

개발자가 새로운 기기 내 생성형 AI 모델을 에지 기기에 원활하게 도입하도록 지원할 수 있게 되어 기쁩니다. 그러한 요구에 부응하고자 AI Edge Torch Generative API를 선보입니다. 이것은 개발자가 TensorFlow Lite(TFLite) 런타임을 사용해 배포를 위해 PyTorch에서 고성능 LLM을 작성할 수 있게 해주는 API입니다. 이 글은 Google AI Edge 개발자 릴리스를 다루는 블로그 게시물 시리즈의 두 번째 편입니다. 시리즈의 첫 편에서는 TFLite 런타임을 사용하여 모바일 기기에서 PyTorch 모델의 고성능 추론을 지원하는 Google AI Edge Torch를 소개했습니다.
개발자는 AI Edge Torch Generative API를 사용해 요약, 콘텐츠 생성 등의 강력하고 새로운 기능을 기기 내 기능으로 제공할 수 있습니다. 저희는 이미 개발자가 MediaPipe LLM Inference API를 사용하여 가장 인기 있는 LLM 몇 가지를 기기에 적용할 수 있도록 지원하고 있습니다. 이제는 개발자가 지원되는 모든 모델을 뛰어난 성능으로 기기에 적용할 수 있습니다. AI Edge Torch Generative API의 초기 버전은 다음을 제공합니다.
이 블로그 게시물에서는 성능, 이식성, 개발자 경험 작성, 엔드 투 엔드 추론 파이프라인, 디버그 도구 모음에 대해 자세히 알아보겠습니다. 자세한 설명서와 예시는 여기에서 확인할 수 있습니다.
MediaPipe LLMInference API를 통해 가장 인기 있는 LLM 일부가 원활하게 작동하도록 하기 위한 작업의 일환으로서, 저희 팀은 기기 성능에 대한 최첨단 기술을 갖춘 여러 트랜스포머의 코드를 온전히 수작업으로 작성했습니다(MediaPipe LLM Inference API 블로그). 이 작업에서 주목도를 효과적으로 표현하는 방법, 양자화 사용, 좋은 KV 캐시 표현의 중요성 등 몇 가지 테마가 등장했습니다. 다음 섹션에서 볼 수 있듯이 Generative API를 사용하면 이러한 각 항목을 쉽게 표현하면서도 여전히 훨씬 더 빠른 개발자 속도로 수작업 버전의 90%를 초과하는 성능을 달성할 수 있습니다.
다음 표는 3가지 모델 예시를 통해 업계의 주요 기준치를 보여줍니다.
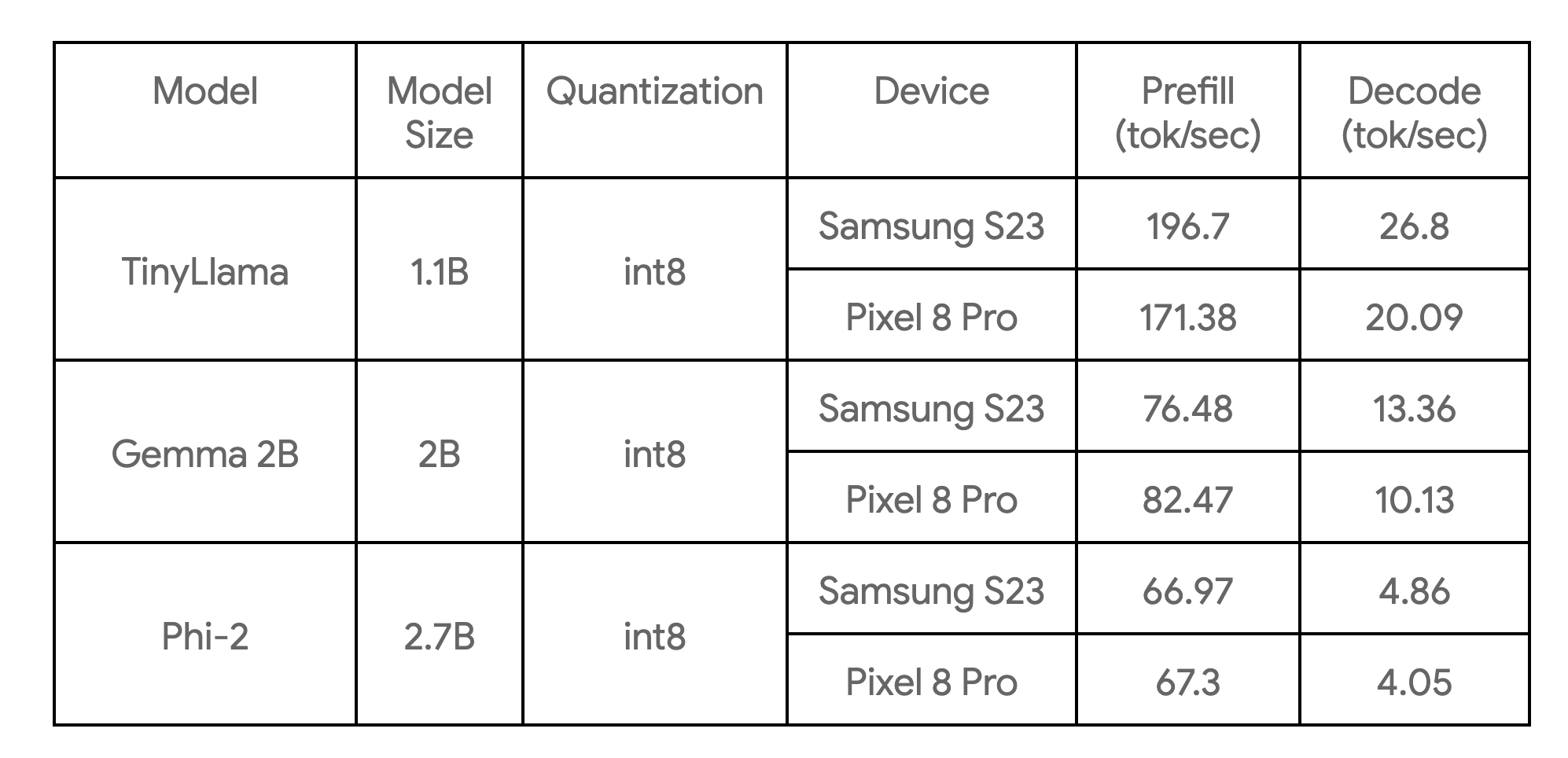
이들은 4개의 CPU 스레드가 있는 대형 코어에서 벤치마킹되며 현재 열거된 기기에서 우리가 알고 있는 이 모델들의 가장 빠른 CPU 구현입니다.
코어 저작 라이브러리는 일반적인 트랜스포머 모델(인코더 전용, 디코더 전용 또는 인코더-디코더 스타일 등)에 대한 기본 구성 요소를 제공합니다. 이를 통해 처음부터 모델을 작성하거나 성능 향상을 위해 기존 모델을 재작성할 수 있습니다. 학습/미세 조정 단계가 불필요하므로 대부분의 사용자는 다시 작성하는 것이 좋습니다. Generative API 작성의 주요 이점은 다음과 같습니다.
예를 들어, 여기서는 새로운 Generative API를 사용해 약 50줄의 Python으로 TinyLLama(1.1B)의 핵심 기능을 재작성하는 방법을 보여 드리겠습니다.
1단계: 모델 구조 정의
import torch
import torch.nn as nn
from ai_edge_torch.generative.layers.attention import TransformerBlock
