
Gemma 徹底解説シリーズの前回の記事では、Gemma モデル ファミリーのアーキテクチャを詳しく解説しました。それぞれの投稿へのリンクは以下のとおりです。
今回の投稿では、最新モデル Gemma 3 について説明します。さっそく始めましょう。
以前のバージョンからの大きな変更点は、Gemma 3 が新たにビジョン言語機能をサポートしていることです。PaliGemma のアーキテクチャに精通している方は、Gemma 3 で使われている SigLIP エンコーダをご存知かもしれませんが、これを今回の実装に合わせて調整しています。
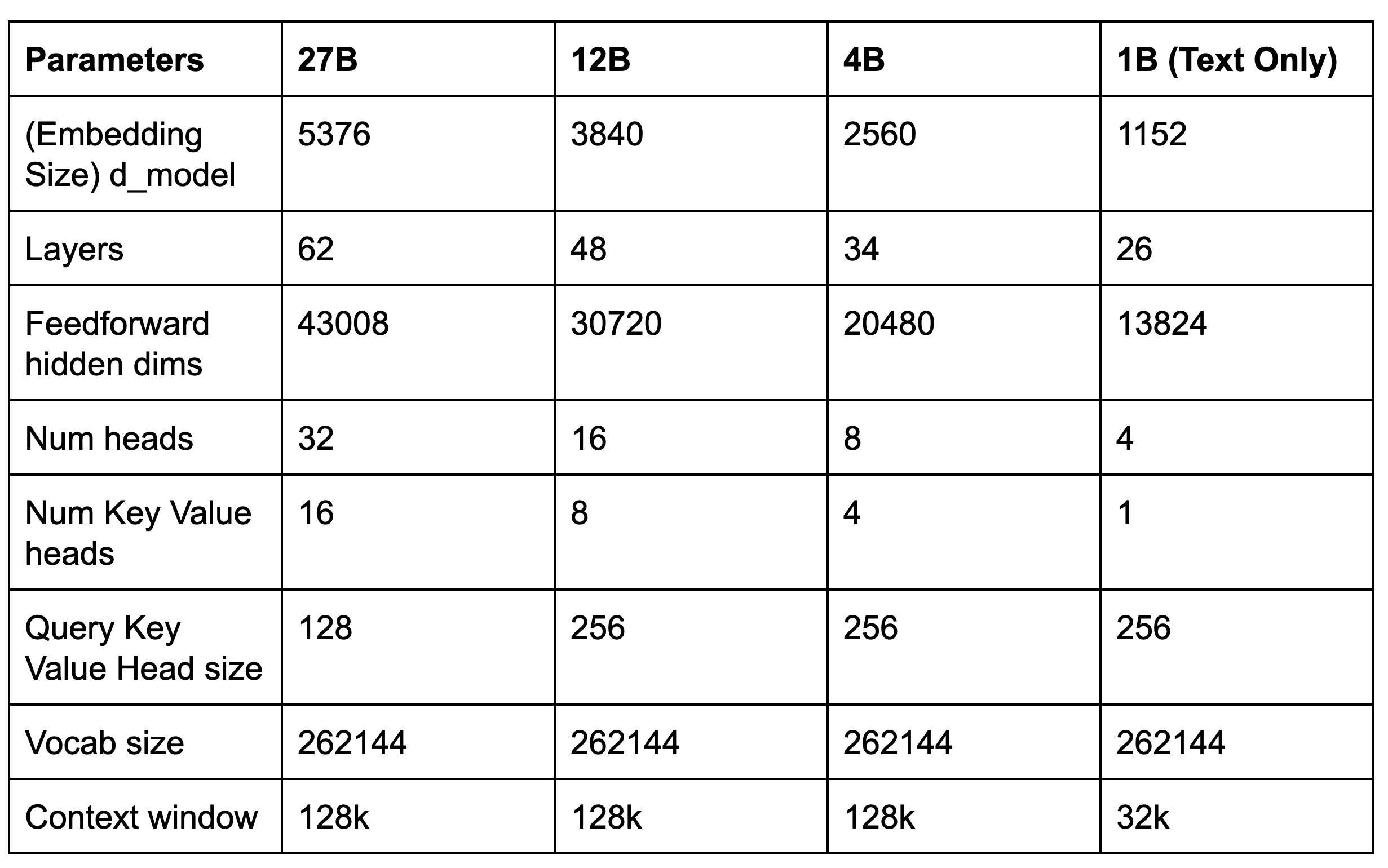
新しいモデルのコアパラメータは次のとおりです。
Gemma 3 の主な変更点と改善点を確認していきましょう。
Gemma 3 のアーキテクチャは前モデルを継承していますが、以下で説明するような新たな変更も加えられています。
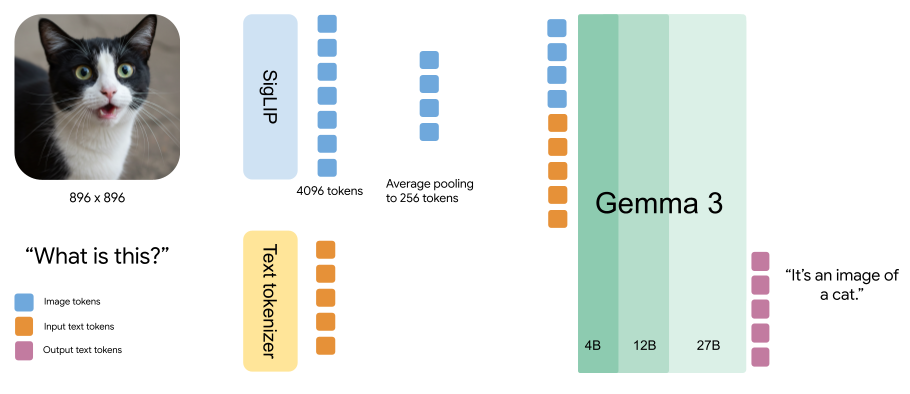
Gemma 3 の大きな機能強化は、新しいビジョン言語理解機能です。4B、12B、27B の各モデルには、カスタム SigLIP ビジョン エンコーダが組み込まれているので、モデルが視覚入力を解釈できます。
ビジョン エンコーダは、896x896 の固定サイズの正方形画像で動作します。異なるアスペクト比や高解像度画像を処理するために、「パン & スキャン」アルゴリズムを使います。つまり、画像の適応的クリッピングを行い、それぞれのサイズを 896x896 に変更したうえでエンコードします。この方法を使うと、特に詳しい情報が重要な場合に、パフォーマンスが向上します。ただし、推論時の計算オーバーヘッドは増加します。
さらに、Gemma 3 は、画像を MultiModalProjector が生成したコンパクトな「ソフトトークン」のシーケンスとして扱います。この技術では、視覚データを 256 個という一定の数のベクトルで表現することで、画像処理に必要な推論リソースを大幅に削減します。
ここで、「Gemma 3 と PaliGemma 2 はどう使い分けるべきか?」と疑問に思う方もいるかもしれません。
PaliGemma 2 の強みは、画像セグメンテーションやオブジェクト検出など、Gemma 3 にはない機能にあります。しかし、Gemma 3 は PaliGemma の技術を取り入れて拡張しているので、マルチターン チャット機能や強力なゼロショット性能を持ち合わせており、さまざまな視覚タスクを直接処理できます。
最終的な決定を下す際には、利用できる計算リソースに加えて、長いコンテキストや多言語サポートといった高度な機能の重要性も考慮する必要があります。このような高度な機能では、Gemma 3 が明らかに優れた性能を発揮します。
アーキテクチャが修正され、長いコンテキストで増加しがちな KV キャッシュ メモリ使用量が減少しています。
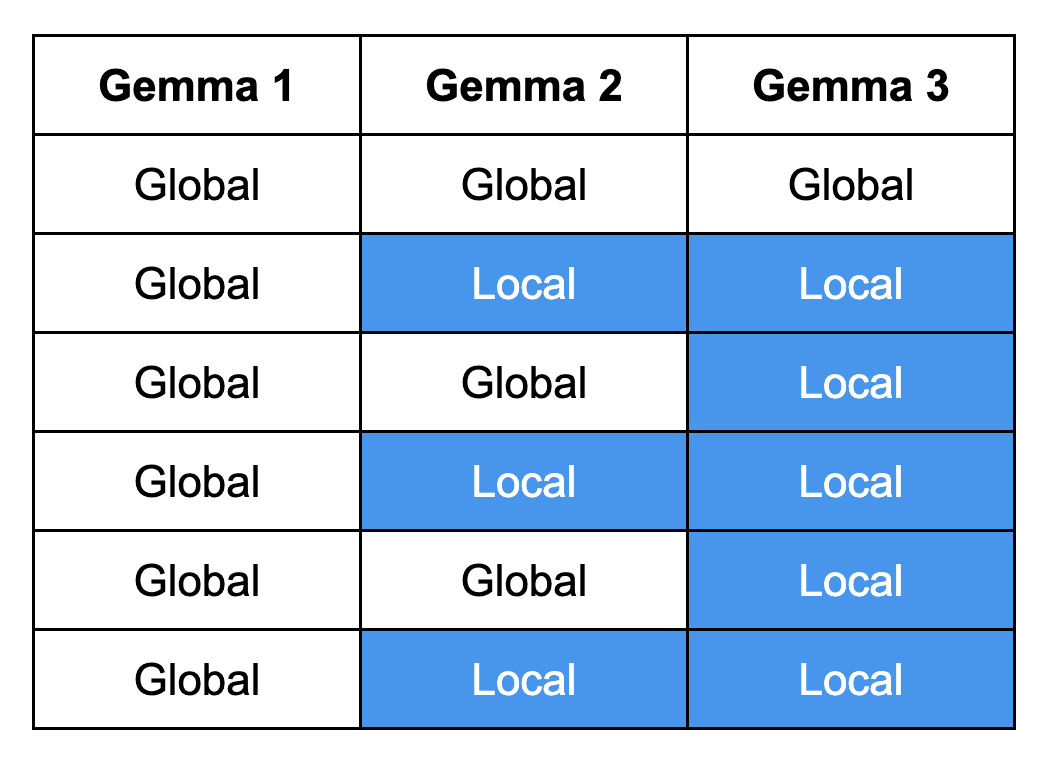
