
생성형 AI는 기술에 대한 사람들의 기대를 근본적으로 바꿨습니다. 사람들은 대규모 클라우드 기반 모델이 놀라운 방식으로 만들고 추론하고 지원하는 힘을 목격했습니다. 그러나 다음에 다가올 위대한 기술적 도약은 단지 클라우드 모델의 규모를 더 크게 만드는 것만이 아니라, 즉각적이고 개인적인 환경으로 직접 인텔리전스를 임베딩하는 것입니다. AI가 진정한 보조자가 되려면, 즉 사람들의 하루 일과를 돕고, 실시간으로 대화를 번역하고, 물리적 맥락을 이해하기 위해서는 사람들이 매일 착용하고 휴대하는 기기에서 구동해야 합니다. 이는 핵심 과제를 던져줍니다. 배터리 용량에 따라 사용 시간과 조건이 제한되는 에지 기기에 앰비언트 AI를 임베딩하여 클라우드에서 벗어나 진정으로 개인적이고 하루 종일 도움을 주는 환경을 제공해야 하는 것입니다.
클라우드에서 개인용 기기로 이동하려면 다음 세 가지 중대한 문제를 해결해야 합니다.
오늘 풀 스택 플랫폼 Coral NPU를 선보입니다. 저희가 Coral에서 수행한 원본 작업 결과물을 기반으로 구축된 Coral NPU는 하드웨어 설계자와 ML 개발자에게 차세대의 효율적인 개인용 에지 AI 기기를 개발하는 데 필요한 도구를 제공합니다. Google 연구팀 및 Google DeepMind와 제휴하여 공동으로 설계한 Coral NPU는 차세대 초저전력 상시 가동 에지 AI를 지원하기 위해 개발된 AI 우선 하드웨어 아키텍처입니다. 통합된 개발자 실험 환경을 제공하여 주변 감지 앱 같은 앱을 더욱 손쉽게 배포할 수 있도록 지원합니다. Coral NPU는 배터리 사용량을 최소화하고 더욱 높은 성능이 필요한 사용 사례에 맞게 구성 가능한 동시에 웨어러블 기기에서 하루 종일 AI를 사용할 수 있도록 설계되었습니다. 개발자와 설계자가 오늘부터 바로 개발을 시작할 수 있도록 설명서와 도구를 공개했습니다.
저전력 에지 기기용 앱 개발자는 범용 CPU와 특수 가속기 중 하나를 선택해야 하는 근본적인 딜레마에 직면합니다. 범용 CPU는 매우 중요한 유연성과 광범위한 소프트웨어 지원을 제공하지만 까다로운 ML 워크로드에 필요한 도메인별 아키텍처가 부족해 성능이 떨어지고 전력 효율도 낮습니다. 반대로, 특수 가속기는 ML 효율이 높지만 유연성이 부족하고 프로그래밍하기 어려우며 일반적인 작업에는 적합하지 않습니다.
이런 하드웨어 문제는 고도로 단편화된 소프트웨어 생태계로 인해 더욱 심화됩니다. CPU와 ML 블록마다 프로그래밍 모델이 서로 완전히 달라, 개발자는 어쩔 수 없이 독점 컴파일러와 복잡한 명령 버퍼를 사용해야 하는 경우가 많습니다. 이로 인해 가파른 학습 곡선이 형성되고 다른 컴퓨팅 유닛의 고유한 강점을 결합하기 어려워집니다. 그 결과, 업계는 여러 ML 개발 프레임워크를 간단하고 효과적으로 지원할 수 있는 성숙한 저전력 아키텍처를 아직 확보하지 못한 상태입니다.