import ai_edge_torch.generative.layers.attention_utils as attn_utils
import ai_edge_torch.generative.layers.builder as builder
import ai_edge_torch.generative.layers.model_config as cfg
class TinyLLamma(nn.Module):
def __init__(self, config: cfg.ModelConfig):
super().__init__()
self.config = config
# 모델 계층 생성.
self.lm_head = nn.Linear(
config.embedding_dim, config.vocab_size, bias=config.lm_head_use_bias
)
self.tok_embedding = nn.Embedding(
config.vocab_size, config.embedding_dim, padding_idx=0
)
self.transformer_blocks = nn.ModuleList(
TransformerBlock(config) for _ in range(config.num_layers)
)
self.final_norm = builder.build_norm(
config.embedding_dim,
config.final_norm_config,
)
self.rope_cache = attn_utils.build_rope_cache(
size=config.kv_cache_max,
dim=int(config.attn_config.rotary_percentage * config.head_dim),
base=10_000,
condense_ratio=1,
dtype=torch.float32,
device=torch.device("cpu"),
)
self.mask_cache = attn_utils.build_causal_mask_cache(
size=config.kv_cache_max, dtype=torch.float32, device=torch.device("cpu")
)
self.config = config2단계: 모델의 forward 함수 정의
@torch.inference_mode
def forward(self, idx: torch.Tensor, input_pos: torch.Tensor) -> torch.Tensor:
B, T = idx.size()
cos, sin = self.rope_cache
cos = cos.index_select(0, input_pos)
sin = sin.index_select(0, input_pos)
mask = self.mask_cache.index_select(2, input_pos)
mask = mask[:, :, :, : self.config.kv_cache_max]
# 모델 자체를 전달
x = self.tok_embedding(idx) # 모양 (b, t, n_embd)의 토큰 임베딩
for i, block in enumerate(self.transformer_blocks):
x = block(x, (cos, sin), mask, input_pos)
x = self.final_norm(x)
res = self.lm_head(x) # (b, t, vocab_size)
return res3단계: 이전 모델 가중치 매핑
라이브러리를 사용하면 ModelLoader API로 가중치를 쉽게 매핑할 수 있으며, 예시는 다음과 같습니다.
