

昨年リリースした ShieldGemma は、安全コンテンツ分類モデルのスイートです。Gemma 2 をベースに開発されており、AI モデルのテキスト入出力から有害なコンテンツを検出するように設計されています。本日は、Gemma 3 のデビューに合わせて、ShieldGemma 2 を発表します。これは、責任ある AI の基盤を強化することにつながります。
Link to Youtube Video (visible only when JS is disabled)
ShieldGemma 2 は、Gemma 3 をベースとした 40 億(4B)パラメータのモデルです。主要なカテゴリに対して合成画像や自然画像の安全性をチェックできるので、堅牢なデータセットやモデルを作成する際に役立ちます。Gemma ファミリーにこのモデルが追加されたことで、研究者やデベロッパーは次のような主要な有害領域において、有害なコンテンツによるリスクを簡単に最小化できます。

ShieldGemma 2 を視覚言語モデルの入力フィルタ、または画像生成システムの出力フィルタとして使うことをおすすめします。合成画像と自然画像の両方で利用できます。
テキストだけでなく、マルチモーダル モデルでの画像の安全性をトレーニングして理解しようとすると、新しい課題に直面することになります。ShieldGemma 2 が微妙な意味合いを含むさまざまなスタイルの画像に対応できるように作られているのは、そのためです。
堅牢な画像安全性モデルをトレーニングするため、自然画像と合成画像のトレーニング データセットを慎重に準備し、Gemma 3 をインストラクション チューニングすることで強力なパフォーマンスを実現しました。安全ポリシーを次のベンチマークと比較したほか、サードパーティのベンチマークも組み込んだテクニカル レポートも公開予定です。
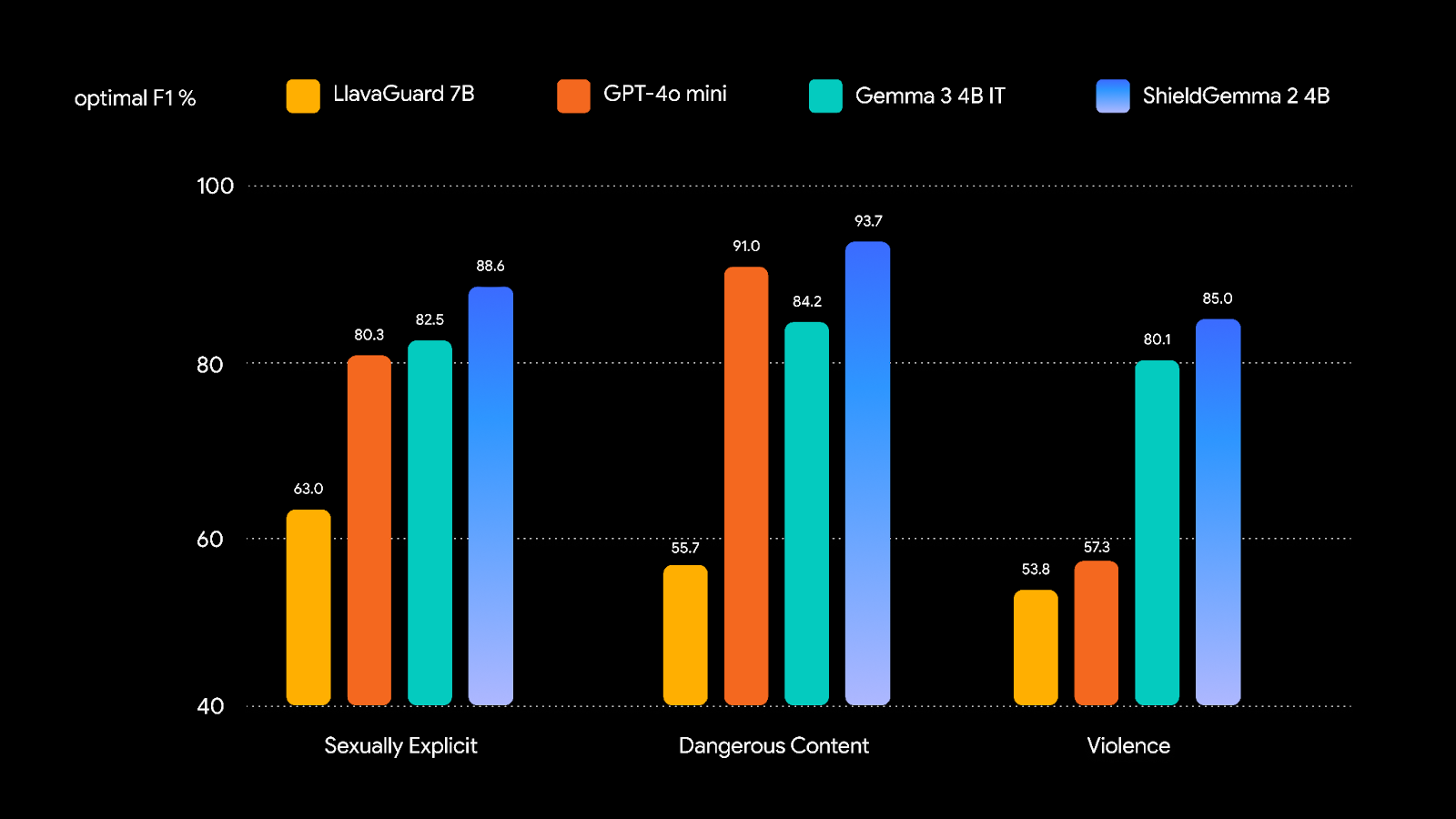
責任ある形でオープンモデルを導入できるかどうかは、コミュニティ全体の努力次第です。ShieldGemma 2 がさらに小さなサイズで多くの有害領域に対応できるようになることを楽しみにしています。近い将来には、マルチモーダル ML コモンズ分類法とも一致させる予定です。
安全で責任あるマルチモーダル AI の開発が続くことが楽しみです。
Wenjun Zeng、Ryan Mullins、Dana Kurniawan、Yuchi Liu、Mani Malek、Yiwen Song、Dirichi Ike-Njoku、Hamid Palangi、Jindong Gu、Shravan Dheep、Karthik Narashimhan、Tamoghna Saha、Joon Baek、Rick Pereira、Cai Xu、Jingjing Zhou、Aparna Joshi、Will Hawkins