更新されたモデル アーキテクチャは、インターリーブ ブロックの繰り返しで構成されます。それぞれのブロックに、スライディング ウィンドウが 1024 のローカル アテンション レイヤ 5 つと、1 つのグローバル アテンション レイヤが含まれています。この設計により、モデルが短距離および長距離の両方の依存関係を把握できるので、文脈に即した正確な応答が可能になります。
注: Gemma 1 はグローバル アテンションのみを使っていましたが、Gemma 2 ではローカルとグローバルのアテンション レイヤを交互に利用するハイブリッドなアプローチが導入されました。Gemma 3 は、5 つの専用ローカル アテンション レイヤが組み込まれているので、文脈に即した正確な応答が可能になります。
Gemma 2 と Gemma 3 はどちらも、RMSNorm による post-norm と pre-norm を組み合わせたグループ化クエリ アテンション(GQA)を使っています。しかし、Gemma 3 は、Gemma 2 のソフトキャップ メカニズムの代わりに QK-norm を採用することで、精度の向上と処理速度の高速化の両方を実現しています。
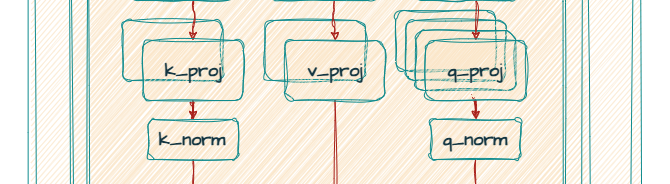
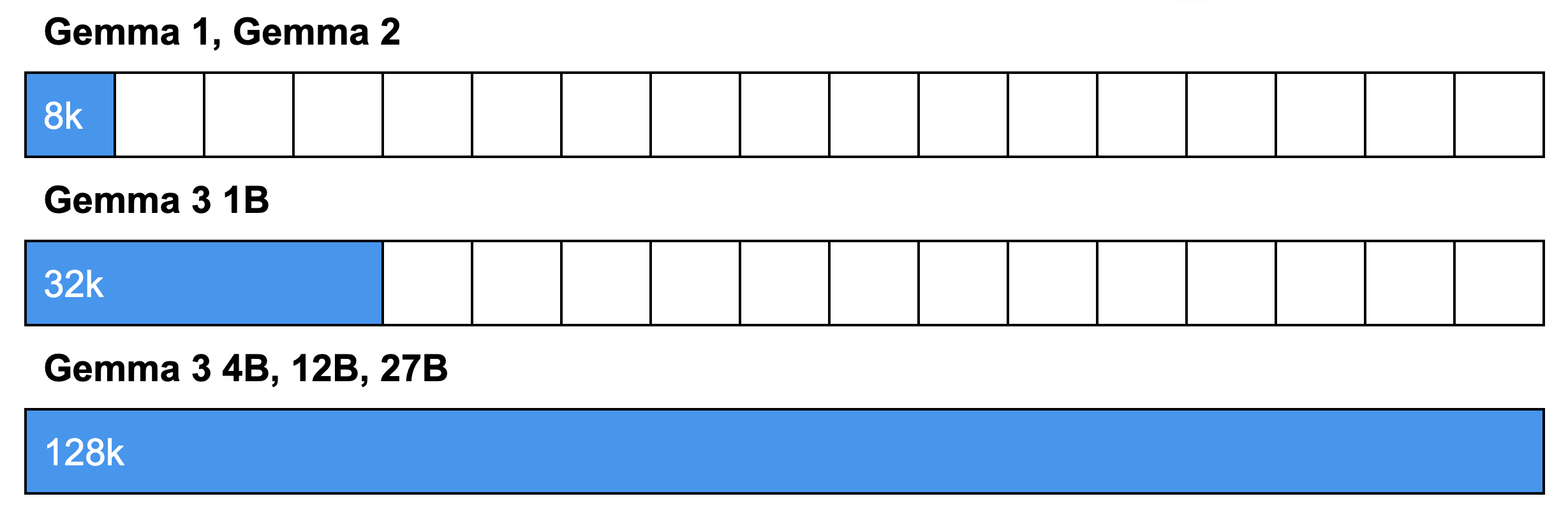
以上のアーキテクチャ変更が行われた結果、Gemma 3 は、インターリーブド アテンションでメモリ要件を低減し、コンテキスト長を拡大しています。これにより、文脈を失うことなく、長い文書や会話を分析できるようになります。具体的には、1B モデルでは 32k トークン、大型モデルでは 128k トークンを扱うことができます。
注: 128k トークン コンテキスト ウィンドウは、モデルが典型的な小説(単語数約 80k)と同等の長さのテキストを処理できることを意味します。このウィンドウ サイズは、約 96,000 ワード、198 ページ、画像 500 枚、1 fps で 8 分以上の動画に相当します。
Gemma 3 は、画像入力で双方向アテンションのみを利用します。
通常のアテンション(単方向アテンション)は、読書のようなものです。本を読んでいるところを想像してみてください。それぞれの単語を、それ以前に出てきた単語を踏まえて理解します。これが言語モデルにおける典型的なアテンションの仕組みです。シーケンシャルであり、後ろを見ながらコンテキストを作成しています。
一方、双方向アテンションはパズルを眺めるようなものです。画像をジグソーパズルと考えてみましょう。「画像トークン」は、個々のパズルのピースにあたります。各ピースは位置に関係なく、画像のすべてのピースを「見て」、つながっています。シーケンスだけを見るのではなく、全体像を一度に考慮します。すべての部分が他のすべての部分に関連しているため、全体を完全に理解することができます。
では、なぜ常に双方向にしないのでしょうか。双方向アテンション(コンテキスト全体を見る)の方が効果的に思えますが、テキストで必ず使われているとは限らず、タスク次第です。
主な違いは、双方向アプローチが使われるのはシーケンスを作成しないモデルであることです。
次のビジュアルは、Gemma 3 のアテンション メカニズムを図示しています。
コード:
