
85 results
APRIL 16, 2026 / AI
MaxText has introduced new support for Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) on single-host TPU configurations, leveraging JAX and the Tunix library for high-performance model refinement. These features enable developers to easily adapt pre-trained models for specialized tasks and complex reasoning using efficient algorithms like GRPO and GSPO. This update streamlines the post-training workflow, offering a scalable path from single-host setups to larger multi-host configurations.

APRIL 2, 2026 / Mobile
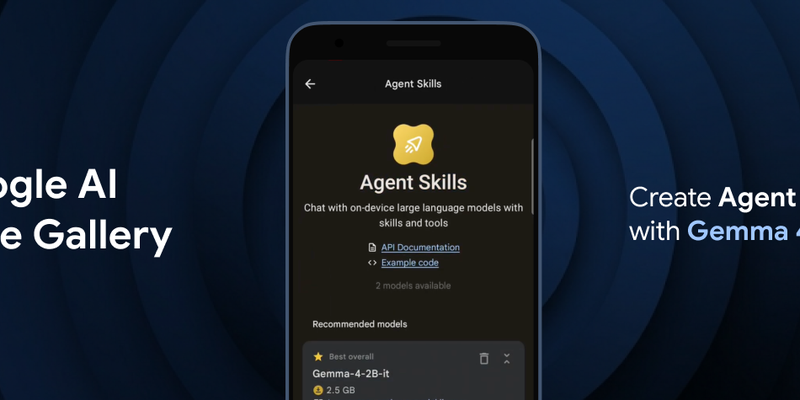
Google DeepMind has launched Gemma 4, a family of state-of-the-art open models designed to enable multi-step planning and autonomous agentic workflows directly on-device. The release includes the Google AI Edge Gallery for experimenting with "Agent Skills" and the LiteRT-LM library, which offers a significant speed boost and structured output for developers. Available under an Apache 2.0 license, Gemma 4 supports over 140 languages and is compatible with a wide range of hardware, including mobile devices, desktops, and IoT platforms like Raspberry Pi.
MARCH 9, 2026 / Cloud
Wednesday Build Hour is a weekly, interactive "technical gym session" led by Google Cloud experts to help developers and architects sharpen their cloud skills. Moving beyond passive slide decks, the program focuses on hands-on building, covering advanced topics like AI agents, Vertex AI, and developer productivity tools. Each hour-long session is designed to provide tangible results that participants can immediately deploy into their own workflows. It serves as a consistent, dedicated space for builders to stay ahead of the curve and connect with a community of cloud engineers.

MARCH 6, 2026 / Cloud
Google has officially launched LiteRT, the successor to TFLite, which offers significantly faster GPU and NPU acceleration alongside seamless support for PyTorch and JAX. The update also introduces lower-precision data type support for increased efficiency and a commitment to more frequent security and dependency updates across the TensorFlow ecosystem. This transition solidifies LiteRT as Google's primary high-performance framework for deploying GenAI and advanced on-device inference.

FEB. 26, 2026 / Mobile
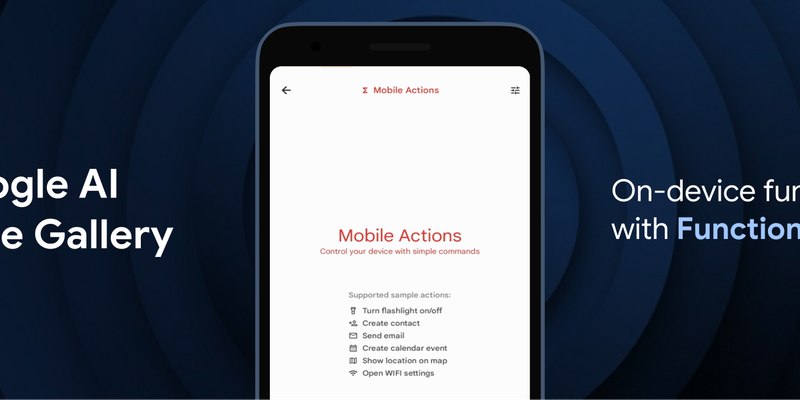
Google has introduced FunctionGemma, a specialized 270M parameter model designed to bring efficient, action-oriented AI experiences directly to mobile devices through on-device function calling. By leveraging Google AI Edge and LiteRT-LM, the model enables complex tasks—such as managing calendars, controlling device hardware, or executing specific game logic in the "Tiny Garden" demo—to be performed entirely offline with high speed and low latency. Available for testing in the Google AI Edge Gallery app on both Android and iOS, FunctionGemma allows developers to move beyond simple text generation toward building responsive, "agentic" applications that interact seamlessly with the physical and digital world without relying on cloud processing.
FEB. 3, 2026 / AI
Finetuning the FunctionGemma model is made fast and easy using the lightweight JAX-based Tunix library on Google TPUs, a process demonstrated here using LoRA for supervised finetuning. This approach delivers significant accuracy improvements with high TPU efficiency, culminating in a model ready for deployment.
JAN. 28, 2026 / Mobile
LiteRT, the evolution of TFLite, is now the universal framework for on-device AI. It delivers up to 1.4x faster GPU, new NPU support, and streamlined GenAI deployment for models like Gemma.

JAN. 16, 2026 / AI
FunctionGemma is a specialized AI model for function calling. This post explains why fine-tuning is key to resolving tool selection ambiguity (e.g., internal vs. Google search) and achieving ultra-specialization, transforming it into a strict, enterprise-compliant agent. A case study demonstrates the improved logic. It also introduces the "FunctionGemma Tuning Lab," a no-code demo on Hugging Face Spaces, which streamlines the entire fine-tuning process for developers.
DEC. 9, 2025 / AI
Google Cloud enables end-to-end confidential applications, protecting sensitive data 'in-use' with hardware isolation. The solution combines Confidential Space (TEE/attestation), Oak Functions (private sandbox), and Oak Session (attested end-to-end encryption for scale). This framework anchors user trust in open-source components, proving confidentiality for sensitive workloads like proprietary GenAI models, even when running behind untrusted load balancers.
DEC. 8, 2025 / Mobile
LiteRT and MediaTek are announcing the new LiteRT NeuroPilot Accelerator. This is a ground-up successor for the TFLite NeuroPilot delegate, bringing seamless deployment experience, state-of-the-art LLM support, and advanced performance to millions of devices worldwide.