
Gemma adalah keluarga model terbuka yang dibangun dari riset dan teknologi yang sama dengan yang digunakan untuk membuat model Gemini. Model Gemma mampu melakukan berbagai tugas, termasuk pembuatan teks, pelengkapan dan pembuatan kode, penyesuaian untuk tugas-tugas tertentu, dan berjalan di berbagai perangkat.
Ray adalah framework open source untuk menskalakan aplikasi AI dan Python. Ray menyediakan infrastruktur untuk melakukan komputasi terdistribusi dan pemrosesan paralel untuk alur kerja machine learning (ML) Anda.
Pada akhir tutorial ini, Anda akan memiliki pemahaman yang kuat tentang cara menggunakan Gemma Supervised tuning dengan Ray di Vertex AI untuk melatih dan menyajikan model machine learning secara efisien dan efektif.
Anda bisa menjelajah notebook tutorial "Memulai Gemma dengan Ray di Vertex AI" di GitHub untuk mempelajari lebih lanjut tentang Gemma di Ray. Semua kode di bawah tersedia di notebook ini untuk mempermudah perjalanan Anda.
Langkah-langkah berikut ini diperlukan, apa pun lingkungan Anda.
2. Pastikan penagihan diaktifkan untuk project Anda.
3. Aktifkan API.
Jika Anda menjalankan tutorial ini secara lokal, Anda perlu menginstal Cloud SDK.
Tutorial ini menggunakan komponen yang dapat ditagih dari Google Cloud:
Pelajari tentang penentuan harga, gunakan Kalkulator Harga untuk menghasilkan estimasi biaya berdasarkan proyeksi penggunaan Anda.
Kita akan menggunakan set data Extreme Summarization (XSum), yang merupakan set data tentang sistem peringkasan dokumen tunggal abstraktif.
Anda harus membuat bucket penyimpanan untuk menyimpan artefak perantara, seperti set data.
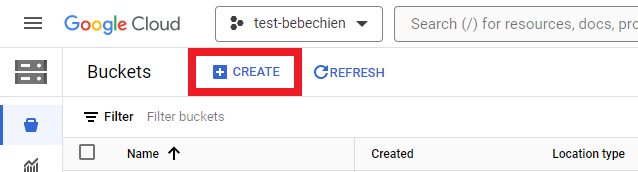
Atau dengan Google Cloud CLI
gsutil mb -l {REGION} -p {PROJECT_ID} {BUCKET_URI}
# for example: gsutil mb -l asia-northeast1 -p test-bebechien gs://test-bebechien-ray-bucketUntuk menyimpan image cluster khusus, buat repositori Docker di Artifact Registry.
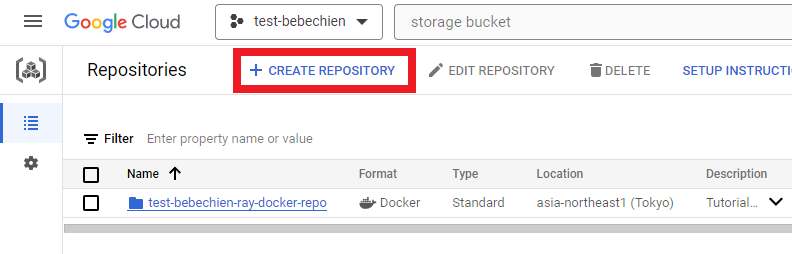
Atau dengan Google Cloud CLI
gcloud artifacts repositories create your-repo --repository-format=docker --location=your-region --description="Tutorial repository"Instance TensorBoard digunakan untuk melacak dan memantau tugas penyetelan Anda. Anda bisa membuatnya dari Eksperimen.
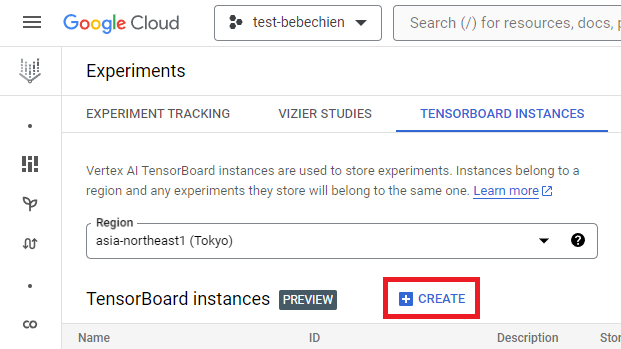
Atau dengan Google Cloud CLI
gcloud ai tensorboards create --display-name your-tensorboard --project your-project --region your-regionUntuk memulai dengan Ray di Vertex AI, Anda bisa memilih membuat Dockerfile untuk image khusus dari awal atau menggunakan salah satu image dasar bawaan Ray. Salah satu image dasar tersebut tersedia di sini.