from transformers.utils.attention_visualizer import AttentionMaskVisualizer
visualizer = AttentionMaskVisualizer("google/gemma-3-4b-it")
visualizer("<start_of_turn>user\n<img>What is this?<end_of_turn>\n<start_of_turn>model\nIt's an image of a cat.<end_of_turn>")出力:

また、このアテンション メカニズムが PaliGemma のアテンション メカニズムとどのように異なるかを確認することもできます。この比較に役立つように、背景をお伝えしましょう。PaliGemma は、テキストベースのタスクの説明(プロンプトまたはプレフィックス)と、1 つ以上の画像を受け取ります。そして、その予測をテキスト文字列(回答またはサフィックス)として自己回帰的に生成します。
コード:
visualizer = AttentionMaskVisualizer("google/paligemma2-3b-mix-224")
visualizer("<img> caption en", suffix="a cat standing on a beach.")出力:

Gemma 3 は多言語機能が改善されています。データの混合比率を見直し、多言語データ(単一言語と複数言語の両方)を増やしたからです。
Gemma 3 では、トークナイザーも改善しています。語彙サイズは 262k に変更されていますが、同じ SentencePiece トークナイザーを使います。エラーを回避するため、Gemma 3 では新しいトークナイザーをお使いください。これは Gemini と同じトークナイザーであり、英語以外の言語のバランスが向上しています。
Gemma3ForConditionalGeneration(
(vision_tower): SiglipVisionModel(
(vision_model): SiglipVisionTransformer(
(embeddings): SiglipVisionEmbeddings(
(patch_embedding): Conv2d(3, 1152, kernel_size=(14, 14), stride=(14, 14), padding=valid)
(position_embedding): Embedding(4096, 1152)
)
(encoder): SiglipEncoder(
(layers): ModuleList(
(0-26): 27 x SiglipEncoderLayer(
(self_attn): SiglipSdpaAttention(
(k_proj): Linear(in_features=1152, out_features=1152, bias=True)
(v_proj): Linear(in_features=1152, out_features=1152, bias=True)
