
ほぼすべての分野の技術進展を支えているのが、データです。データは、深い知見を得るための原材料であり、現在の現実を正確に測定したり、重要な傾向を特定したり、将来の結果を予測したりするために活用されます。
Google の Data Commons の使命は、世界中で公開されている統計データを整理し、誰でも簡単に利用できる便利なものにすることです。Data Commons はオープンソースのナレッジグラフです。多様なソースから集めた膨大な数の公開データが一元化されているので、デベロッパー、研究者、データ アナリストは簡単にデータを利用したり、理解したりできます。Data Commons は、datacommons.org ウェブサイトだけでなく、Google 検索でも利用されています。たとえばサンフランシスコの人口は?と尋ねると、画面上部にグラフが表示されます。
本日は、V2 REST API を利用した Data Commons 用の新しい Python クライアント ライブラリが一般提供版となったことをお知らせします。この新しい Python ライブラリは、データ デベロッパーが Data Commons を活用する方法を劇的に改善します。
このマイルストーンを実現する上で大きな役割を果たしたのが、パートナーの ONE Campaign のビジョンと実質的な貢献でした。ONE Campaign は、アフリカで経済的機会を創出し、健康的な生活を実現するために必要になる投資を促進しているグローバル組織です。私たちは、Data Commons をオープンソース プラットフォームとして開発することで、コミュニティが活発に貢献し、革新的な方法で活用できるようにしました。ONE Campaign との連携は、この目的を見事に体現しています。ONE はクライアント ライブラリの設計を提案して、コーディングを行い、Python の分析ツールやライブラリによる豊かなエコシステムを活用したいと考えているデータ サイエンティストやアナリストが Data Commons の豊富な知見を利用できるようにしました。
Data Commons プラットフォームを活用すれば、国連や ONE などの組織が独自の Data Commons インスタンスをホストすることもできます。こういったカスタム インスタンスを使えば、基本的な Data Commons ナレッジグラフに独自のデータセットをシームレスに組み込むことができます。つまり、Data Commons のデータ フレームワークやツールを活用しながら、データやリソースを完全に制御できます。
V2 ライブラリの特に効果的な追加機能が、カスタム インスタンスの強力なサポートです。この Python ライブラリでは、ローカル、組織内、Google Cloud プラットフォームなど、データがどこにホストされているかに関係なく、あらゆるパブリック インスタンスやプライベート インスタンスでプログラムからクエリできます。
この Python ライブラリを使えば、Data Commons データに対して一般的なクエリを簡単に実行できます。以下に例を示します。
V2 クライアント ライブラリは、V1 ライブラリから多くの点が技術的に改善されています。たとえば以下のような内容です。
variable = "sdg/SI_POV_DAY1"
variable_name = "Proportion of population below international poverty line"
df = client.observations_dataframe(variable_dcids=variable, date="all", parent_entity="Earth", entity_type="Continent")
df = df.pivot(index="date", columns="entity_name", values="value")
ax = df.plot(kind="line")
ax.set_xlabel("Year")
ax.set_ylabel("%")
ax.set_title(variable_name)
ax.legend()
ax.plot()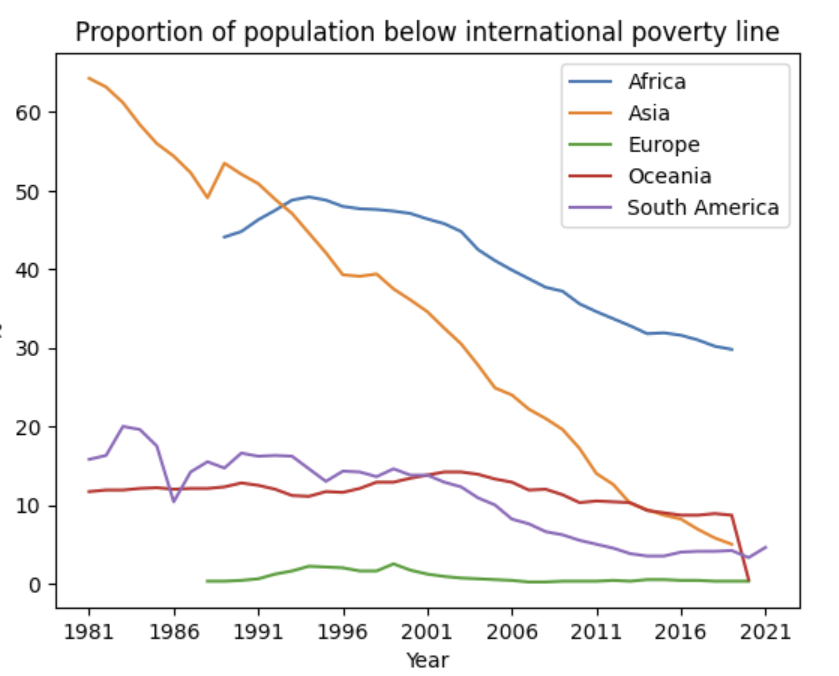
Data Commons Python ライブラリを使ってみたい方は、PyPI から直接パッケージをインストールできます。また、Google Colab ノートブック形式のリファレンス ドキュメントやオンライン チュートリアルなど、さまざまなリソースも準備しています。
現在 V1 Python API を使っている方には、新しい V2 Python ライブラリにアップグレードすることを強くおすすめします。V1 API はサポートが終了する予定です。新しいライブラリを採用することで、最新機能を利用でき、サポートも継続されます。
このライブラリは、オープンソースのコラボレーションによる力を証明するものです。オープンソースのコードは GitHub で公開されています。Google Contributor License Agreement に基づくコミュニティの貢献を歓迎します。



