

Mengikuti jejak Gemma 1. 1 (Kaggle, Hugging Face), CodeGemma (Kaggle, Hugging Face), dan model multimodal PaliGemma (Kaggle, Hugging Face), dengan bangga kami umumkan dirilisnya model Gemma 2 di Keras.
Gemma 2 tersedia dalam dua ukuran - parameter 9B dan 27B - dengan varian standar dan varian yang disesuaikan dengan instruksi. Anda bisa menemukannya di sini:
Hasil terbaik Gemma 2 pada tolok ukur LLM telah dibahas di artikel lain (lihat goo.gle/gemma2report). Dalam postingan ini kami ingin menunjukkan bagaimana kombinasi Keras dan JAX bisa membantu Anda bekerja dengan model besar ini.
JAX adalah framework numerik yang dibangun untuk skala besar. Framework ini memanfaatkan compiler machine learning XLA dan melatih model terbesar di Google.
Keras adalah framework pemodelan untuk engineer ML, kini berjalan di JAX, TensorFlow atau PyTorch. Keras sekarang menghadirkan penskalaan paralel model kuat melalui Keras API yang sangat menarik. Anda bisa mencoba model Gemma 2 yang baru dalam Keras di sini:
Karena ukurannya, model ini hanya bisa dimuat dan disesuaikan hingga presisi maksimal dengan membagi bobotnya ke beberapa akselerator. JAX dan XLA memiliki dukungan ekstensif untuk partisi bobot (paralelisme model SPMD) dan Keras menambahkan API keras.distribution.ModelParallel untuk membantu Anda menentukan sharding lapisan per lapisan secara sederhana:
# List accelerators
devices = keras.distribution.list_devices()
# Arrange accelerators in a logical grid with named axes
device_mesh = keras.distribution.DeviceMesh((2, 8), ["batch", "model"], devices)
# Tell XLA how to partition weights (defaults for Gemma)
layout_map = gemma2_lm.backbone.get_layout_map()
# Define a ModelParallel distribution
model_parallel = keras.distribution.ModelParallel(device_mesh, layout_map, batch_dim_name="batch")
# Set is as the default and load the model
keras.distribution.set_distribution(model_parallel)
gemma2_lm = keras_nlp.models.GemmaCausalLM.from_preset(...)Fungsi gemma2_lm.backbone.get_layout_map()adalah pembantu yang menampilkan konfigurasi sharding lapisan per lapisan untuk semua bobot model. Ia mengikuti rekomendasi makalah Gemma (goo.gle/gemma2report). Berikut adalah cuplikannya:
layout_map = keras.distribution.LayoutMap(device_mesh)
layout_map["token_embedding/embeddings"] = ("model", "data")
layout_map["decoder_block.*attention.*(query|key|value).kernel"] =