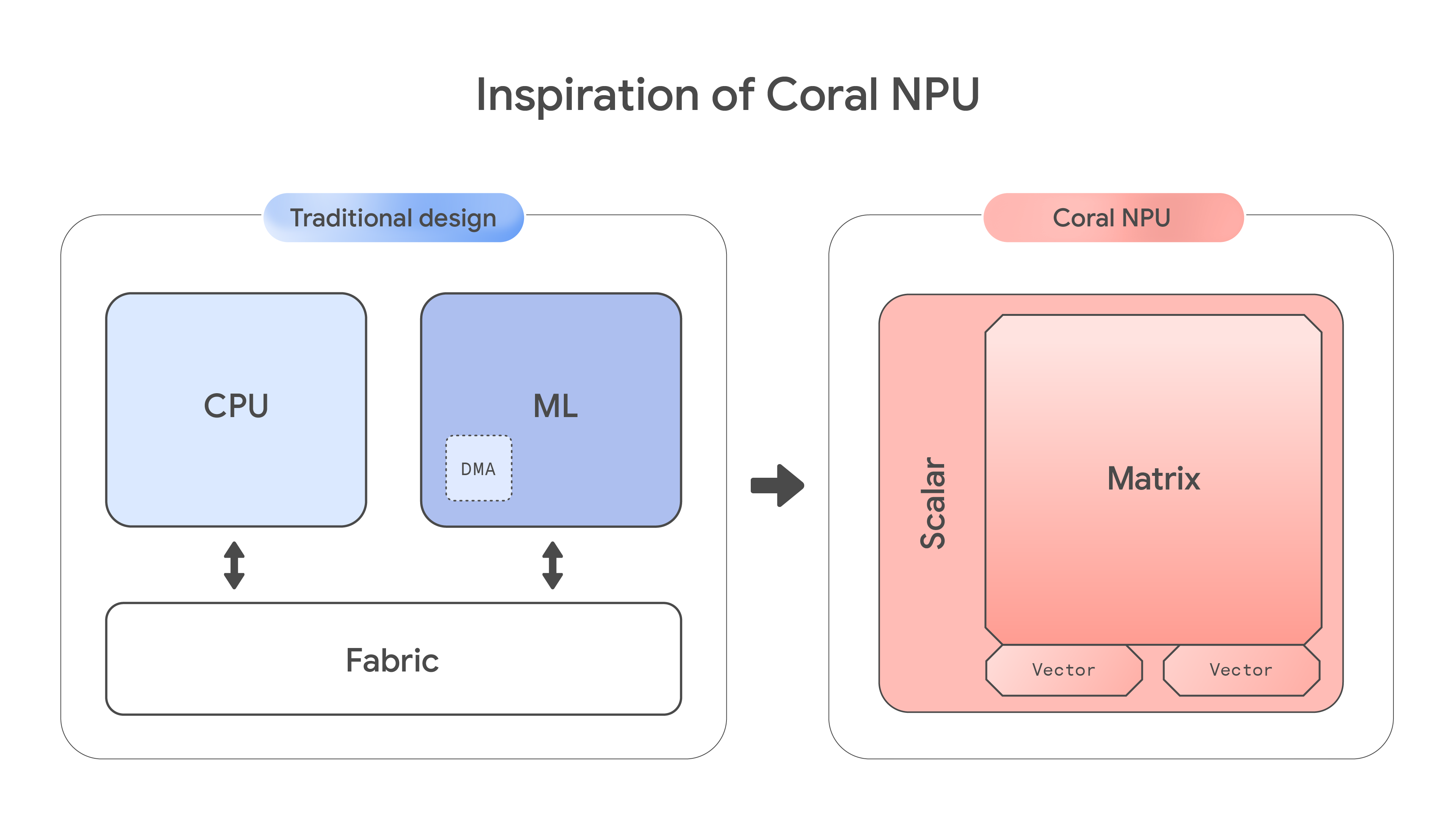
Coral NPU 아키텍처는 기존의 칩 설계 방식을 뒤집어서 이 문제를 직접 해결합니다. 스칼라 컴퓨팅보다 ML 행렬 엔진을 우선시하여, 반도체 단계에서부터 AI에 최적화된 아키텍처를 구축하고 더 효율적인 온디바이스 추론을 위해 개발된 전용 플랫폼을 구현합니다.
