

Google에서는 높은 모델 범위 및 CPU 성능을 가진 PyTorch에서 TensorFlow Lite(TFLite) 런타임으로 직접 경로인 Google AI Edge Torch를 발표하게 되었습니다. TFLite는 이미 JAX, Keras 및 TensorFlow로 작성된 모델과 함께 작동하며, 이제 프레임워크 옵션에 대한 광범위한 노력의 일부분으로 PyTorch를 추가하게 되었습니다.
이 새로운 제공은 이제 Google AI Edge의 일부분으로 사용할 수 있습니다. Google AI Edge는 온디바이스에서 즉시 사용할 수 있는 ML 작업에 간편하게 액세스하는 도구의 모음이며 ML 파이프라인을 구축하고 인기 있는 LLM 및 사용자 지정 모델을 실행할 수 있는 프레임워크입니다. 이 블로그 게시물은 Google AI Edge 릴리스에 대한 여러 블로그 중 첫 번째 게시물이며 개발자들이 AI를 사용하는 기능을 구축하여 여러 플랫폼에 쉽게 배포하는 데 도움이 될 것입니다.
AI Edge Torch가 오늘 베타 버전으로 릴리스되며 다음과 같은 기능을 포함합니다.
Google AI Edge Torch는 네이티브처럼 느껴지는 API를 제공하여 PyTorch 커뮤니티에 훌륭한 경험을 제공하고 간편한 전환 경로를 제공하기 위해 새로 구축되었습니다.
import torchvision
import ai_edge_torch
# 모델 초기화
resnet18 = torchvision.models.resnet18().eval()
# 변환
sample_input = (torch.randn(4, 3, 224, 224),)
edge_model = ai_edge_torch.convert(resnet18, sample_input)
# Python에서 추론
output = edge_model(*sample_input)
# 온디바이스 배포를 위해 TfLite 모델로 내보내기
edge_model.export('resnet.tflite'))작동을 위해 ai_edge_torch.convert()는 torch.export를 사용하여 TorchDynamo와 통합되며 이것은 PyTorch 모델을 다른 환경에서 실행하도록 의도된 표준화된 모델 표현으로 내보내는 PyTorch 2.x의 방식입니다. 현재 구현은 core_aten 연산자의 60% 이상을 지원하며 ai_edge_torch 1.0 릴리스가 가까워질수록 지원 범위를 더욱 늘릴 것입니다. PT2E 양자화를 보여주는 예를 포함했으며 이것은 간편한 양자화 워크플로를 사용하는 PyTorch2의 네이티브 양자화 접근 방식입니다. PyTorch에서 시작하여 다양한 종류의 기기에 혁신을 가져오는 개발자 경험을 향상시킬 수 있는 방법을 찾기 위해 PyTorch 커뮤니티의 의견을 듣기를 기대합니다.
이 릴리스 이전에는 많은 개발자들이 ONNX2TF와 같은 커뮤니티에서 제공하는 경로를 사용하여 TFLite에서 PyTorch 모델을 사용했습니다. AI Edge Torch를 개발하는 목표는 개발자 마찰을 줄이고 훌륭한 모델 범위를 제공하며 Android 기기에서 동급 최고의 성능을 제공한다는 임무를 계속하는 것이었습니다.
범위에 대한 자체 테스트에서는 기존 워크플로우, 특히 ONNX2TF에 비해 정의된 모델의 집합에 대해 상당히 항샹된 것으로 증명되었습니다.