("model", "data", None)
layout_map["decoder_block.*attention_output.kernel"] = ("model", None, "data")
...Ringkasnya, untuk setiap lapisan, konfigurasi ini menentukan sumbu atau aksis yang akan membagi setiap blok bobot, dan akselerator yang akan digunakan untuk menempatkan potongan tersebut. Ini akan lebih mudah dipahami dengan gambar. Mari kita ambil contoh bobot "kueri" dalam arsitektur perhatian Transformer, yang berbentuk (nb heads, embed size, head dim):
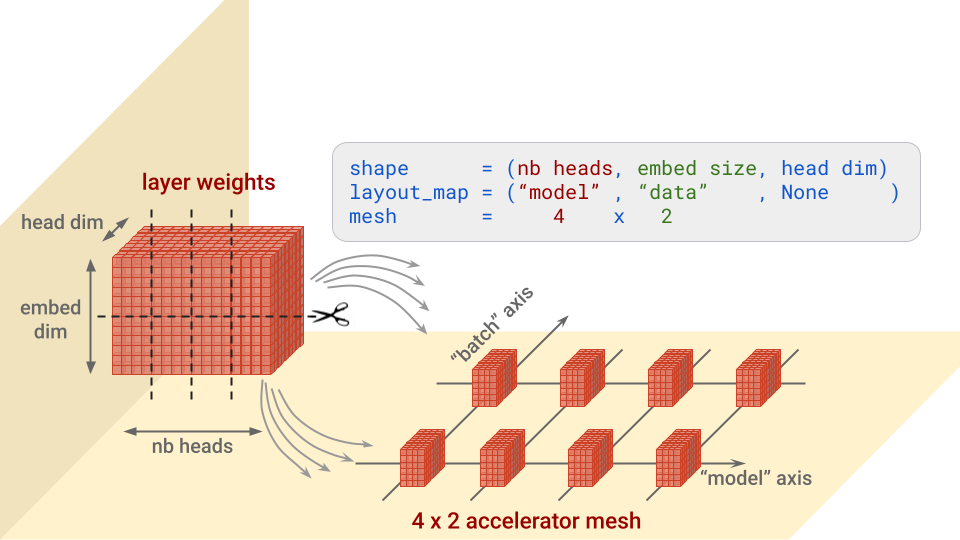
Catatan: dimensi mesh yang tidak terbagi akan menerima salinan. Kasus ini akan terjadi, misalnya, jika peta tata letak di atas adalah (“model”, None, None).
Perhatikan juga parameter batch_dim_name="batch" di ModelParallel. Jika sumbu "batch" memiliki beberapa baris akselerator di dalamnya, seperti kasus di sini, paralelisme data juga akan digunakan. Setiap baris akselerator akan memuat dan melatih hanya sebagian dari setiap batch data, dan kemudian baris tersebut akan menggabungkan gradiennya.
Setelah model dimuat, berikut adalah dua cuplikan kode praktis untuk menampilkan sharding bobot yang benar-benar diterapkan:
for variable in gemma2_lm.backbone.get_layer('decoder_block_1').weights:
print(f'{variable.path:<58} {str(variable.shape):<16} \
{str(variable.value.sharding.spec)}')
#... set an optimizer through gemma2_lm.compile() and then:
gemma2_lm.optimizer.build(gemma2_lm.trainable_variables)
for variable in gemma2_lm.optimizer.variables:
print(f'{variable.path:<73} {str(variable.shape):<16} \
{str(variable.value.sharding.spec)}')Dan jika kita perhatikan output (di bawah), kita akan melihat sesuatu yang penting: ekspresi reguler pada spesifikasi tata letak tidak hanya cocok dengan bobot lapisan, tetapi juga variabel momentum dan velositas yang sesuai di optimizer dan memecahnya dengan tepat. Ini adalah poin penting yang harus diperiksa ketika mempartisi model.
# for layers:
# weight name . . . . . . . . . . shape . . . . . . layout spec
decoder_block_1/attention/query/kernel (16, 3072, 256)
PartitionSpec('model', None, None)
decoder_block_1/ffw_gating/kernel (3072, 24576)
PartitionSpec(None, 'model')
...
# for optimizer vars:
# var name . . . . . . . . . . . .shape . . . . . . layout spec
adamw/decoder_block_1_attention_query_kernel_momentum
(16, 3072, 256) PartitionSpec('model', None, None)