(q_proj): Linear(in_features=1152, out_features=1152, bias=True)
(out_proj): Linear(in_features=1152, out_features=1152, bias=True)
)
(layer_norm1): LayerNorm((1152,), eps=1e-06, elementwise_affine=True)
(mlp): SiglipMLP(
(activation_fn): PytorchGELUTanh()
(fc1): Linear(in_features=1152, out_features=4304, bias=True)
(fc2): Linear(in_features=4304, out_features=1152, bias=True)
)
(layer_norm2): LayerNorm((1152,), eps=1e-06, elementwise_affine=True)
)
)
)
(post_layernorm): LayerNorm((1152,), eps=1e-06, elementwise_affine=True)
)
)
(multi_modal_projector): Gemma3MultiModalProjector(
(mm_soft_emb_norm): Gemma3RMSNorm((1152,), eps=1e-06)
(avg_pool): AvgPool2d(kernel_size=4, stride=4, padding=0)
)
(language_model): Gemma3ForCausalLM(
(model): Gemma3TextModel(
(embed_tokens): Gemma3TextScaledWordEmbedding(262208, 5376, padding_idx=0)
(layers): ModuleList(
(0-61): 62 x Gemma3DecoderLayer(
(self_attn): Gemma3Attention(
(q_proj): Linear(in_features=5376, out_features=4096, bias=False)
(k_proj): Linear(in_features=5376, out_features=2048, bias=False)
(v_proj): Linear(in_features=5376, out_features=2048, bias=False)
(o_proj): Linear(in_features=4096, out_features=5376, bias=False)
(q_norm): Gemma3RMSNorm((128,), eps=1e-06)
(k_norm): Gemma3RMSNorm((128,), eps=1e-06)
)
(mlp): Gemma3MLP(
(gate_proj): Linear(in_features=5376, out_features=21504, bias=False)
(up_proj): Linear(in_features=5376, out_features=21504, bias=False)
