
Let’s try an experiment. We’ll show this picture to our multimodal model Gemini and ask it to describe what it sees:
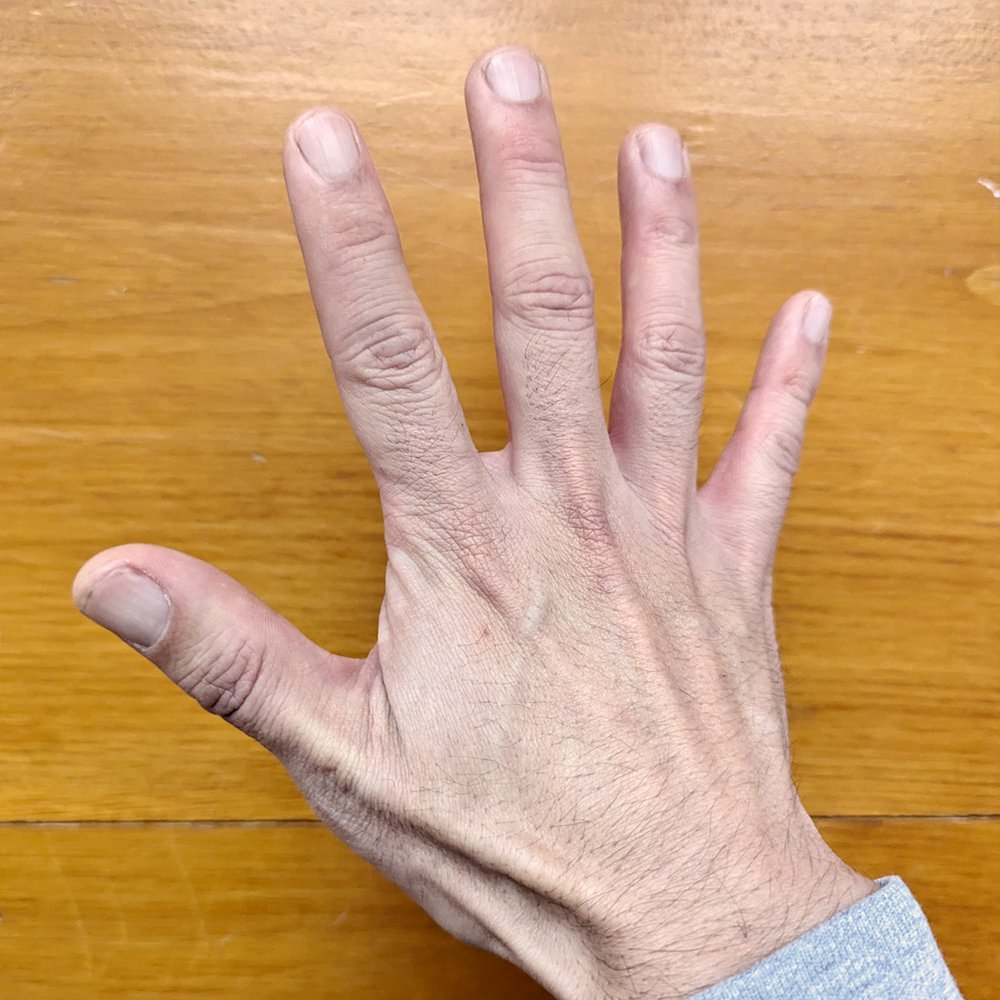
Tell me what you see
Gemini: I see a person's right hand. The hand is open with the fingers spread apart.
Ok, let’s try this one:

Gemini: A person knocking on a wooden door.
How about this one?

Gemini: I see a hand with two fingers extended, which is a common symbol for the number two.
But wait … what if we asked Gemini to reason about all of these images together?

What do you think I'm doing? Hint: it's a game.
Gemini: You're playing rock, paper, scissors.
Nice. What else could we try? Let's see if Gemini can notice this pattern:

I’m playing rock paper scissors. Do you notice a pattern in my gameplay?
Gemini: You are alternating between rock and scissors.
Neat, it spotted the pattern! But does Gemini really know how this game works? Let’s try asking:
Hmm ... do you think it's a good strategy?
Gemini: No, it is not a good strategy. Your opponent will quickly learn your pattern and will be able to win every time. You should try to randomize your choices more.
Good advice, Gemini! Okay, for this last one, let’s put your multimodal reasoning capabilities to the test. Here’s your prompt:
This is a secret message. What does it say?