Pertama, siapkan file persyaratan yang mencakup dependensi untuk menjalankan aplikasi Ray Anda.
Kemudian, buat Dockerfile untuk image khusus dengan memanfaatkan salah satu image dasar bawaan Ray di Vertex AI.
Terakhir, buat image khusus cluster Ray menggunakan Cloud Build.
gcloud builds submit --region=your-region
--tag=your-region-docker.pkg.dev/your-project/your-repo/train --machine-type=E2_HIGHCPU_32 ./dockerfile-pathJika semuanya berjalan dengan baik, Anda akan melihat image khusus berhasil dikirim ke repositori image docker Anda.
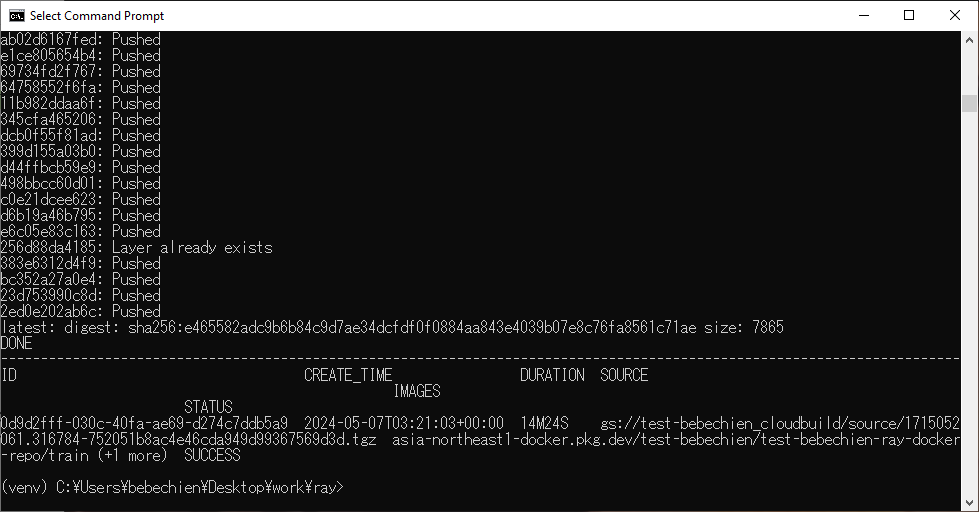
Juga di Artifact Registry
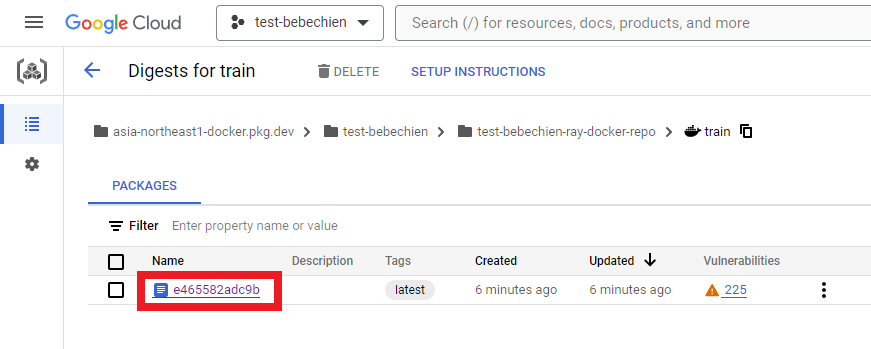
Anda bisa membuat cluster ray dari Ray di Vertex AI.
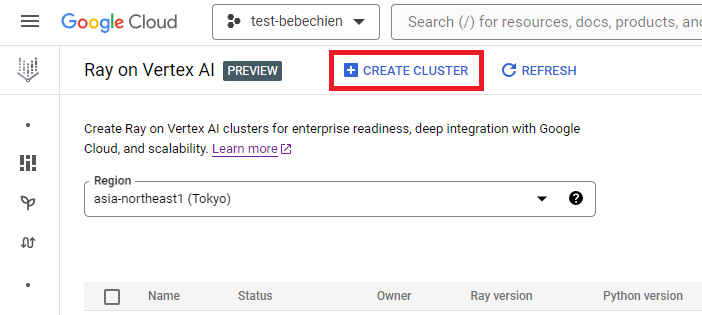
Atau gunakan Vertex AI Python SDK untuk membuat cluster Ray dengan image khusus dan menyesuaikan konfigurasi cluster. Untuk mempelajari lebih lanjut tentang konfigurasi cluster, lihat dokumentasi.
