

No cenário altamente dinâmico dos modelos de linguagem grandes (LLMs, na sigla em inglês), o destaque tem se concentrado principalmente na arquitetura somente decodificador. Embora esses modelos tenham demonstrado capacidades impressionantes em uma ampla gama de tarefas de geração, a arquitetura clássica de codificador-decodificador, como o T5 (The Text-to-Text Transfer Transformer), continua sendo uma escolha popular para muitas aplicações do mundo real. Os modelos codificadores-decodificadores geralmente se destacam em resumos, traduções, controle de qualidade e muitas outras tarefas devido à sua alta eficiência de inferência, flexibilidade de projeto e representação de codificador mais completa para entender a entrada. No entanto, a poderosa arquitetura de codificador-decodificador sempre recebeu uma atenção relativamente baixa.
Hoje, revisitamos essa arquitetura e apresentamos o T5Gemma, uma nova coleção de LLMs codificadores-decodificadores desenvolvida por meio da conversão de modelos somente decodificadores pré-treinados na arquitetura de codificador-decodificador usando uma técnica chamada "adaptação". O T5Gemma é baseado no framework do Gemma 2, incluindo modelos Gemma 2 2B e 9B adaptados, além de um conjunto de modelos de tamanho T5 (Small, Base, Large e XL) recém-treinados. Temos o prazer de apresentar à comunidade os modelos T5Gemma pré-treinados e com ajuste de instruções para desbloquear novas oportunidades de pesquisa e desenvolvimento.
No T5Gemma, fizemos a seguinte pergunta: seria possível criar modelos codificadores-decodificadores avançados com base em modelos somente decodificadores pré-treinados? Respondemos a essa pergunta explorando uma técnica chamada adaptação de modelo. A ideia principal é inicializar os parâmetros de um modelo codificador-decodificador usando os pesos de um modelo somente decodificador já pré-treinado e, em seguida, adaptá-los ainda mais usando o pré-treinamento baseado em UL2 ou PrefixLM.
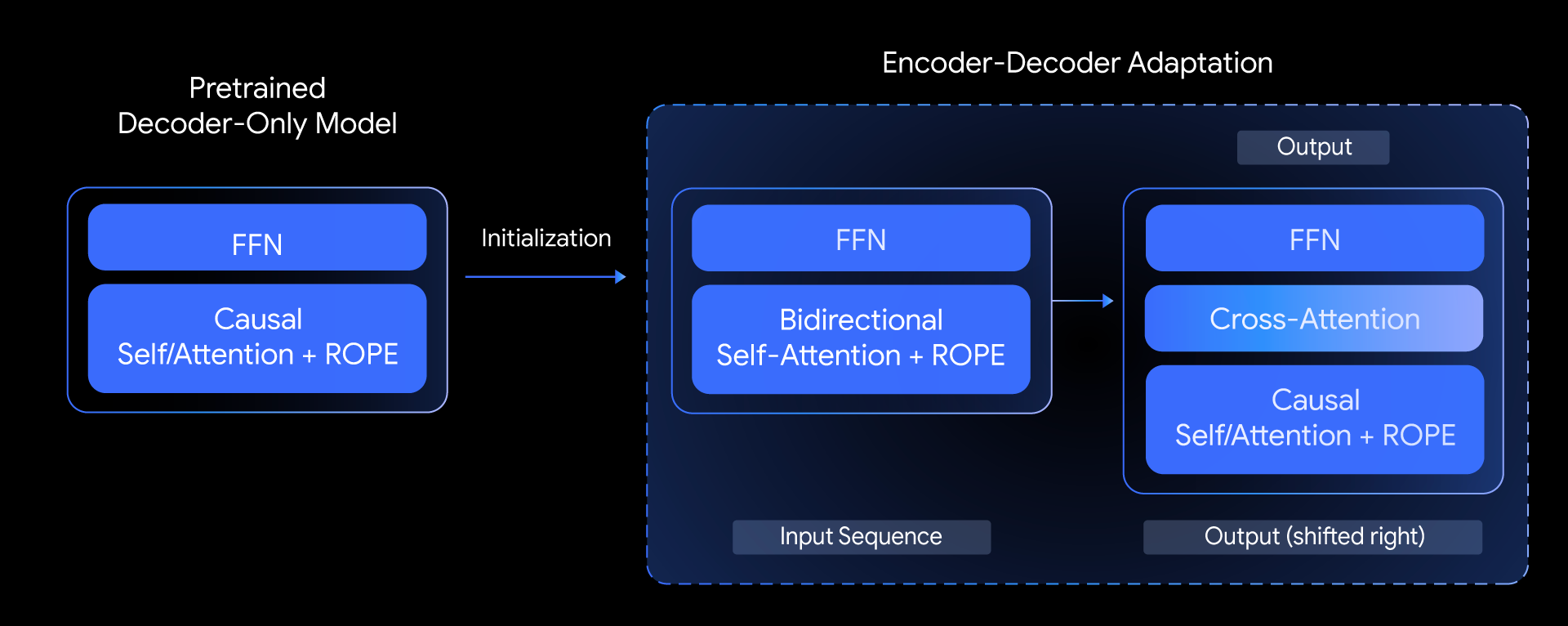
Esse método de adaptação é altamente flexível, permitindo combinações criativas de tamanhos de modelo. Por exemplo, podemos parear um codificador grande com um decodificador pequeno (como um codificador 9B com um decodificador 2B) para criar um modelo "desequilibrado". Isso nos permite ajustar a proporção entre qualidade e eficiência para tarefas específicas, como os resumos, nos quais uma compreensão profunda da entrada é mais crítica do que a complexidade da saída gerada.