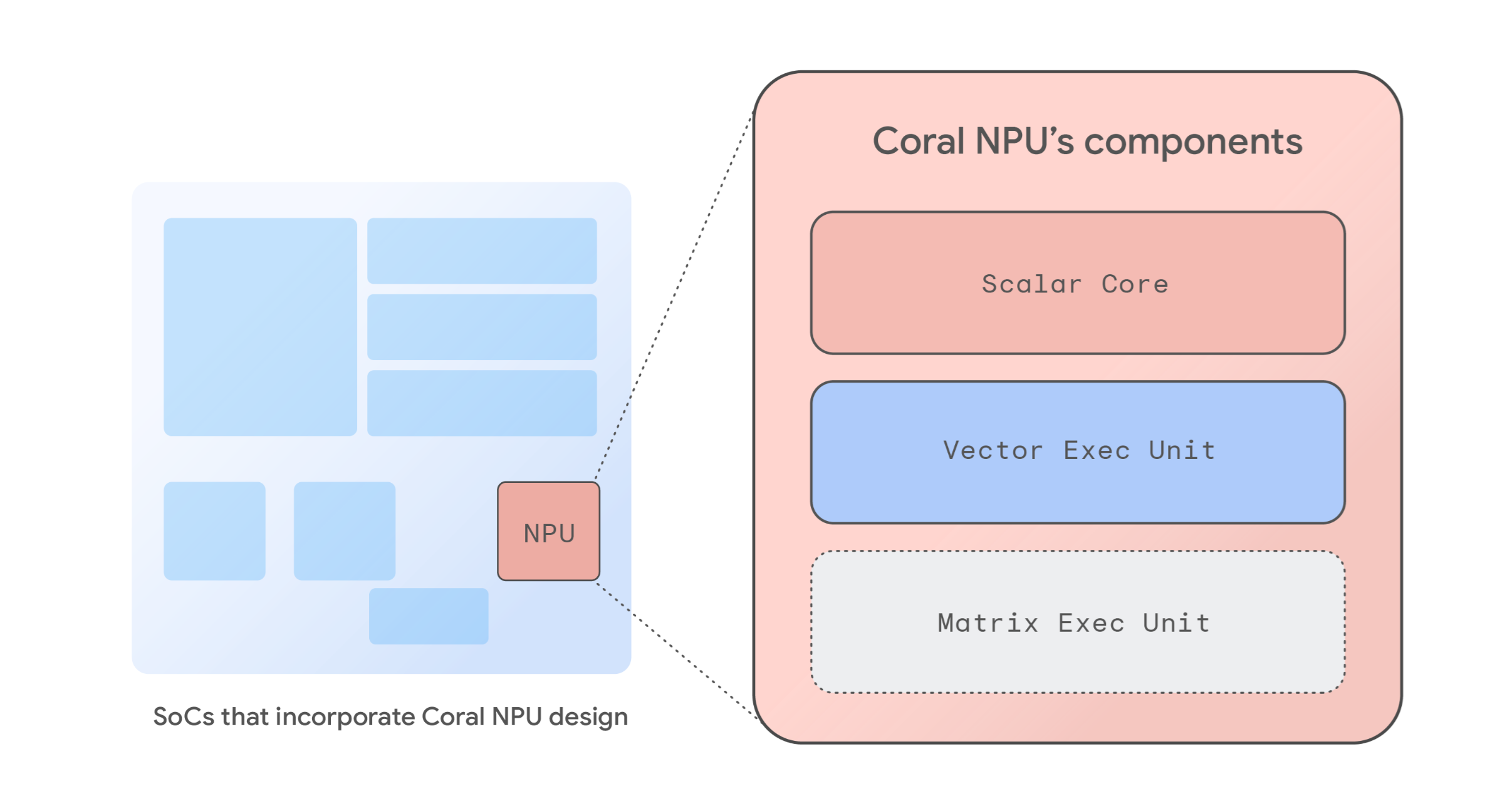
완전한 참조 신경망 처리 장치(NPU) 아키텍처인 Coral NPU는 에너지 효율적인 차세대 ML 최적화 시스템 온 칩(SoC)을 위한 기본 구성요소를 제공합니다. 이 아키텍처는 RISC-V ISA 규격을 준수하는 아키텍처 IP 블록 세트를 기반으로 하며, 전력 소비를 최소화하도록 설계되어 상시 가동되는 주변 감지 기능을 구현하기에 이상적입니다. 기본 설계는 512 GOPS(giga operations per second: 초당 기가 연산) 수준의 성능을 제공하면서도 소비 전력은 몇 밀리와트에 불과하므로 에지 기기, 히어러블 기기, AR 안경, 스마트시계를 위한 강력한 온디바이스 AI를 구현할 수 있습니다.