Di bawah ini adalah contoh kode Python untuk membuat cluster Ray dengan konfigurasi khusus yang telah ditentukan sebelumnya.
CATATAN: Membuat cluster bisa memakan waktu beberapa menit, tergantung konfigurasinya.
# Set up Ray on Vertex AI
import vertex_ray
from google.cloud import aiplatform as vertex_ai
from vertex_ray import NodeImages, Resources
# Retrieves an existing managed tensorboard given a tensorboard ID
tensorboard = vertex_ai.Tensorboard(your-tensorboard-id, project=your-project, location=your-region)
# Initialize the Vertex AI SDK for Python for your project
vertex_ai.init(project=your-project, location=your-region, staging_bucket=your-bucket-uri, experiment_tensorboard=tensorboard)
HEAD_NODE_TYPE = Resources(
machine_type= "n1-standard-16",
node_count=1,
)
WORKER_NODE_TYPES = [
Resources(
machine_type="n1-standard-16",
node_count=1,
accelerator_type="NVIDIA_TESLA_T4",
accelerator_count=2,
)
]
CUSTOM_IMAGES = NodeImages(
head="your-region-docker.pkg.dev/your-project/your-repo/train",
worker="your-region-docker.pkg.dev/your-project/your-repo/train",
)
ray_cluster_name = vertex_ray.create_ray_cluster(
head_node_type=HEAD_NODE_TYPE,
worker_node_types=WORKER_NODE_TYPES,
custom_images=CUSTOM_IMAGES,
cluster_name=”your-cluster-name”,
)Sekarang Anda bisa mendapatkan cluster Ray dengan get_ray_cluster(). Gunakan list_ray_clusters() jika Anda ingin melihat semua cluster yang terkait dengan project Anda.
ray_clusters = vertex_ray.list_ray_clusters()
ray_cluster_resource_name = ray_clusters[-1].cluster_resource_name
ray_cluster = vertex_ray.get_ray_cluster(ray_cluster_resource_name)
print("Ray cluster on Vertex AI:", ray_cluster_resource_name)Untuk menyesuaikan Gemma dengan Ray di Vertex AI, Anda bisa menggunakan Ray Train untuk mendistribusikan HuggingFace Transformers dengan pelatihan PyTorch, seperti yang terlihat di bawah ini.
Dengan Ray Train, Anda menentukan fungsi pelatihan yang berisi kode HuggingFace Transformers untuk menyesuaikan Gemma yang ingin didistribusikan. Berikutnya, Anda menentukan konfigurasi penskalaan untuk menetapkan jumlah worker yang diinginkan dan menunjukkan jika proses pelatihan terdistribusi memerlukan GPU. Selain itu, Anda bisa menentukan konfigurasi runtime untuk mengatur perilaku titik pemeriksaan dan sinkronisasi. Terakhir, Anda mengirimkan penyesuaian dengan menginisiasi TorchTrainer dan menjalankannya menggunakan metode penyesuaian.
Dalam tutorial ini, kita akan menyesuaikan Gemma 2B (gemma-2b-it) untuk meringkas artikel surat kabar menggunakan HuggingFace Transformer dengan Ray di Vertex AI. Kami menulis skrip trainer.py Python sederhana dan akan mengirimkannya ke cluster Ray.
Mari siapkan skrip pelatihan, di bawah ini adalah contoh skrip Python untuk menginisialisasi penyesuaian Gemma menggunakan library HuggingFace TRL.
Berikutnya, siapkan skrip pelatihan terdistribusi. Di bawah ini adalah contoh skrip Python untuk mengeksekusi tugas pelatihan terdistribusi Ray.
Sekarang kita kirimkan skrip tersebut ke cluster Ray menggunakan Ray Jobs API melalui alamat dasbor Ray. Anda juga bisa menemukan alamat dasbor pada halaman detail Cluster seperti di bawah ini.