Can you figure it out? We have gotten Gemini to solve it, but we won’t spoil it by putting the answer in this post. 🙂
Everything we did just now is an example of “multimodal prompting.” We’re basically giving Gemini combinations of different modalities — image and text in this case — and having Gemini respond by predicting what might come next. Gemini’s ability to seamlessly combine these modes together enables new possibilities for what you can do.
In this post, we’ll explore some of the prompting approaches we used in our Hands on with Gemini demo video. We’ll soon be rolling out Gemini for people to try in Google AI Studio, our free, web-based developer tool where you’ll be able to try your own multimodal prompts with Gemini. We’re hoping this guide of starter prompts and ideas helps inspire you to start exploring your own ideas.
Link to Youtube Video (visible only when JS is disabled)
Logic and puzzles are fun way to test Gemini. Let’s try one that requires both left-to-right spatial reasoning and knowledge about our solar system:

Is this the right order? Consider the distance from the sun and explain your reasoning.
Gemini: No, the correct order is Sun, Earth, Saturn. The Sun is the closest to the center of the solar system, followed by the Earth, and then Saturn.
Nice! Here’s another, inspired by pinewood derby challenges:

Which of these cars is more aerodynamic? The one on the left or the right? Explain why, using specific visual details.
Gemini: The car on the right is more aerodynamic. It has a lower profile and a more streamlined shape. The car on the left has a higher profile and a more boxy shape, which makes it less aerodynamic.
Next, what if we showed Gemini a sequence of images? Let’s see we can show a few still frames from a game of charades and have Gemini guess the movie:

Guess what movie I'm acting out.
Gemini: The Matrix
Nice! But which part specifically? Look at my body movements.
Gemini: The part where Neo dodges bullets.
Exploring image sequences really lets you dig into how Gemini reasons over time. Let’s try a classic magic trick.

Explain what I'm doing.
Gemini: You are holding a coin in your right hand.


Where do you think the coin is?
Gemini: The coin is in your right hand.
Sure, that’s a logical answer given what it’s seen. But let’s pull a sleight of hand as we reveal this next image to Gemini...

Look here, what happened?
Gemini: The coin is gone.
Gemini notices it’s gone. But can it summarize what may have happened?
Summarize what may have happened, step by step, starting with the first image.
Gemini:
You started with a coin in your right hand.You then made a motion with your hands, and the coin disappeared.
3. You then showed that the coin was gone.Gemini is leveraging the entire context of this conversation – both text and image – to summarize its answer. Finally, let’s ask:
Can you explain how it disappeared?
Gemini: The coin was palmed.
Gemini makes a really solid guess! But we won’t reveal our secret 🙂.
Let’s try a trick that requires memory and logic: the classic ball and cup shuffling game. For this one, we’ll break it down into steps for Gemini. First, let’s establish the basics with these instructions:
Instructions: There are three cups in position 1 (left), position 2 (middle), position 3 (right).
Notice how we came up with a simple format for remembering where the ball is with “empty, empty, ball.” Next, let’s show Gemini two example turns:
Images:

Swap: 2 and 3
Current state: empty, ball, empty
Images:

Swap: 1 and 2
Current state: ball, empty, empty
In these two example turns, we’re both showing it what a swap looks like, and how to update the ball position. Now, let’s see if Gemini can generalize to a swap it hasn't seen:
Images:

Swap:
Here's Gemini's response:
1 and 3
Current state: empty, empty, ball
Gemini got it! It looked at these images and correctly inferred that cups 1 and 3 are being swapped. And it reasoned correctly about how to update the ball position. Let’s ask:
Tell me where the ball is and summarize how it got there, in paragraph form.
Gemini: The ball is in cup 3.
Starting with the ball in cup 3, the first swap was cup 2 and 3. This put the ball in cup 2. The second swap was cup 1 and 2. This put the ball in cup 1. The third swap was cup 1 and 3. This put the ball in cup 3.
Not only did Gemini get the answer correctly, it accurately summarized the game history. Of course, it won’t always get this challenge right. Sometimes the fake out move (where you swap two empty cups) seems to trip it up, but sometimes it gets that too. But simple prompts like this make it really fun to rapidly test Gemini. You can change the variables in your prompt, including the order of swaps, and see how it does.
If you want to use Gemini in your own apps, you’ll want it to be able to connect to other tools. Let’s try a simple idea where Gemini needs to combine multimodality with tool use: drawing a picture to search for music.
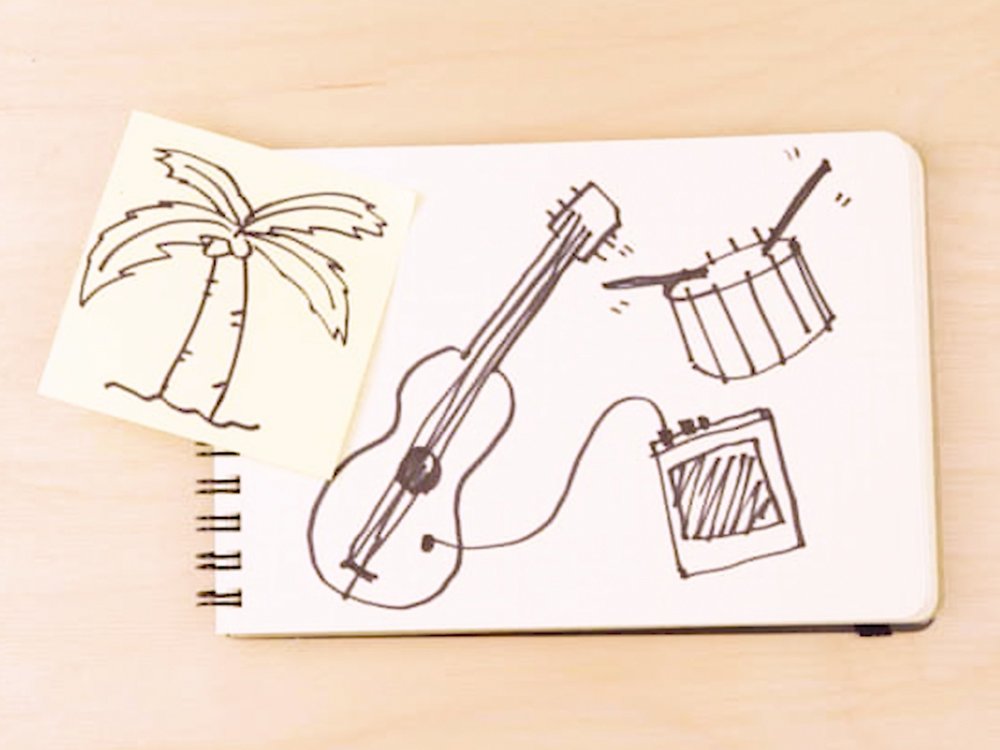
Step 1. Look at this drawing, describe everything in it, and come up with a fun, specific idea for a good musical soundtrack genre, mood, or soundtrack.
Step 2. Provide a search query in the form: "Search [insert query]"
Gemini:
The drawing is of a guitar, drums, and an amplifier. There is also a palm tree. The mood is fun, upbeat, and tropical. The genre is reggae. The soundtrack could be used for a movie or TV show set in a tropical location.
Search "Reggae music for a tropical vacation"