import ai_edge_torch.generative.utilities.loader as loading_utils
# 이 맵은 이전 텐서 이름을 새 모델과 연결합니다.
TENSOR_NAMES = loading_utils.ModelLoader.TensorNames(
ff_up_proj="model.layers.{}.mlp.up_proj",
ff_down_proj="model.layers.{}.mlp.down_proj",
ff_gate_proj="model.layers.{}.mlp.gate_proj",
attn_query_proj="model.layers.{}.self_attn.q_proj",
attn_key_proj="model.layers.{}.self_attn.k_proj",
attn_value_proj="model.layers.{}.self_attn.v_proj",
attn_output_proj="model.layers.{}.self_attn.o_proj",
pre_attn_norm="model.layers.{}.input_layernorm",
pre_ff_norm="model.layers.{}.post_attention_layernorm",
embedding="model.embed_tokens",
final_norm="model.norm",
lm_head="lm_head",
)이러한 단계가 완료되면 몇 가지 샘플 입력을 실행하여 재작성된 모델의 수치 정확성(링크 참조)을 확인할 수 있습니다. 수치 검사를 통과하면 변환 및 양자화 단계를 진행할 수 있습니다.
ai_edge_torch에서 제공되는 변환 API를 사용하면 동일한 API를 활용하여 트랜스포머 모델을 고도로 최적화된 TensorFlow Lite 모델로 변환(재작성)할 수 있습니다. 변환 프로세스에는 다음과 같은 주요 단계가 포함됩니다.
1) StableHLO로 내보냅니다. PyTorch 모델은 토치 다이나모(torch dynamo) 컴파일러에 의해 Aten 연산이 있는 FX Graph로 추적 및 컴파일된 다음 ai_edge_torch를 통해 더 구체적인 StableHLO 그래프로 변환됩니다.
2) ai_edge_torch는 연산 융합/접기 등을 포함해 StableHLO에서 추가적인 컴파일러 패스를 실행하고 고성능 TFLite flatbuffer를 생성합니다(SDPA 및 KVCache를 위한 융합 연산 포함).
또한 코어 Generative API 라이브러리는 일반적인 LLM 양자화 레시피를 다루는 일련의 양자화 API도 제공합니다. 레시피는 ai_edge_torch 변환기 API에 추가 매개변수를 받는데, 이 매개변수는 양자화를 자동으로 처리합니다. 향후 버전에서는 사용 가능한 양자화 모드 세트를 확장할 것으로 예상합니다.
저희는 실제 추론 시나리오에서 LLM 모델이 최상의 서비스 제공 성능을 달성하려면 명확하게 분리된(분해된) 추론 함수(프리필, 디코드)가 있어야 한다는 점을 파악했습니다. 이는 부분적으로 프리필/디코드가 다른 텐서 모양을 취할 수 있다는 관찰에 기초합니다. 프리필은 컴퓨팅 바운드인 반면 디코드는 메모리 바운드이죠. 대형 LLM의 경우, 프리필/디코드 간에 모델 가중치가 중복되지 않도록 하는 것이 중요합니다. 아래에서 보듯이 모델에 대한 여러 진입점을 쉽게 정의할 수 있게 해주는 TFLite 및 ai_edge_torch의 기존 다중 서명 기능을 사용하여 이런 목표를 달성합니다.