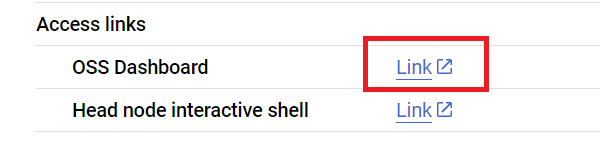
Pertama, inisiasi klien untuk mengirimkan tugas.
import ray
from ray.job_submission import JobSubmissionClient
client = JobSubmissionClient(
address="vertex_ray://{}".format(ray_cluster.dashboard_address)
)Mari kita atur beberapa konfigurasi tugas termasuk jalur model, id tugas, titik masuk prediksi, dan lainnya.
import random, string, datasets, transformers
from etils import epath
from huggingface_hub import login
# Initialize some libraries settings
login(token=”your-hf-token”)
datasets.disable_progress_bar()
transformers.set_seed(8)
train_experiment_name = “your-experiment-name”
train_submission_id = “your-submission-id”
train_entrypoint = f"python3 trainer.py --experiment-name={train_experiment_name} --logging-dir=”your-bucket-uri/logs” --num-workers=2 --use-gpu"
train_runtime_env = {
"working_dir": "your-working-dir",
"env_vars": {"HF_TOKEN": ”your-hf-token”, "TORCH_NCCL_ASYNC_ERROR_HANDLING": "3"},
}Mengirim tugas
train_job_id = client.submit_job(
submission_id=train_submission_id,
entrypoint=train_entrypoint,
runtime_env=train_runtime_env,
)Periksa status tugas dari dasbor OSS.
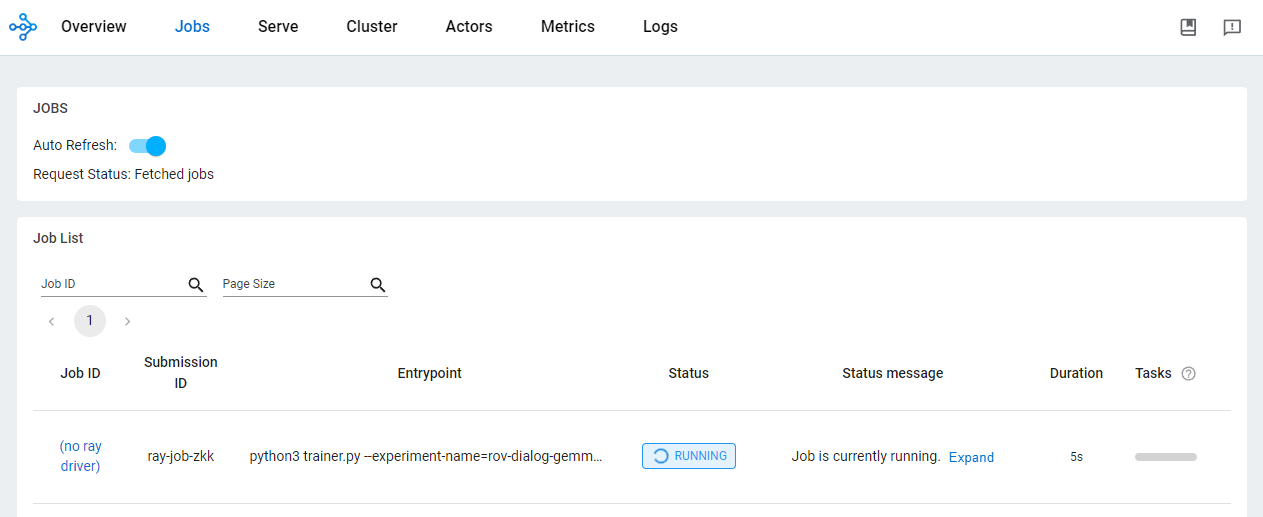
Menggunakan Ray di Vertex AI untuk mengembangkan aplikasi AI/ML memberikan berbagai manfaat. Dalam skenario ini, Anda bisa menggunakan penyimpanan Cloud untuk menyimpan titik pemeriksaan model, metrik, dan lainnya dengan mudah. Hal ini memungkinkan Anda memakai model secara cepat untuk tugas-tugas downstreaming AI/ML, termasuk memantau proses pelatihan menggunakan Vertex AI TensorBoard atau menghasilkan prediksi batch menggunakan Ray Data.
Saat tugas pelatihan Ray berjalan dan setelah tugas itu selesai, Anda bisa melihat artefak model di lokasi Cloud Storage dengan Google Cloud CLI.
