

Last year, we released ShieldGemma, a suite of safety content classifier models built on Gemma 2 and designed to detect harmful content in AI models’ text inputs and outputs. As we debut Gemma 3 today, we’re excited to build on our foundation of responsible AI by announcing ShieldGemma 2.
Link to Youtube Video (visible only when JS is disabled)
ShieldGemma 2, built on Gemma 3, is a 4 billion (4B) parameter model that checks the safety of your synthetic and natural images against key categories to help you build robust datasets and models. With this addition to the Gemma family of models, researchers and developers can now easily minimize the risk of harmful content in their models across key areas of harm:

We recommend using ShieldGemma 2 as an input filter to vision language models, or as an output filter of image generation systems. ShieldGemma can be used on both synthetic and natural images.
Moving beyond text, training and understanding image safety in multimodal models brings new challenges, which is why ShieldGemma 2 is built to respond to a wide range of diverse and nuanced styles of imagery.
To train a robust image safety model, we curated training datasets of natural and synthetic images, and instruction-tuned Gemma 3 to demonstrate strong performance. We compared safety policies to the following benchmarks, and will be releasing a technical report that also incorporates third party benchmarks.
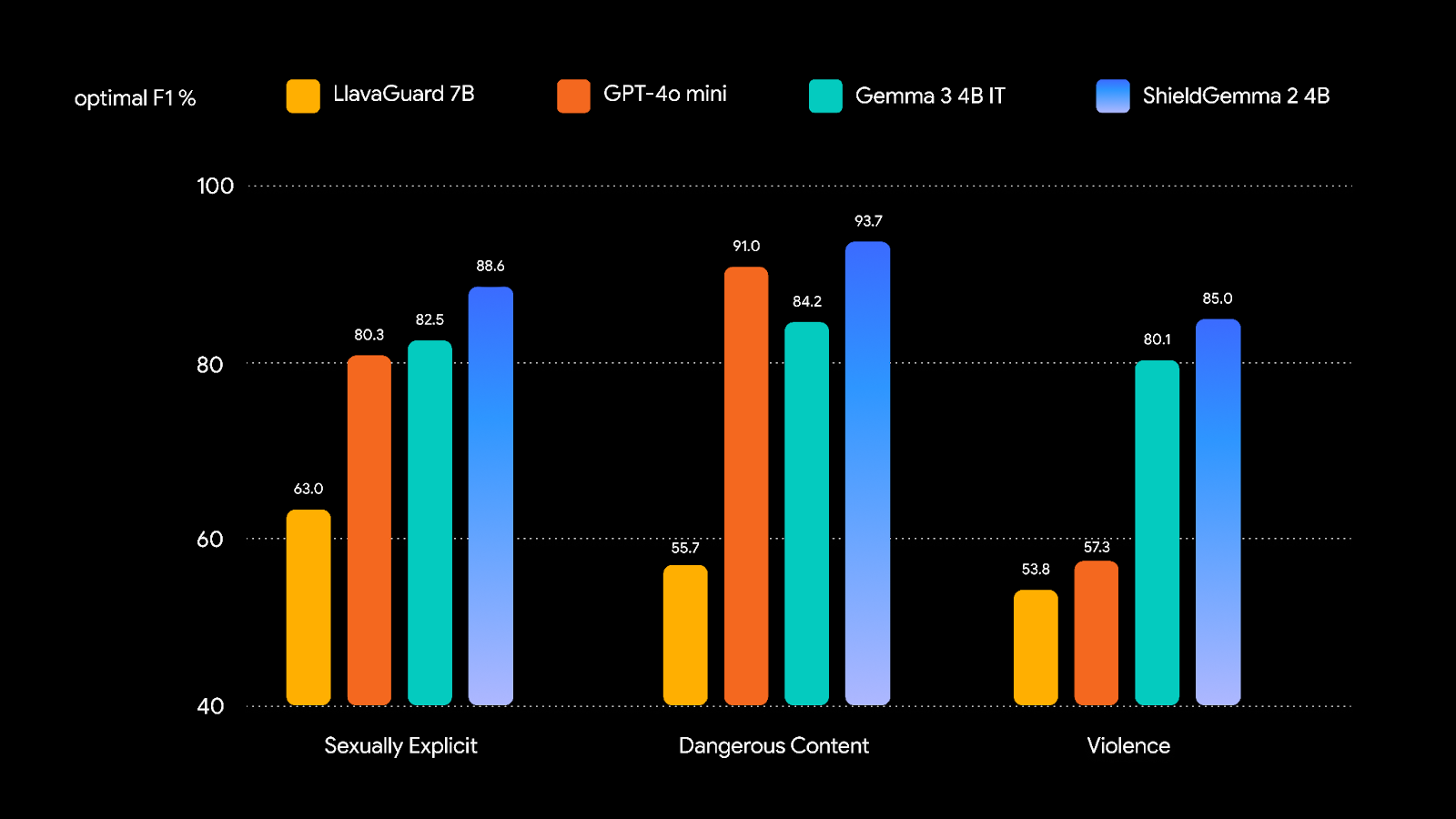
Deploying open models responsibly relies on a whole community effort, and we look forward to exploring how ShieldGemma 2 can be delivered in smaller sizes, across more harm areas, and aligned with multimodal ML Commons taxonomy in the near future.
We’re excited to continue building for safe and responsible multimodal AI!
Wenjun Zeng, Ryan Mullins, Dana Kurniawan, Yuchi Liu, Mani Malek, Yiwen Song, Dirichi Ike-Njoku, Hamid Palangi, Jindong Gu, Shravan Dheep, Karthik Narashimhan, Tamoghna Saha, Joon Baek, Rick Pereira, Cai Xu, Jingjing Zhou, Aparna Joshi, Will Hawkins

Speeding Up AI: Bringing Google Colossus to PyTorch via GCSFS and Rapid Bucket

Build Long-running AI agents that pause, resume, and never lose context with ADK

Introducing EmbeddingGemma: The Best-in-Class Open Model for On-Device Embeddings

Introducing Gemma 3 270M: The compact model for hyper-efficient AI

Supercharging LLM inference on Google TPUs: Achieving 3X speedups with diffusion-style speculative decoding