adamw/decoder_block_1_attention_query_kernel_velocity
(16, 3072, 256) PartitionSpec('model', None, None)
...LoRA adalah teknik yang membekukan bobot model dan menggantinya dengan adaptor berperingkat rendah, atau kecil.
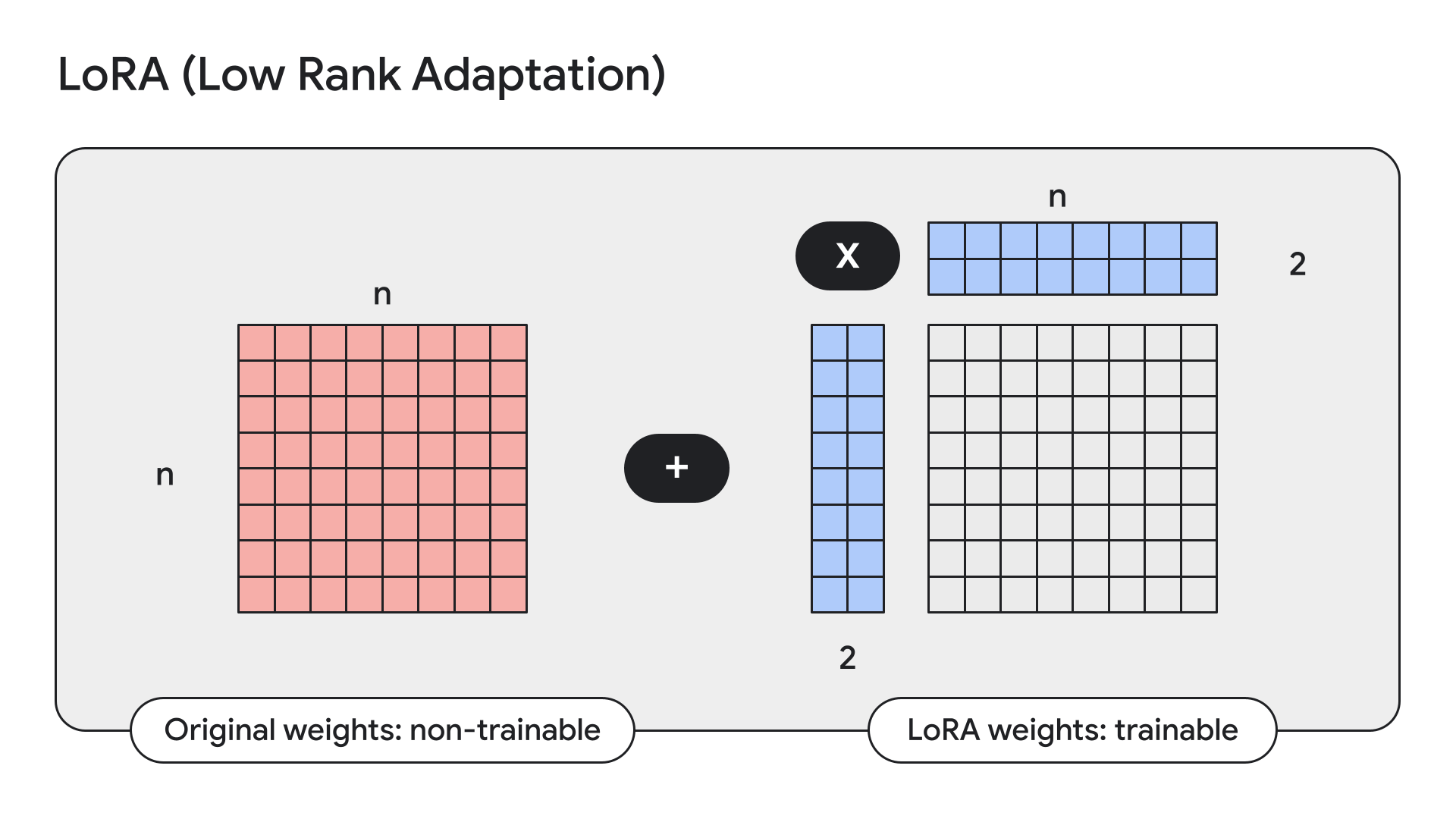
Keras juga memiliki API praktis untuk hal ini:
gemma2_lm.backbone.enable_lora(rank=4) # Rank picked from empirical testingMenampilkan detail model dengan model.summary() setelah mengaktifkan LoRA, kita bisa melihat bahwa LoRA mengurangi jumlah parameter yang dapat dilatih di Gemma 9B dari 9 miliar menjadi 14,5 juta.
Bulan lalu, kami mengumumkan bahwa model Keras akan tersedia, untuk download dan upload pengguna, di Kaggle dan Hugging Face. Hari ini, kami mendorong integrasi Hugging Face lebih jauh lagi: Anda sekarang bisa memuat bobot yang sudah disesuaikan untuk model yang didukung, baik yang sudah dilatih menggunakan model versi Keras atau belum. Bobot akan dikonversi dengan cepat untuk membuatnya bekerja. Ini berarti Anda sekarang memiliki akses ke banyak penyesuaian Gemma yang telah diupload oleh pengguna Hugging Face, langsung dari KerasNLP. Dan bukan hanya Gemma. Nantinya, ini akan berfungsi untuk semua model Hugging Face Transformers yang memiliki implementasi KerasNLP yang sesuai. Untuk saat ini, Gemma dan Llama3 sudah bisa digunakan. Anda dapat mencobanya pada penyesuaian Hermes-2-Pro-Llama-3-8B sebagai contohnya menggunakan Colab ini:
causal_lm = keras_nlp.models.Llama3CausalLM.from_preset(
"hf://NousResearch/Hermes-2-Pro-Llama-3-8B"
)PaliGemma adalah VLM terbuka yang tangguh, terinspirasi oleh PaLI-3. Dibangun di atas komponen terbuka termasuk model visi SigLIP dan model bahasa Gemma, PaliGemma dirancang untuk performa terbaik di kelasnya dalam berbagai tugas visi-bahasa. Ini termasuk pemberian teks gambar, menjawab pertanyaan visual, memahami teks pada gambar, deteksi objek, dan segmentasi objek.
Anda bisa menemukan implementasi Keras PaliGemma di GitHub, model Hugging Face, dan Kaggle.
Kami harap Anda senang bereksperimen atau membangun dengan model Gemma 2 baru di Keras!

Announcing GenAI Processors: Build powerful and flexible Gemini applications

Memperkenalkan Gemma 3n: Panduan developer

Advancing agentic AI development with Firebase Studio

Gemini Embedding now generally available in the Gemini API

T5Gemma: Koleksi model Gemma baru berbasis encoder-decoder