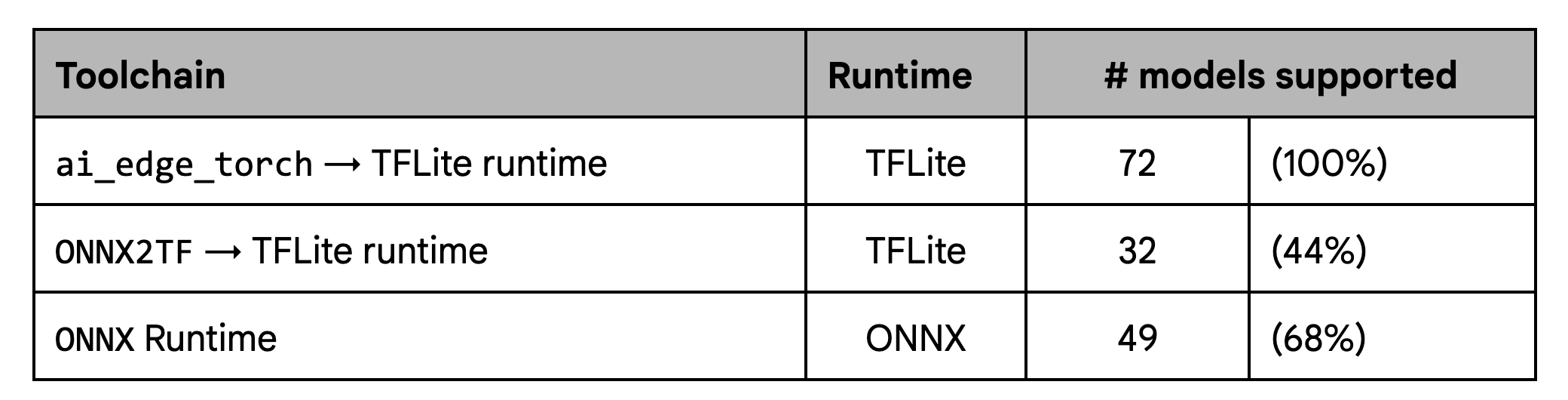
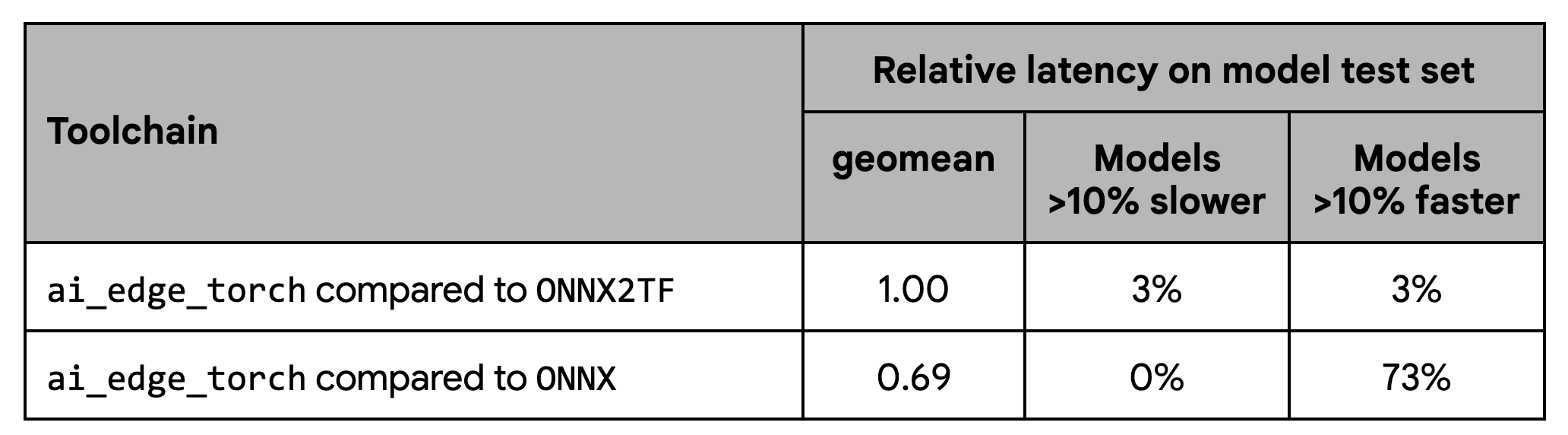
성능에 대한 자체 테스트에서는 ONNX2TF 기준선과 일관된 성능을 보여주며 ONNX 런타임보다 의미 있게 더 나은 성능을 보여줍니다.