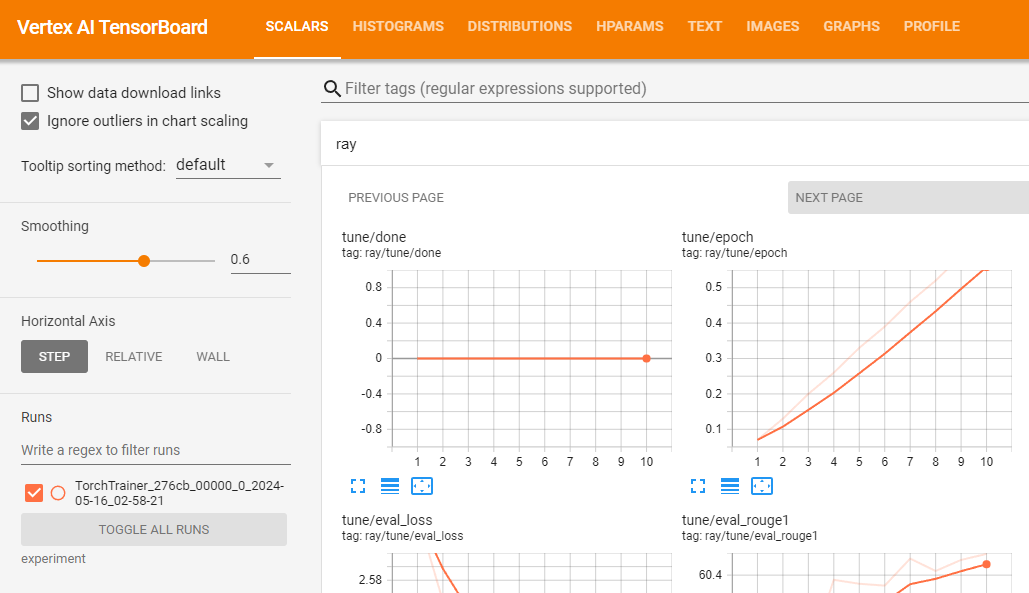
gsutil ls -l your-bucket-uri/your-experiments/your-experiment-nameAnda bisa menggunakan Vertex AI TensorBoard untuk memvalidasi tugas pelatihan Anda dengan mencatat metrik yang dihasilkan.
vertex_ai.upload_tb_log(
tensorboard_id=tensorboard.name,
tensorboard_experiment_name=train_experiment_name,
logdir=./experiments,
)
Dengan asumsi bahwa pelatihan Anda berjalan sukses, Anda bisa menghasilkan prediksi secara lokal untuk memvalidasi model yang telah disesuaikan.
Pertama, download semua hasil titik pemeriksaan dari tugas Ray dengan Google Cloud CLI.
# copy all artifacts
gsutil ls -l your-bucket-uri/your-experiments/your-experiment-name ./your-experiment-pathGunakan metode ExperimentAnalysis untuk mendapatkan titik pemeriksaan terbaik menurut metrik dan mode yang relevan.
import ray
from ray.tune import ExperimentAnalysis
experiment_analysis = ExperimentAnalysis(“./your-experiment-path”)
log_path = experiment_analysis.get_best_trial(metric="eval_rougeLsum", mode="max")
best_checkpoint = experiment_analysis.get_best_checkpoint(
log_path, metric="eval_rougeLsum", mode="max"
)Sekarang Anda tahu mana yang merupakan titik pemeriksaan terbaik. Di bawah ini adalah contoh output.

Dan muat model yang sudah disesuaikan seperti yang dijelaskan dalam dokumentasi Hugging Face.
Di bawah ini adalah contoh kode Python untuk memuat model dasar dan menggabungkan adaptor ke dalam model dasar sehingga Anda bisa menggunakan model tersebut seperti model transformer biasa. Anda dapat menemukan model yang telah disesuaikan yang tersimpan di tuned_model_path. Sebagai contoh, “tutorial/models/xsum-tuned-gemma-it”
import torch
from etils import epath
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import PeftModel
base_model_path = "google/gemma-2b-it"
peft_model_path = epath.Path(best_checkpoint.path) / "checkpoint"
tuned_model_path = models_path / "xsum-tuned-gemma-it"
tokenizer = AutoTokenizer.from_pretrained(base_model_path)
tokenizer.padding_side = "right"
base_model = AutoModelForCausalLM.from_pretrained(
base_model_path, device_map="auto", torch_dtype=torch.float16
)
peft_model = PeftModel.from_pretrained(
base_model,
peft_model_path,
device_map="auto",
torch_dtype=torch.bfloat16,
is_trainable=False,
)
tuned_model = peft_model.merge_and_unload()
tuned_model.save_pretrained(tuned_model_path)Informasi tambahan: Setelah menyesuaikan model, Anda juga bisa memublikasikannya ke Hugging Face Hub dengan menggunakan satu baris kode ini.
tuned_model.push_to_hub("my-awesome-model")Untuk membuat ringkasan dengan model yang telah disesuaikan, mari kita gunakan set validasi dari set data tutorial.