(down_proj): Linear(in_features=21504, out_features=5376, bias=False)
(act_fn): PytorchGELUTanh()
)
(input_layernorm): Gemma3RMSNorm((5376,), eps=1e-06)
(post_attention_layernorm): Gemma3RMSNorm((5376,), eps=1e-06)
(pre_feedforward_layernorm): Gemma3RMSNorm((5376,), eps=1e-06)
(post_feedforward_layernorm): Gemma3RMSNorm((5376,), eps=1e-06)
)
)
(norm): Gemma3RMSNorm((5376,), eps=1e-06)
(rotary_emb): Gemma3RotaryEmbedding()
(rotary_emb_local): Gemma3RotaryEmbedding()
)
(lm_head): Linear(in_features=5376, out_features=262208, bias=False)
)
)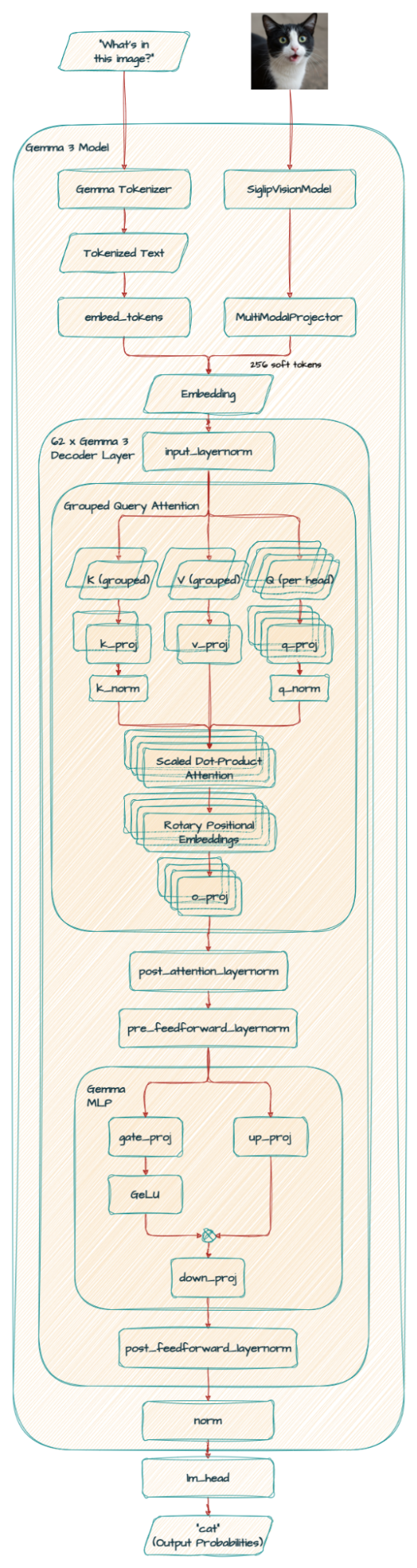
注: 実際には RoPE(回転位置エンベディング)は SDPA(スケールド ドット積アテンション)の中にありますが、図ではこの点を簡略化しています。詳しくは コードをご覧ください。 アーキテクチャが詳しく説明されています。
Gemma3ForCausalLM(
(model): Gemma3TextModel(
(embed_tokens): Gemma3TextScaledWordEmbedding(262144, 1152, padding_idx=0)
(layers): ModuleList(
(0-25): 26 x Gemma3DecoderLayer(
(self_attn): Gemma3Attention(
(q_proj): Linear(in_features=1152, out_features=1024, bias=False)
(k_proj): Linear(in_features=1152, out_features=256, bias=False)
(v_proj): Linear(in_features=1152, out_features=256, bias=False)
(o_proj): Linear(in_features=1024, out_features=1152, bias=False)
(q_norm): Gemma3RMSNorm((256,), eps=1e-06)
(k_norm): Gemma3RMSNorm((256,), eps=1e-06)
)
(mlp): Gemma3MLP(
(gate_proj): Linear(in_features=1152, out_features=6912, bias=False)
(up_proj): Linear(in_features=1152, out_features=6912, bias=False)