def convert_tiny_llama_to_tflite(
prefill_seq_len: int = 512,
kv_cache_max_len: int = 1024,
quantize: bool = True,
):
pytorch_model = tiny_llama.build_model(kv_cache_max_len=kv_cache_max_len)
# 변환 중 모델 그래프 추적에 사용되는 텐서.
prefill_tokens = torch.full((1, prefill_seq_len), 0, dtype=torch.long)
prefill_input_pos = torch.arange(0, prefill_seq_len)
decode_token = torch.tensor([[0]], dtype=torch.long)
decode_input_pos = torch.tensor([0], dtype=torch.int64)
# 모델의 양자화 설정.
quant_config = quant_recipes.full_linear_int8_dynamic_recipe() if quantize else None
edge_model = (
ai_edge_torch.signature(
'prefill', pytorch_model, (prefill_tokens, prefill_input_pos)
)
.signature('decode', pytorch_model, (decode_token, decode_input_pos))
.convert(quant_config=quant_config)
)
edge_model.export(f'/tmp/tiny_llama_seq{prefill_seq_len}_kv{kv_cache_max_len}.tflite')성능 조사 단계에서 다음과 같이 LLM 성능 개선을 위한 중요 사항 몇 가지를 발견했습니다.
1) 고성능 SDPA 및 KVCache: 이러한 함수에서의 세분화된 연산을 고려할 때 충분한 컴파일러 최적화/융합이 없으면 변환된 TFLite 모델이 큰 성능을 발휘하지 못할 것임을 알게 되었습니다. 이 문제를 해결하기 위해 상위 수준 함수 경계와 StableHLO 복합 연산을 도입했습니다.
2) TFLite의 XNNPack 대리자를 활용하여 SDPA를 더욱 가속화: 무거운 MatMul/Matrix-vector 계산이 잘 최적화되도록 하는 것이 중요합니다. XNNPack 라이브러리는 광범위한 모바일 CPU에서 이러한 기본 연산의 성능이 탁월합니다.
3) 낭비적인 계산 방지: 모델이 프리필 단계에서 고정 입력 메시지 크기가 길거나 디코드 단계에서 고정 시퀀스 길이가 큰 경우, 정적 형상 모델은 최소로 필요한 것 이상의 컴퓨팅을 유도할 수 있습니다.
4) 런타임 메모리 소비. TFLite의 XNNPack 대리자에 가중치 캐싱/사전 압축 메커니즘을 도입하여 최대 메모리 사용량을 대폭 줄였습니다.
LLM 추론은 보통 많은 사전/사후 처리 단계와 정교한 오케스트레이션(예: 토큰화, 샘플링, 자동 회귀 디코딩 논리)을 포함합니다. 이를 위해 MediaPipe 기반 솔루션과 순수 C++ 추론 예시를 모두 제공합니다.
MediaPipe LLM Inference API는 프롬프트 인/프롬프트 아웃 인터페이스를 사용하여 LLM 추론을 지원하는 상위 수준 API입니다. 이 API는 내부적으로 LLM 파이프라인을 구현하는 모든 복잡성을 처리하고 배포를 훨씬 쉽고 원활하게 만듭니다. MP LLM Inference API를 사용하여 배포하려면 예상되는 프리필 및 디코드 서명을 사용하여 모델을 변환하고 아래 코드에 나타낸 것과 같은 번들을 생성해야 합니다.
def bundle_tinyllama_q8():
output_file = "PATH/tinyllama_q8_seq1024_kv1280.task"
tflite_model = "PATH/tinyllama_prefill_decode_hlfb_quant.tflite"
tokenizer_model = "PATH/tokenizer.model"
config = llm_bundler.BundleConfig(
tflite_model=tflite_model,
tokenizer_model=tokenizer_model,
start_token="<s>",
stop_tokens=["</s>"],
output_filename=output_file,
enable_bytes_to_unicode_mapping=False,
)
llm_bundler.create_bundle(config)또한 저희는 사용하기 쉬운 C++ 예제(MediaPipe 종속성 없음)를 제공하여 엔드 투 엔드 텍스트 생성 예제 코드를 실행하는 방법도 보여드립니다. 개발자는 내보낸 모델을 고유한 프로덕션 파이프라인 및 요구 사항과 통합하기 위한 출발점으로 이 예시 코드를 이용해서 더 나은 사용자 설정과 유연성을 획득할 수 있습니다.