RISC-V를 기반으로 하는 확장 가능한 이 개방형 아키텍처는 SoC 설계자에게 기본 설계를 수정하거나 사전 구성된 NPU로 사용할 수 있는 유연성을 제공합니다. Coral NPU 아키텍처에는 다음 구성요소가 포함됩니다.
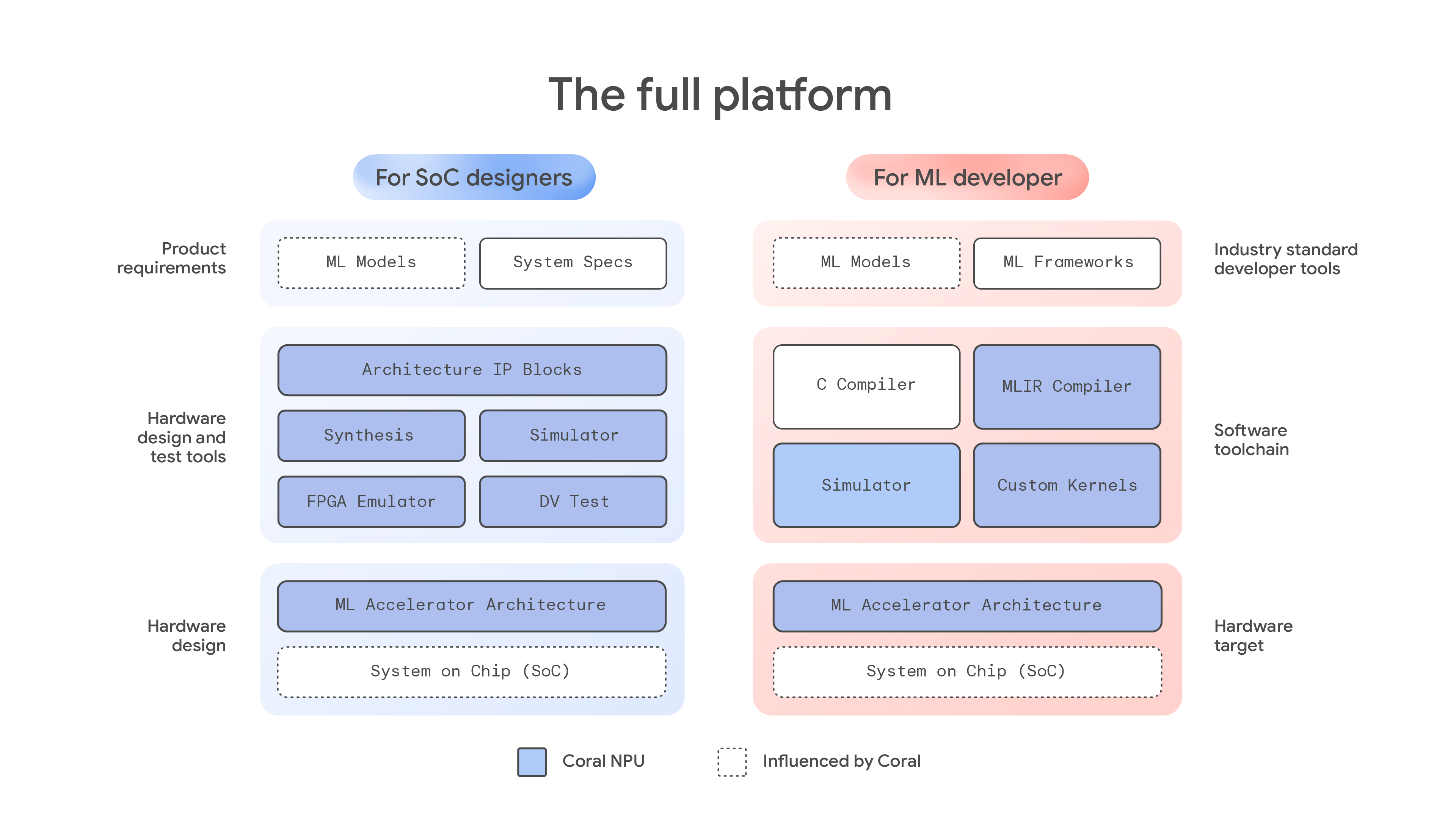
Coral NPU 아키텍처는 IREE 및 TFLM과 같은 최신 컴파일러와 원활하게 통합할 수 있는 간단한, C 프로그래밍 가능 타깃입니다. 이를 통해 TensorFlow, JAX, PyTorch와 같은 ML 프레임워크를 쉽게 지원할 수 있습니다.
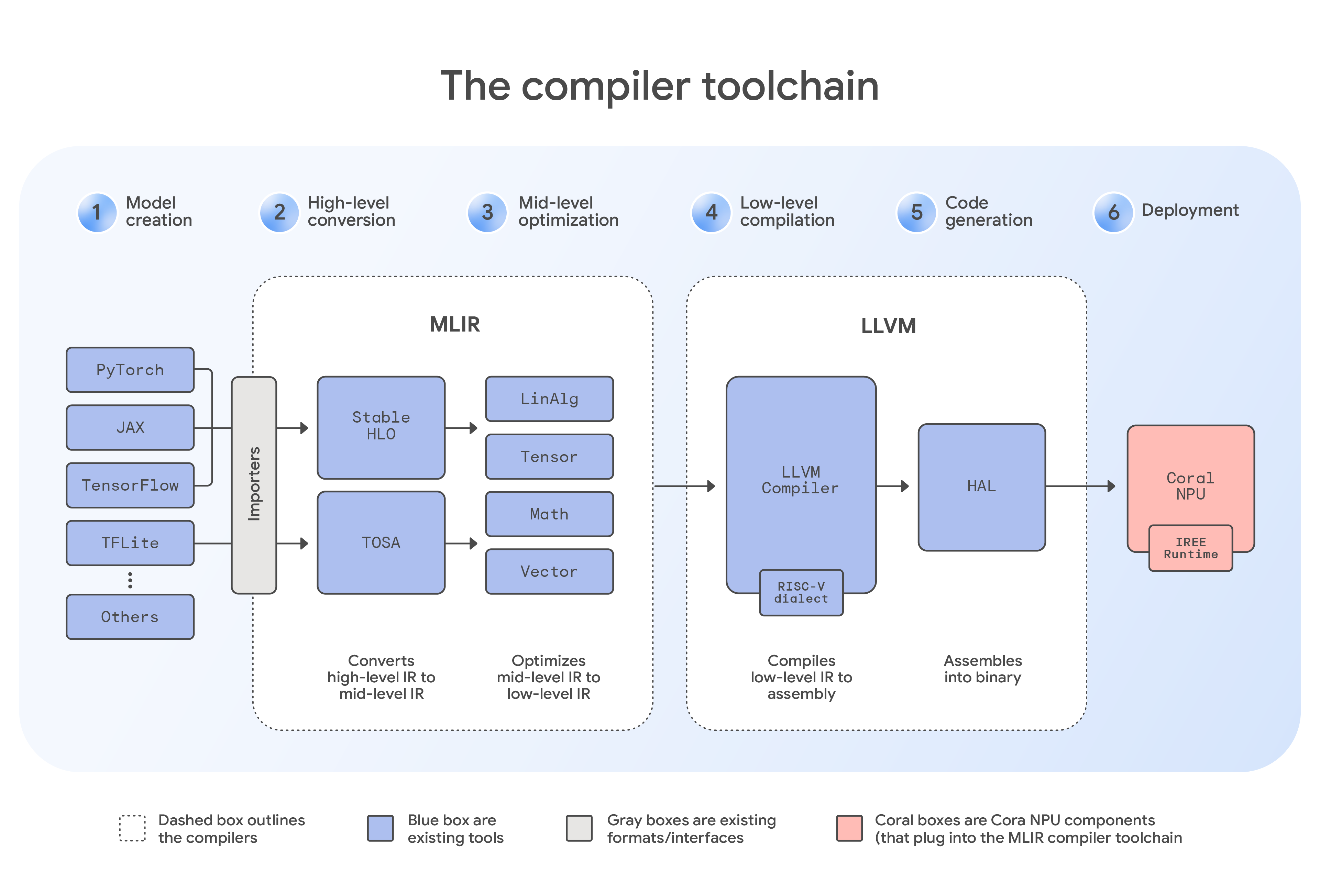
Coral NPU는 TensorFlow용 TFLM 컴파일러 같은 특수 솔루션을 비롯해 범용 MLIR 컴파일러, C 컴파일러, 맞춤형 커널, 시뮬레이터를 포함한 포괄적인 소프트웨어 툴체인을 통합합니다. 