Contoh kode Python berikut menunjukkan cara mengambil satu contoh artikel dari set data untuk diringkas. Kode ini kemudian membuat ringkasan yang sesuai dan mencetak ringkasan referensi dari set data dan ringkasan yang dihasilkan secara berdampingan.
import random, datasets
from transformers import pipeline
dataset = datasets.load_dataset(
"xsum", split="validation", cache_dir=”./data”, trust_remote_code=True
)
sample = dataset.select([random.randint(0, len(dataset) - 1)])
document = sample["document"][0]
reference_summary = sample["summary"][0]
messages = [
{
"role": "user",
"content": f"Summarize the following ARTICLE in one sentence.\n###ARTICLE: {document}",
},
]
prompt = tokenizer.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
tuned_gemma_pipeline = pipeline(
"text-generation", model=tuned_model, tokenizer=tokenizer, max_new_tokens=50
)
generated_tuned_gemma_summary = tuned_gemma_pipeline(
prompt, do_sample=True, temperature=0.1, add_special_tokens=True
)[0]["generated_text"][len(prompt) :]
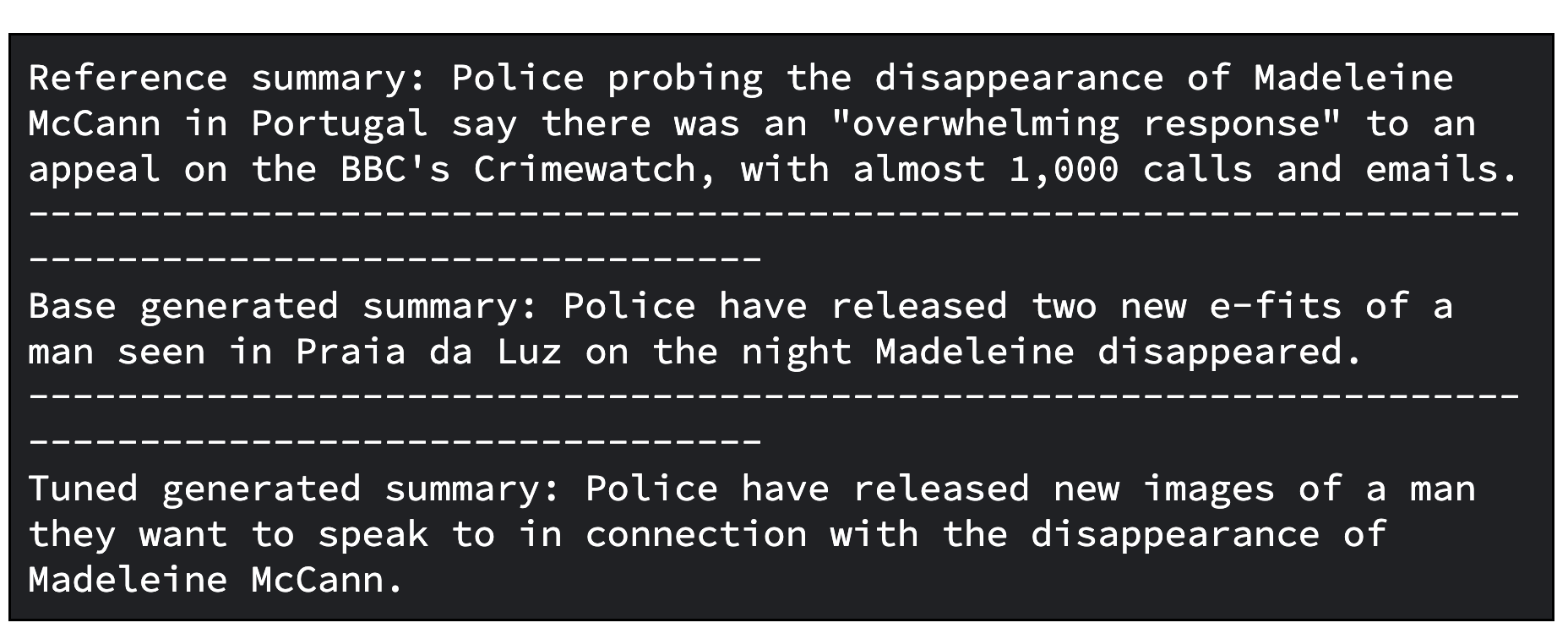
print(f"Reference summary: {reference_summary}")
print("-" * 100)
print(f"Tuned generated summary: {generated_tuned_gemma_summary}")Di bawah ini adalah contoh output dari model yang disesuaikan. Perhatikan bahwa hasil yang sudah disesuaikan mungkin memerlukan penyesuaian lanjutan. Untuk mencapai kualitas yang optimal, sebaiknya melakukan iterasi proses ini beberapa kali, dengan menyesuaikan faktor-faktor, seperti kecepatan pembelajaran dan jumlah langkah pelatihan.