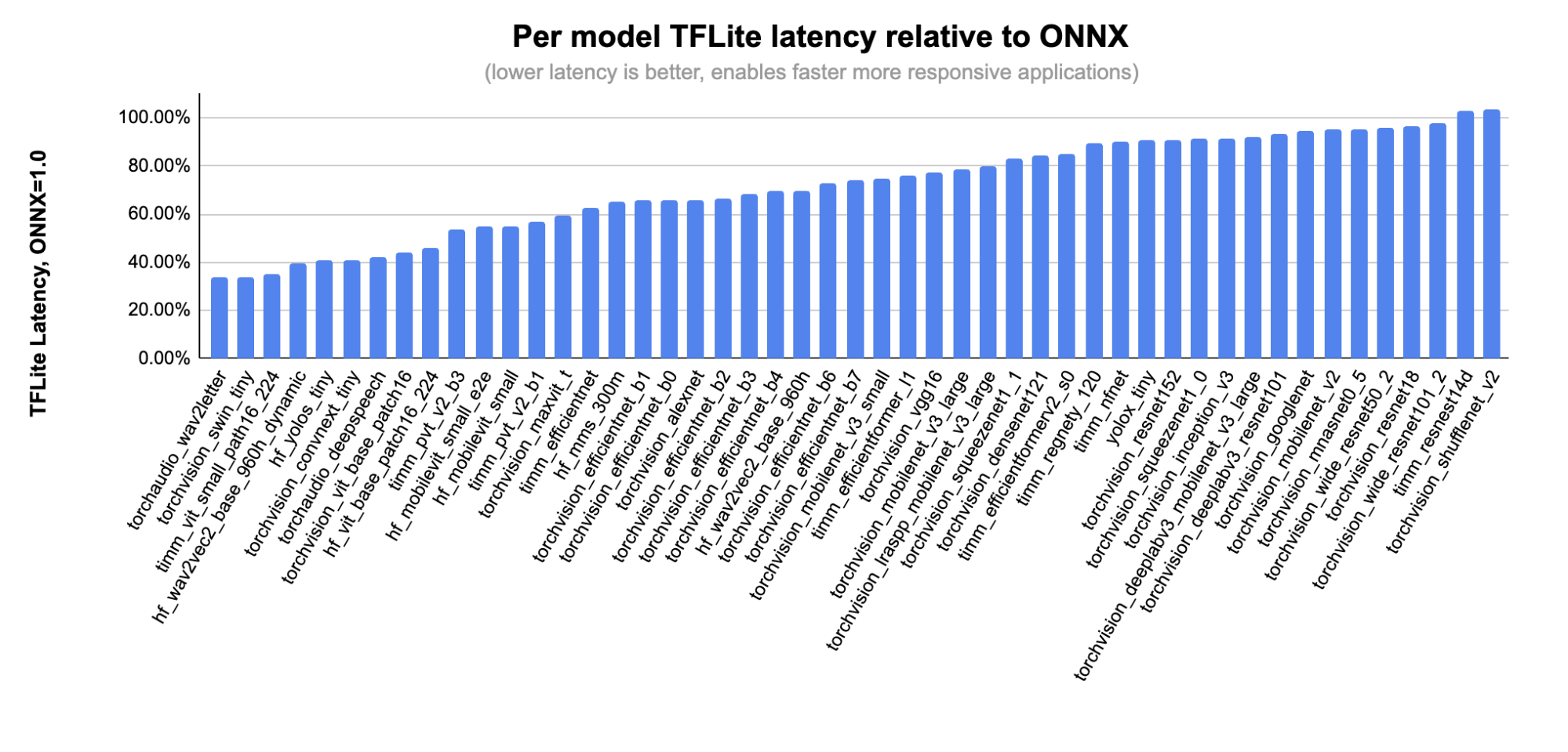
다음은 ONNX에서 지원하는 모델의 하위 집합에 대한 모델별 세부 성능을 보여줍니다.