이는 개발자에게 유연한 개발 경로를 제공합니다. 예를 들어, JAX 같은 프레임워크의 모델은 먼저 StableHLO 방언을 사용하여 MLIR 형식으로 변환됩니다. 그런 다음 이 중간 파일은 IREE 컴파일러에 전달되며, 이 컴파일러는 하드웨어 전용 플러그인을 적용하여 Coral NPU의 아키텍처를 인식합니다. 이후 컴파일러는 점진적 하강을 수행합니다. 이는 코드가 일련의 방언을 거치며 머신의 모국어에 더 근접하도록 체계적으로 변환되는 핵심적인 최적화 단계입니다. 최적화 후, 툴체인은 에지 기기에서 효율적으로 실행할 수 있도록 준비된 최종적인 콤팩트한 바이너리 파일을 생성합니다. 이 업계 표준 개발자 도구 모음은 ML 모델의 프로그래밍을 간소화하는 데 도움이 되며 다양한 하드웨어 타깃에서 일관된 경험을 제공할 수 있습니다.
Coral NPU의 공동 설계 과정은 두 가지 핵심 영역에 초점을 맞춥니다. 첫째, 이 아키텍처는 오늘날의 온디바이스 비전 및 오디오 애플리케이션에 사용되는 최신 인코더 기반 아키텍처를 효율적으로 가속화합니다. 둘째, 저희는 Gemma 팀과 긴밀히 협력하여 Coral NPU를 소형 트랜스포머 모델에 맞게 최적화하고 있으며, 이를 통해 가속기 아키텍처가 차세대 에지용 생성형 AI를 지원할 수 있도록 돕고 있습니다.
이러한 방향성은 Coral NPU가 LLM을 웨어러블 기기에 구현할 수 있는 최초의 개방형 표준 기반 저전력 NPU로 완성되어 가고 있음을 의미합니다. 개발자에게는 최소 전력으로 최대 성능을 발휘하면서 현재 모델과 미래 모델을 모두 배포할 수 있는 검증된 단일 경로를 제공합니다.