(down_proj): Linear(in_features=6912, out_features=1152, bias=False)
(act_fn): PytorchGELUTanh()
)
(input_layernorm): Gemma3RMSNorm((1152,), eps=1e-06)
(post_attention_layernorm): Gemma3RMSNorm((1152,), eps=1e-06)
(pre_feedforward_layernorm): Gemma3RMSNorm((1152,), eps=1e-06)
(post_feedforward_layernorm): Gemma3RMSNorm((1152,), eps=1e-06)
)
)
(norm): Gemma3RMSNorm((1152,), eps=1e-06)
(rotary_emb): Gemma3RotaryEmbedding()
(rotary_emb_local): Gemma3RotaryEmbedding()
)
(lm_head): Linear(in_features=1152, out_features=262144, bias=False)
)1B モデルはテキスト専用です。モバイルや組み込みシステムで高度な AI にアクセスできるように、オンデバイスでの利用に特化して最適化されています。ネットワーク接続が限られている場合や、まったく利用できない場合でも、AI 搭載アプリケーションを効率的に動作させることができるため、アクセシビリティ、プライバシー、パフォーマンスに大きな影響を与えることになります。
テクニカル レポートに詳しく記載されていますが、Gemma 3 から得られた主な知見は次のとおりです。
Gemma 3 のアーキテクチャ、とりわけ以前のバージョンとは異なる新機能について詳しく説明しました。こういったアーキテクチャを選んだことで、Gemma 3 は、多言語能力が改善し、画像インタラクションなどの幅広いタスクのパフォーマンスが向上しています。それと同時に、標準的なハードウェアで動作し、リソース フレンドリーで機能的なマルチモーダル言語モデルに向かう道が開かれています。
研究者やデベロッパーは、Gemma 3 のイノベーションによって、強力で効率的な次世代のマルチモーダル言語モデルを作成できるようになると確信しています。
お読みいただき、ありがとうございました!

EmbeddingGemma の概要: オンデバイス埋め込み処理向けの最高水準オープンモデル

Building with Gemini 3 in Jules
Coral NPU のご紹介: エッジ AI 向けフルスタック プラットフォーム

Gemma 3 270M の概要: 超高効率 AI のためのコンパクト モデル

Announcing the Data Commons Gemini CLI extension

Introducing Metrax: performant, efficient, and robust model evaluation metrics in JAX