Nice! Gemini both reasons about what it sees and then generates a search query you can parse to do a search. It’s like Gemini is acting like a translator for you – but instead of translating between languages, it’s translating modalities – from drawing to music in this case. With multimodal prompting, you can use Gemini to invent your own entirely new translations between different inputs and outputs.
What if we tried using Gemini to quickly prototype a multimodal game? Here’s an idea: a geography guessing game where you have to point at a map to make your guess. Let’s start by prompting Gemini with the core idea:
Instructions: Let's play a game. Think of a country and give me a clue. The clue must be specific enough that there is only one correct country. I will try pointing at the country on a map.
Next, let’s give Gemini an example turn of gameplay, showing it how we want it to handle both incorrect and correct answers:
Country: This country is huge island that is mostly covered in ice.
(Answer: Greenland)
Guess:
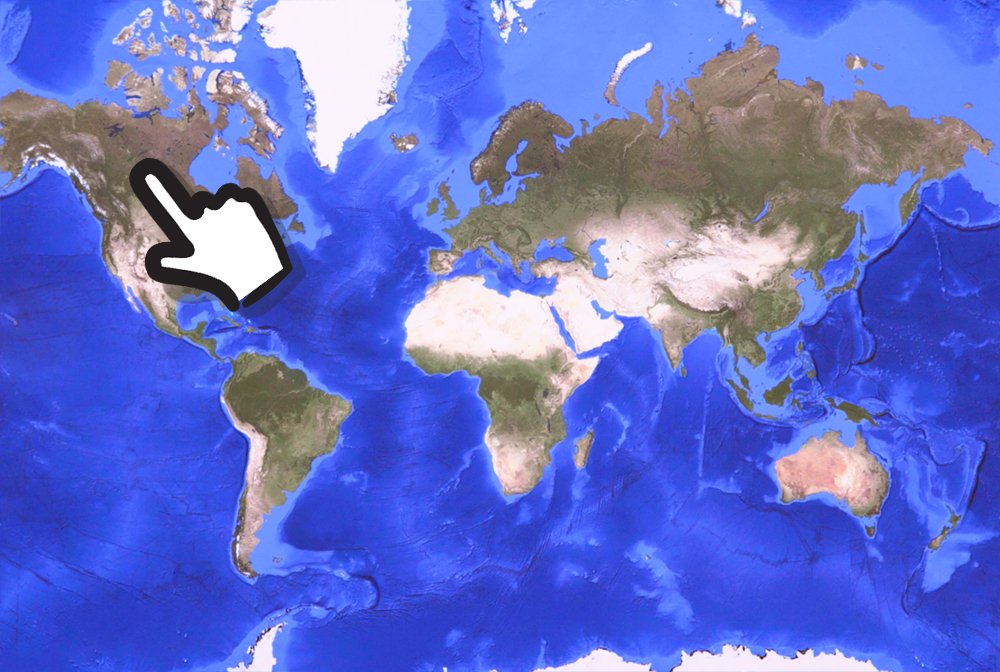
I am pointing at the country of Canada *incorrect*
Guess:
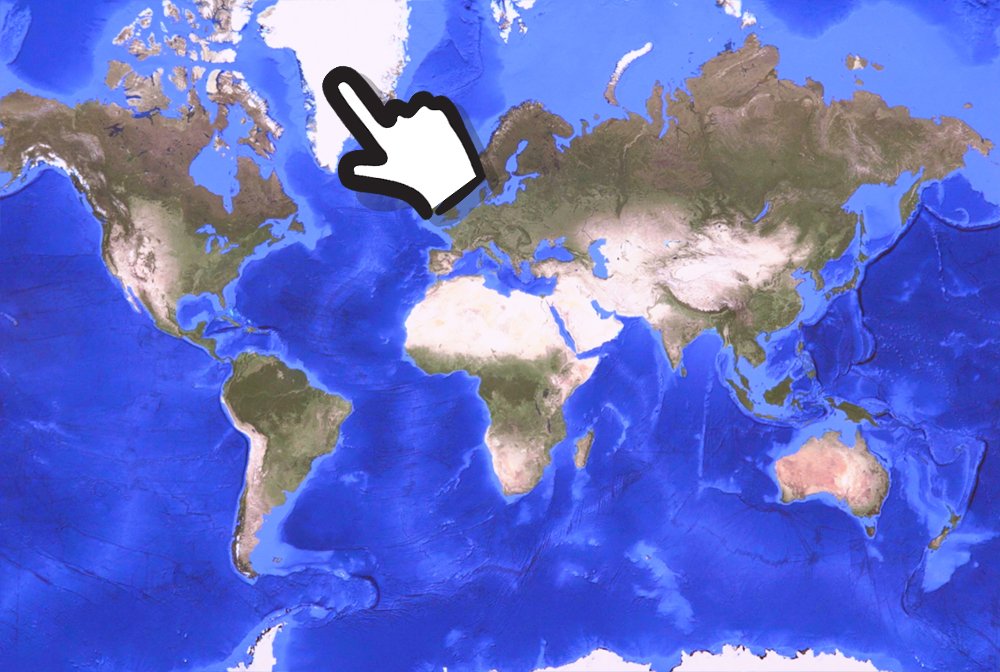
I am pointing at the country of Greenland *correct*
Let’s give it a go and prompt Gemini to generate a clue:
Clue:
This country is known for its unique wildlife, including kangaroos and koalas. (Answer: Australia)
Ok, that’s a good clue. Let’s test out whether pointing will work. Just for fun, let’s try pointing at the wrong place first:
Guess:
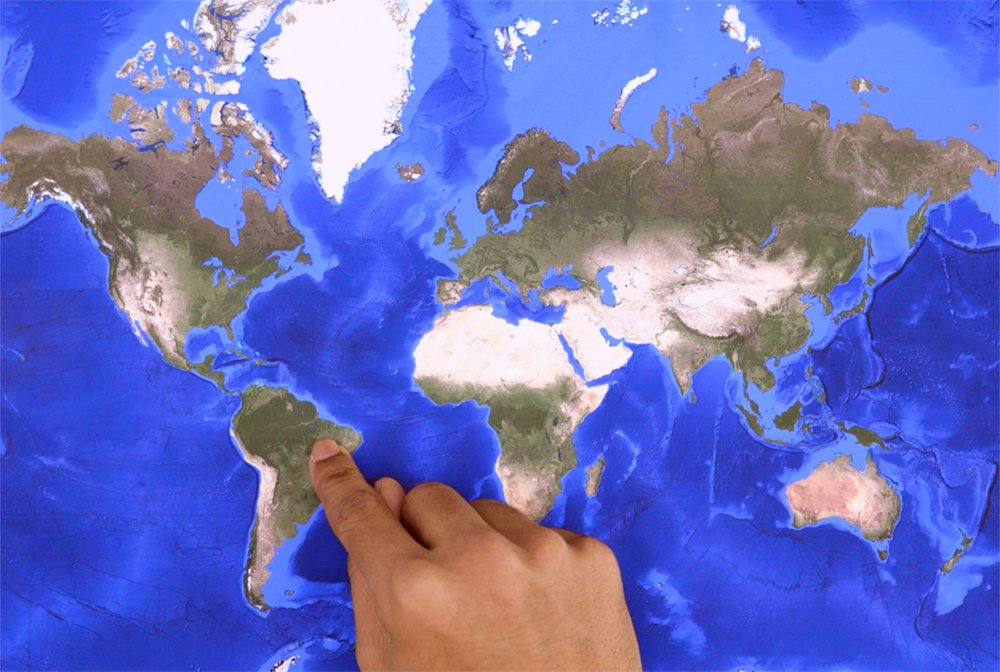
I am pointing at the country of Brazil *incorrect*
Great! Gemini looked at my image and figured out I’m pointing at Brazil, and correctly reasoned that’s wrong. Now let’s point at the right place on the map:
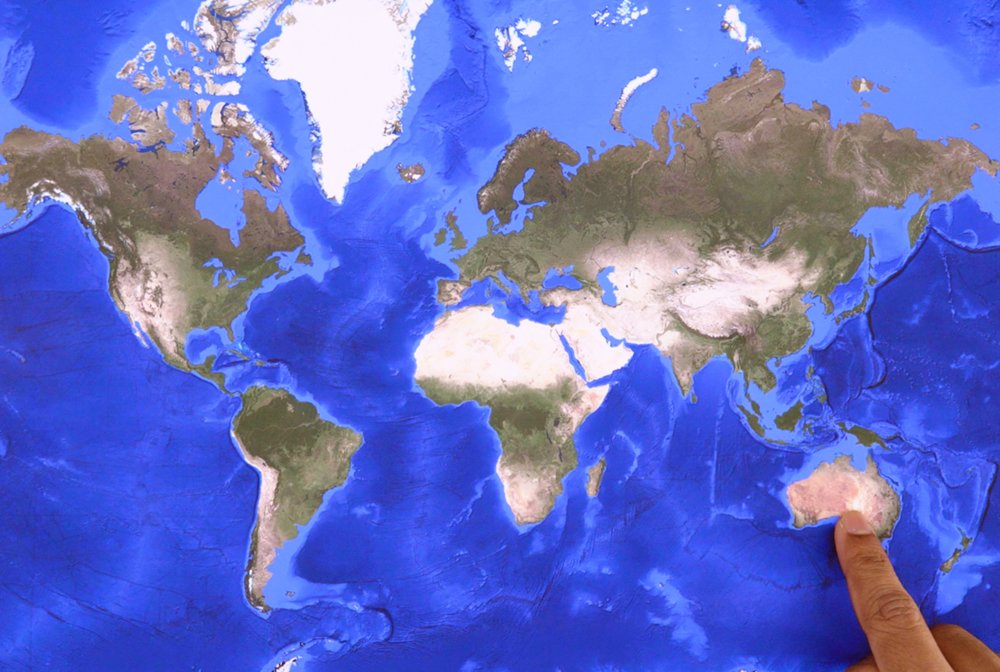
I am pointing at the country of Australia *correct*