Coral NPU는 특히 주변 감지 시스템에 초점을 맞춘 초저전력 상시 가동 에지 AI 애플리케이션을 지원하도록 설계되었습니다. 주요 목표는 웨어러블 기기, 휴대전화, 사물 인터넷(IoT) 기기에서 배터리 사용량을 최소화하면서도 하루 종일 AI 경험을 제공하는 것입니다.
잠재적인 사용 사례에는 다음이 포함됩니다.
Coral NPU의 핵심 원칙은 하드웨어 기반 보안을 통해 사용자 신뢰를 구축하는 것입니다. Google의 아키텍처는 정교한 메모리 단위의 안전성과 확장 가능한 소프트웨어 구획화를 제공하는 CHERI와 같은 새로운 기술을 지원하도록 설계되고 있습니다. 이러한 접근 방식을 통해 민감한 AI 모델과 개인 데이터를 하드웨어로 보호되는 샌드박스 환경에 격리하여 메모리 기반 공격을 완화할 수 있기를 바랍니다.
개방형 하드웨어 프로젝트의 성공은 강력한 파트너십에 달려 있습니다. 이를 위해 저희는 최초의 전략적 반도체 파트너이자 IoT용 임베디드 컴퓨팅, 무선 연결, 멀티 모달 감지 분야의 선두주자인 Synaptics와 협력하고 있습니다. 오늘 Synaptics는 직접 주관하는 Tech Day 이벤트에서 AI 네이티브 IoT 프로세서의 새로운 Astra™ SL2610 라인을 발표했습니다. 이 제품 라인은 업계 최초로 Coral NPU 아키텍처를 양산 단계에서 구현한 Torq™ NPU 서브시스템이 특징입니다. 이 NPU는 트랜스포머 아키텍처와 동적 연산자를 지원하도록 설계되어, 개발자가 소비자 및 산업용 IoT를 위한 미래 지향적 Edge AI 시스템을 개발할 수 있도록 합니다.
이 파트너십은 통합된 개발자 경험을 위한 저희의 노력에 힘을 보태줍니다. Synaptics Torq™ Edge AI 플랫폼은 IREE 및 MLIR을 기반으로 하는 오픈소스 컴파일러 및 런타임을 기반으로 개발되었습니다. 이번 협업은 지능형 상황 인식 기기를 위해 공유된 개방형 표준을 구축하기 위한 중요한 단계입니다.
Coral NPU를 통해 저희는 개인용 AI의 미래를 위한 기반을 구축하고 있습니다. 저희 Google의 목표는 업계가 발판으로 삼을 수 있는 공통되고 안전한 오픈소스 플랫폼을 제공하여 활기찬 생태계를 육성하는 것입니다. 이를 통해 개발자와 반도체 공급 업체들은 현재의 파편화된 환경을 뛰어넘어 에지 컴퓨팅을 위한 공통 표준을 바탕으로 협력하여 더 빠른 혁신을 실현할 수 있습니다. Coral NPU에 대해 자세히 알아보고 지금 바로 개발을 시작하세요.
이 작업을 담당한 핵심 기여자 및 리더십 팀, 특히 Billy Rutledge, Ben Laurie, Derek Chow, Michael Hoang, Naveen Dodda, Murali Vijayaraghavan, Gregory Kielian, Matthew Wilson, Bill Luan, Divya Pandya, Preeti Singh, Akib Uddin, Stefan Hall, Alex Van Damme, David Gao, Lun Dong, Julian Mullings-Black, Roman Lewkow, Shaked Flur, Yenkai Wang, Reid Tatge, Tim Harvey, Tor Jeremiassen, Isha Mishra, Kai Yick, Cindy Liu, Bangfei Pan, Ian Field, Srikanth Muroor, Jay Yagnik, Avinatan Hassidim, Yossi Matias 님께 감사드립니다.