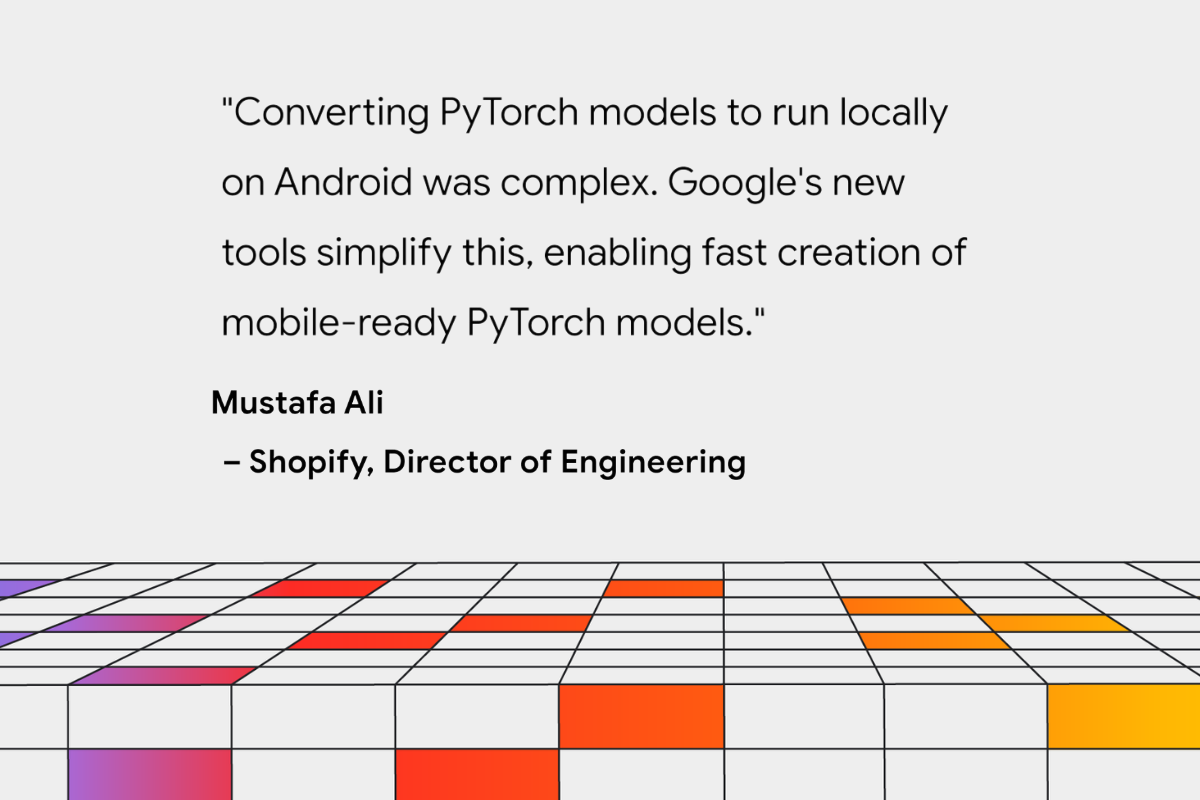
지난 몇 개월 동안 저희는 PyTorch 지원을 개선하기 위해 Shopify, Adobe 및 Niantic을 포함한 조기 도입 파트너와 긴밀히 협력했습니다. ai_edge_torch는 이미 Shopify에서 제품 이미지에 대한 기기 내 백그라운드 제거를 수행하는 데 사용되고 있으며 곧 Shopify 앱의 다음 릴리스에서 사용할 수 있을 것입니다.
저희는 또한 파트너와 긴밀히 협력하여 ARM, Google Tensor G3, MediaTek, Qualcomm 및 Samsung System LSI를 포함한 CPU, GPU 및 가속기 전반에 걸친 하드웨어 지원을 위해 노력했습니다. 이러한 파트너십을 통해 성능과 범위를 개선하고 가속기 델리게이트에서 PyTorch가 생성한 TFLite 파일을 검증했습니다.