Nice! We’ve basically taught Gemini our game logic just by giving it an example. You'll also notice that it generalized from the illustrated hand in the examples.
Of course, to bring your game idea to life, you’ll eventually have to write some executable code. Let’s see if Gemini can make a simple countdown timer for a game, but with a few fun twists:
Implement a simple timer in HTML/CSS/Javascript. Use a sans serif font and dark mode. Start it at 10 seconds and start counting down. When it reaches zero, replace the timer with a random emoji that is associated with excitement and motivation! Then go back to the timer at 10 seconds and start counting down again.
With just this single instruction, Gemini gives us a working timer that does what we asked for:
My favorite part is scrolling through Gemini’s source code to find the array of motivational emojis it picked for me:
const emojis = ['🚀', '⚡️', '🎉', '🎊', '🥳', '🤩', '✨'];
Throughout this post, we’ve been giving Gemini an input, and having Gemini make predictions for what might come next. That's basically what prompting is. And our inputs have been multimodal – image and text, combined.
But so far we've only shown Gemini responding in text. Maybe you’re wondering, can Gemini also respond with a combination of image and text? It can! This is a capability of Gemini called “interleaved text and image generation.” While this feature won’t be ready in the first version of Gemini for people to try, we hope to roll it out soon. Here’s a sneak peek of what’s possible.
Let’s see if we could use Gemini to provide everyday creative inspiration. And let’s try it in a domain that requires a bit of multimodal reasoning ... knitting! 🧶. Similar to our map game above, let's provide one example turn of interaction:
Give me three ideas for crochet creations I could make with these two colors:

Colors: I see blue and yellow yarn.
Idea 1: How about a cute dog with one yellow ear?
Image 1:

Idea 2: Or how about a jellyfish with a few yellow tentacles?
Image 2:

Idea 3: Or how about a blue cat with a yellow nose?
Image 3:

We’re essentially teaching Gemini about how we want each interaction to go: “I’ll take a photo of two balls of yarn, and I expect you (Gemini) to both come up with an idea for something I could make, and generate an image of it.”
Now, let’s show it a new pair of yarn colors it hasn't yet seen, and see if it can generalize:
Give me three ideas for crochet creations I could make with these two colors:

Gemini:
Colors: I see blue and pink yarn.
Idea 1: How about a pig with blue ears?
Image 1:

Idea 2: Or an octopus with pink and blue tentacles?
Image 2:

Idea 3: Or a bunny with a pink nose?
Image 3:

Nice! Gemini correctly reasoned about the new colors (“I see blue and pink yarn”) and generated these ideas and the images in a single, interleaved output of text and image.
What Gemini did here is fundamentally different from today’s text-to-image models. It's not just passing an instruction to a separate text-to-image model. It sees the image of my actual yarn on my wooden table, truly doing multimodal reasoning about my text and image together.
We hope you found this a helpful starter guide to get a sense of what’s possible with Gemini. We’re very excited to roll it out to more people soon so you can explore your own ideas through prompting. Stay tuned!

Run Ray on TPU, Part 1: The foundations

Expanding Choice in Gemini Enterprise Agent Platform: Introducing Grounding with Parallel Web Search

ML Development in VS Code with Google Cloud Power: Workbench Extension Now Available

We terminated a TPU mid-training and it recovered in seconds: Introduction to elastic training with MaxText