Sebagai langkah tambahan, Anda bisa mengevaluasi model yang sudah disesuaikan. Untuk mengevaluasi model, Anda membandingkan model secara kualitatif dan kuantitatif.
Dalam satu kasus, Anda membandingkan respons yang dihasilkan oleh model Gemma dasar dengan respons yang dihasilkan oleh model Gemma yang disesuaikan. Pada kasus lainnya, Anda mengalkulasi metrik ROUGE dan peningkatannya yang memberikan gambaran mengenai seberapa baik model yang disesuaikan dapat mereproduksi ringkasan referensi dengan benar dibandingkan dengan model dasar.
Di bawah ini adalah kode Python untuk mengevaluasi model dengan membandingkan ringkasan yang dihasilkan.
gemma_pipeline = pipeline(
"text-generation", model=base_model, tokenizer=tokenizer, max_new_tokens=50
)
generated_gemma_summary = gemma_pipeline(
prompt, do_sample=True, temperature=0.1, add_special_tokens=True
)[0]["generated_text"][len(prompt) :]
print(f"Reference summary: {reference_summary}")
print("-" * 100)
print(f"Base generated summary: {generated_gemma_summary}")
print("-" * 100)
print(f"Tuned generated summary: {generated_tuned_gemma_summary}")Di bawah ini adalah output contoh dari model dasar dan model yang disesuaikan.
Dan di bawah ini adalah kode untuk mengevaluasi model dengan mengomputasi metrik ROUGE dan peningkatannya.
import evaluate
rouge = evaluate.load("rouge")
gemma_results = rouge.compute(
predictions=[generated_gemma_summary],
references=[reference_summary],
rouge_types=["rouge1", "rouge2", "rougeL", "rougeLsum"],
use_aggregator=True,
use_stemmer=True,
)
tuned_gemma_results = rouge.compute(
predictions=[generated_tuned_gemma_summary],
references=[reference_summary],
rouge_types=["rouge1", "rouge2", "rougeL", "rougeLsum"],
use_aggregator=True,
use_stemmer=True,
)
improvements = {}
for rouge_metric, gemma_rouge in gemma_results.items():
tuned_gemma_rouge = tuned_gemma_results[rouge_metric]
if gemma_rouge != 0:
improvement = ((tuned_gemma_rouge - gemma_rouge) / gemma_rouge) * 100
else:
improvement = None
improvements[rouge_metric] = improvement
print("Base Gemma vs Tuned Gemma - ROUGE improvements")
for rouge_metric, improvement in improvements.items():
print(f"{rouge_metric}: {improvement:.3f}%")Dan output contoh untuk evaluasi.

Untuk membuat prediksi offline dalam skala besar dengan Gemma yang disesuaikan menggunakan Ray di Vertex AI, Anda bisa menggunakan Ray Data, library pemrosesan data skalabel untuk beban kerja ML.
Saat menggunakan Ray Data untuk menghasilkan prediksi offline dengan Gemma, Anda perlu menetapkan class Python untuk memuat model yang disesuaikan di Hugging Face Pipeline. Kemudian, tergantung pada sumber data dan formatnya, Anda menggunakan Ray Data untuk melakukan pembacaan data terdistribusi dan menggunakan metode set data Ray untuk menerapkan class Python untuk melakukan prediksi secara paralel ke beberapa batch data.
Untuk membuat prediksi batch dengan model yang disesuaikan menggunakan Ray Data di Vertex AI, Anda memerlukan set data untuk membuat prediksi dan model yang disesuaikan disimpan di bucket Cloud.
Kemudian, Anda bisa memanfaatkan Ray Data yang menyediakan API yang mudah digunakan untuk inferensi batch offline.
