresentamos o Gemma 3n: o guia para desenvolvedores

T5Gemma: A new collection of encoder-decoder Gemma models

Announcing GenAI Processors: Build powerful and flexible Gemini applications