또한 저희는 Qualcomm의 새로운 TensorFlow Lite 델리게이트를 공동으로 발표하게 되었으며 여기에 공개되어 모든 개발자들에게 사용 가능합니다. TFLite 델리게이트는 GPU 및 하드웨어 가속기에서 실행을 가속화하는 부가 기능 소프트웨어 모듈입니다. 이 새로운 QNN 델리게이트는 PyTorch 베타 테스트 세트의 대부분의 모델을 지원하는 동시에 광범위한 Qualcomm 실리콘들을 지원하며 Qualcomm의 DSP 및 신경 처리 장치를 활용하여 CPU(20x) 및 GPU(5x)와 비교하여 상당한 평균 속도 향상을 제공합니다. 테스트를 쉽게 하기 위해 Qualcomm은 최근 새로운 AI 허브도 릴리스했습니다. Qualcomm AI Hub는 개발자가 광범위한 Android 기기에 대해 TFLite 모델을 테스트할 수 있는 클라우드 서비스이며, QNN 델리게이트를 사용하여 다양한 기기에서 사용할 수 있는 성능 향상에 대한 가시성을 제공합니다.
앞으로 몇 달 동안 저희는 1.0 릴리스까지 빌드하면서 모델 범위를 확장하고 GPU 지원을 개선하며 새로운 양자화 모드를 사용하는 릴리스를 공개적으로 계속 반복할 것입니다. 이 시리즈의 파트 2에서는 개발자가 높은 성능으로 엣지까지 사용자 지정 GenAI 모델을 제공할 수 있는 AI Edge Torch 생성형 API를 자세히 살펴보겠습니다.
초기 버그를 잡고 원활한 개발자 경험을 보장하는 데 도움이 되는 소중한 피드백을 주신 모든 얼리액세스 고객에게 감사드립니다. 또한 광범위한 장치에서 성능을 개선하는 데 도움을 준 XNNPACK의 하드웨어 파트너 및 생태계 기여자에게도 감사드립니다. 또한 더 넓게 Pytorch 커뮤니티의 안내와 지원에 감사드립니다.
감사의 말
이 작업에 기여한 모든 팀원들에게 감사합니다 - Aaron Karp, Advait Jain, Akshat Sharma, Alan Kelly, Arian Arfaian, Chun-nien Chan, Chuo-Ling Chang, Claudio Basille, Cormac Brick, Dwarak Rajagopal, Eric Yang, Gunhyun Park, Han Qi, Haoliang Zhang, Jing Jin, Juhyun Lee, Jun Jiang, Kevin Gleason, Khanh LeViet, Kris Tonthat, Kristen Wright, Lu Wang, Luke Boyer, Majid Dadashi, Maria Lyubimtseva, Mark Sherwood, Matthew Soulanille, Matthias Grundmann, Meghna Johar, Milad Mohammadi, Na Li, Paul Ruiz, Pauline Sho, Ping Yu, Pulkit Bhuwalka, Ram Iyengar, Sachin Kotwani, Sandeep Dasgupta, Sharbani Roy, Shauheen Zahirazami, Siyuan Liu, Vamsi Manchala, Vitalii Dziuba, Weiyi Wang, Wonjoo Lee, Yishuang Pang, Zoe Wang 및 StableHLO 팀.

Announcing the Data Commons Gemini CLI extension

LiteRT-LM이 탑재된 Chrome, Chromebook Plus, Pixel Watch의 온디바이스 생성형 AI

멀티모달리티, RAG, 함수 호출을 제공하는 온디바이스 소규모 언어 모델

LiteRT: 성능은 극대화하고, 사용은 간편하게

Building with Gemini 3 in Jules

Google AI Edge Gallery: 이제 오디오와 Google Play에서 사용 가능