Pertama, upload model yang disesuaikan di Cloud storage dengan Google Cloud CLI
gsutil -q cp -r “./models” “your-bucket-uri/models”Siapkan file skrip pelatihan prediksi batch untuk menjalankan tugas prediksi batch Ray.
Sekali lagi, Anda bisa menginisiasi klien untuk mengirimkan tugas seperti di bawah ini dengan Ray Jobs API melalui alamat dasbor Ray.
import ray
from ray.job_submission import JobSubmissionClient
client = JobSubmissionClient(
address="vertex_ray://{}".format(ray_cluster.dashboard_address)
)Mari kita atur beberapa konfigurasi tugas termasuk jalur model, id tugas, titik masuk prediksi, dan lainnya.
import random, string
batch_predict_submission_id = "your-batch-prediction-job"
tuned_model_uri_path = "/gcs/your-bucket-uri/models"
batch_predict_entrypoint = f"python3 batch_predictor.py --tuned_model_path={tuned_model_uri_path} --num_gpus=1 --output_dir=”your-bucket-uri/predictions”"
batch_predict_runtime_env = {
"working_dir": "tutorial/src",
"env_vars": {"HF_TOKEN": “your-hf-token”},
}Anda bisa menentukan jumlah GPU yang digunakan dengan argumen "--num_gpus". Ini harus bernilai sama atau lebih kecil dari jumlah GPU yang tersedia di cluster Ray Anda.
Lalu kirim tugas tersebut.
batch_predict_job_id = client.submit_job(
submission_id=batch_predict_submission_id,
entrypoint=batch_predict_entrypoint,
runtime_env=batch_predict_runtime_env,
)Mari lihat sekilas ringkasan yang dihasilkan menggunakan Pandas DataFrame.
import io
import pandas as pd
from google.cloud import storage
def read_json_files(bucket_name, prefix=None):
"""Reads JSON files from a cloud storage bucket and returns a Pandas DataFrame"""
# Set up storage client
storage_client = storage.Client()
bucket = storage_client.bucket(bucket_name)
blobs = bucket.list_blobs(prefix=prefix)
dfs = []
for blob in blobs:
if blob.name.endswith(".json"):
file_bytes = blob.download_as_bytes()
file_string = file_bytes.decode("utf-8")
with io.StringIO(file_string) as json_file:
df = pd.read_json(json_file, lines=True)
dfs.append(df)
return pd.concat(dfs, ignore_index=True)
predictions_df = read_json_files(prefix="predictions/", bucket_name=”your-bucket-uri”)
predictions_df = predictions_df[
["id", "document", "prompt", "summary", "generated_summary"]
]
predictions_df.head()Dan di bawah ini adalah output contohnya. Jumlah default artikel yang akan diringkas adalah 20. Anda bisa menentukan jumlahnya dengan argumen “--sample_size”.

Sekarang Anda telah mempelajari banyak hal termasuk:
Kami berharap tutorial ini dapat mencerahkan dan memberi Anda insight yang berharga.
Pertimbangkan untuk bergabung dengan server Discord Komunitas Developer Google. Komunitas ini menawarkan kesempatan untuk membagikan project Anda, terhubung dengan developer lain, dan terlibat dalam diskusi kolaboratif.
Dan jangan lupa untuk membersihkan semua sumber daya Google Cloud yang digunakan dalam project ini. Anda cukup menghapus project Google Cloud yang digunakan untuk tutorial ini. Jika tidak, Anda bisa menghapus sumber daya individual yang Anda buat.
# Delete tensorboard
tensorboard_list = vertex_ai.Tensorboard.list()
for tensorboard in tensorboard_list:
tensorboard.delete()
# Delete experiments
experiment_list = vertex_ai.Experiment.list()
for experiment in experiment_list:
experiment.delete()
# Delete ray on vertex cluster
ray_cluster_list = vertex_ray.list_ray_clusters()
for ray_cluster in ray_cluster_list:
vertex_ray.delete_ray_cluster(ray_cluster.cluster_resource_name)# Delete artifacts repo
gcloud artifacts repositories delete “your-repo” -q
# Delete Cloud Storage objects that were created
gsutil -q -m rm -r “your-bucker-uri”Terima kasih sudah membaca!

Vertex AI RAG Engine: Alat developer
Inovasi multibahasa dalam LLM: Bagaimana model terbuka membantu membuka komunikasi global

Introducing Gemma 3n: The developer guide
Using KerasHub for easy end-to-end machine learning workflows with Hugging Face

Membuka insight yang lebih mendalam dengan library klien Python terbaru untuk Data Commons