코어 추론 런타임이 TFLite에 있으므로 수정 없이 전체 파이프라인을 (Google Play에 포함된) Android 또는 iOS 앱에 쉽게 통합할 수 있습니다. 이렇게 하면 몇 가지 사용자 설정 연산 종속성만 추가하여 새로운 Generative API에서 변환된 모델을 즉시 배포할 수 있습니다. 향후 릴리스에서는 Android 및 iOS와 대상 ML 가속기(TPU, NPU)에도 GPU 지원을 제공할 예정입니다.
최근 발표된 Model Explorer는 Gemma 2B와 같은 대형 모델을 시각화하는 데 유용한 도구입니다. 계층적 보기와 병렬 비교 기능을 통해 원본/재작성/변환된 모델 버전을 쉽게 시각화할 수 있습니다. 이에 대한 자세한 내용과 성능 튜닝을 위해 업계 기준치 정보를 시각화하는 방법은 이 블로그 게시물을 참조하세요.
아래는 PyTorch TinyLlama 모델을 작성할 때 이를 사용한 예로, TFLite 모델과 더불어 PyTorch export() 모델을 보여줍니다. Model Explorer를 사용하면 각 레이어(예: RMSNorms, SelfAttention)의 표현 방식을 쉽게 비교할 수 있습니다.
AI Edge Torch Generative API는 기기에서 자체적인 생성형 AI 모델을 사용하려는 개발자를 위해 Mediapipe LLM Inference API에서 사용 가능한 최적화된 모델을 사전 작성하는 강력한 동반자입니다. 앞으로 몇 달에 걸쳐 웹 지원, 향상된 양자화, CPU 이상의 광범위한 컴퓨팅 지원 등 새로운 업데이트가 이어질 것으로 예상합니다. 더 나은 프레임워크 통합을 모색하는 것 또한 저희의 관심사입니다.
이것은 개발자 커뮤니티 참여를 목표로 실험 단계에 있는 라이브러리의 초기 미리보기입니다. API가 변경될 수도, 마무리가 미진할 수도, 양자화와 모델에 대한 지원이 제한적일 수도 있음을 양해해 주세요. 그러나 GitHub 리포지토리에는 일단 시작해 볼 수 있는 많은 것이 이미 공개되어 있으므로 PR, 각종 문제 보고, 기능 요청 사항을 자유롭게 공유해 주시기 바랍니다.
본 시리즈의 세 번째 편에서는 개발자가 모델을 시각화, 디버그, 탐색할 수 있게 지원하는 Model Explorer 시각화 도구에 대해 자세히 살펴보겠습니다.
이 작업을 위해 Google의 다양한 기능 팀들이 힘을 합했습니다. Aaron Karp, Advait Jain, Akshat Sharma, Alan Kelly, Andrei Kulik, Arian Afaian, Chun-nien Chan, Chuo-Ling Chang, Cormac Brick, Eric Yang, Frank Barchard, Gunhyun Park, Han Qi, Haoliang Zhang, Ho Ko, Jing Jin, Joe Zoe, Juhyun Lee, Kevin Gleason, Khanh LeViet, Kris Tonthat, Kristen Wright, Lin Chen, Linkun Chen, Lu Wang, Majid Dadashi, Manfei Bai, Mark Sherwood, Matthew Soulanille, Matthias Grundmann, Maxime Brénon, Michael Levesque-Dion, Mig Gerard, Milen Ferev, Mohammadreza Heydary, Na Li, Paul Ruiz, Pauline Sho, Pei Zhang, Ping Yu, Pulkit Bhuwalka, Quentin Khan, Ram Iyengar, Renjie Wu, Rocky Rhodes, Sachin Kotwani, Sandeep Dasgupta, Sebastian Schmidt, Siyuan Liu, Steven Toribio, Suleman Shahid, Tenghui Zhu, T.J. Alumbaugh, Tyler Mullen, Weiyi Wang, Wonjoo Lee, Yi-Chun Kuo, Yishuang Pang, Yu-hui Chen, Zoe Wang, Zichuan Wei를 포함하여 이번 작업에 기여해 주신 모든 팀원 여러분께 감사드립니다.

LiteRT-LM이 탑재된 Chrome, Chromebook Plus, Pixel Watch의 온디바이스 생성형 AI

멀티모달리티, RAG, 함수 호출을 제공하는 온디바이스 소규모 언어 모델

Announcing the Agent Development Kit for Go: Build Powerful AI Agents with Your Favorite Languages

LiteRT: 성능은 극대화하고, 사용은 간편하게

Google AI Edge Gallery: 이제 오디오와 Google Play에서 사용 가능

Announcing User Simulation in ADK Evaluation