Como é o desempenho do T5Gemma?
Em nossos experimentos, os modelos T5Gemma alcançaram um desempenho comparável ou melhor do que o de seus equivalentes Gemma somente decodificadores, quase dominando a fronteira de pareto de eficiência entre qualidade e inferência em vários comparativos de mercado, como o SuperGLUE, que mede a qualidade da representação aprendida.
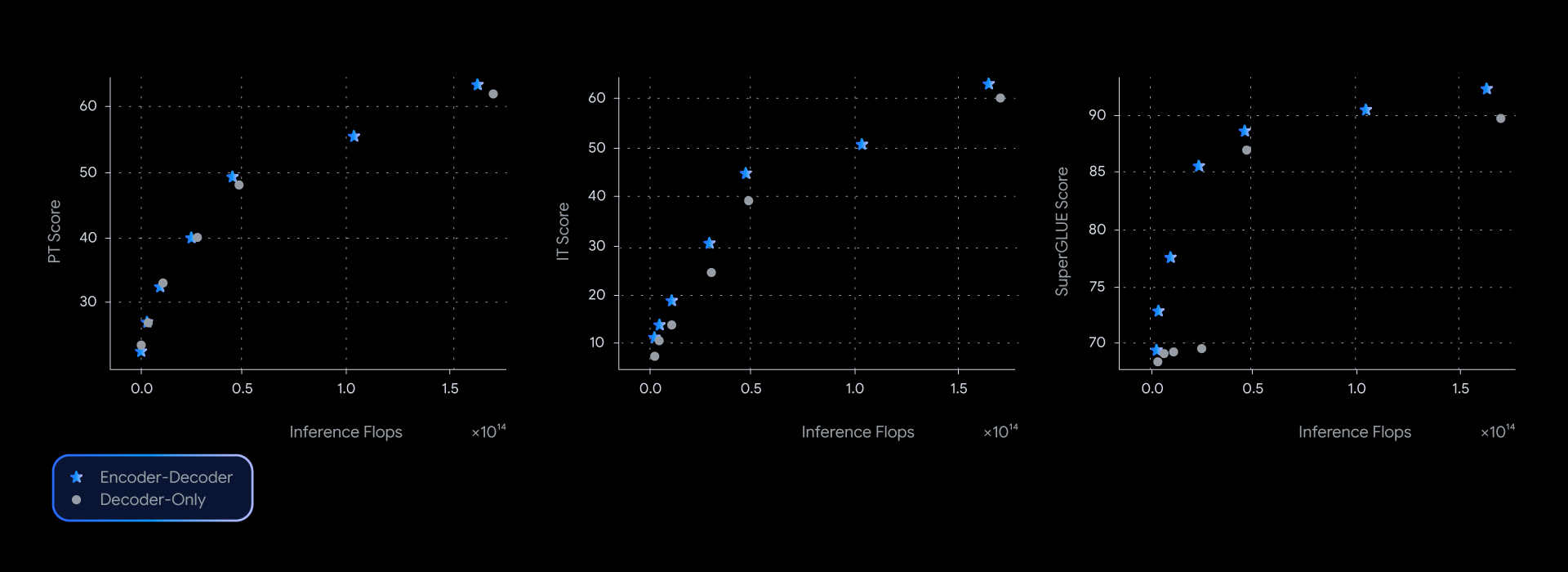
Essa vantagem de desempenho não é apenas teórica; ela também se traduz em qualidade e velocidade no uso real. Na medição da latência real para GSM8K (raciocínio matemático), o T5Gemma teve uma vitória clara. Por exemplo, o T5Gemma 9B-9B atinge maior acurácia do que o Gemma 2 9B, mas com latência semelhante. Ainda mais impressionante, o T5Gemma 9B-2B oferece um aumento significativo de acurácia em relação ao modelo 2B-2B, mas sua latência é quase idêntica à do modelo Gemma 2 2B, que é muito menor. Em última análise, esses experimentos mostram que a adaptação codificador-decodificador oferece uma maneira flexível e poderosa de equilibrar a qualidade e a velocidade de inferência.
Os LLMs codificadores-decodificadores poderiam ter capacidades semelhantes às dos modelos somente decodificadores?
Sim, o T5Gemma demonstra ter capacidades promissoras antes e depois do ajuste de instruções.
Após o pré-treinamento, o T5Gemma atinge ganhos impressionantes em tarefas complexas que exigem raciocínio. Por exemplo, o T5Gemma 9B-9B atinge mais de 9 pontos a mais em GSM8K (raciocínio matemático) e 4 pontos a mais em DROP (compreensão de leitura) do que o modelo Gemma 2 9B original. Esse padrão demonstra que a arquitetura de codificador-decodificador, quando inicializada via adaptação, tem o potencial de criar um modelo fundamental mais capacitado e de alto desempenho.
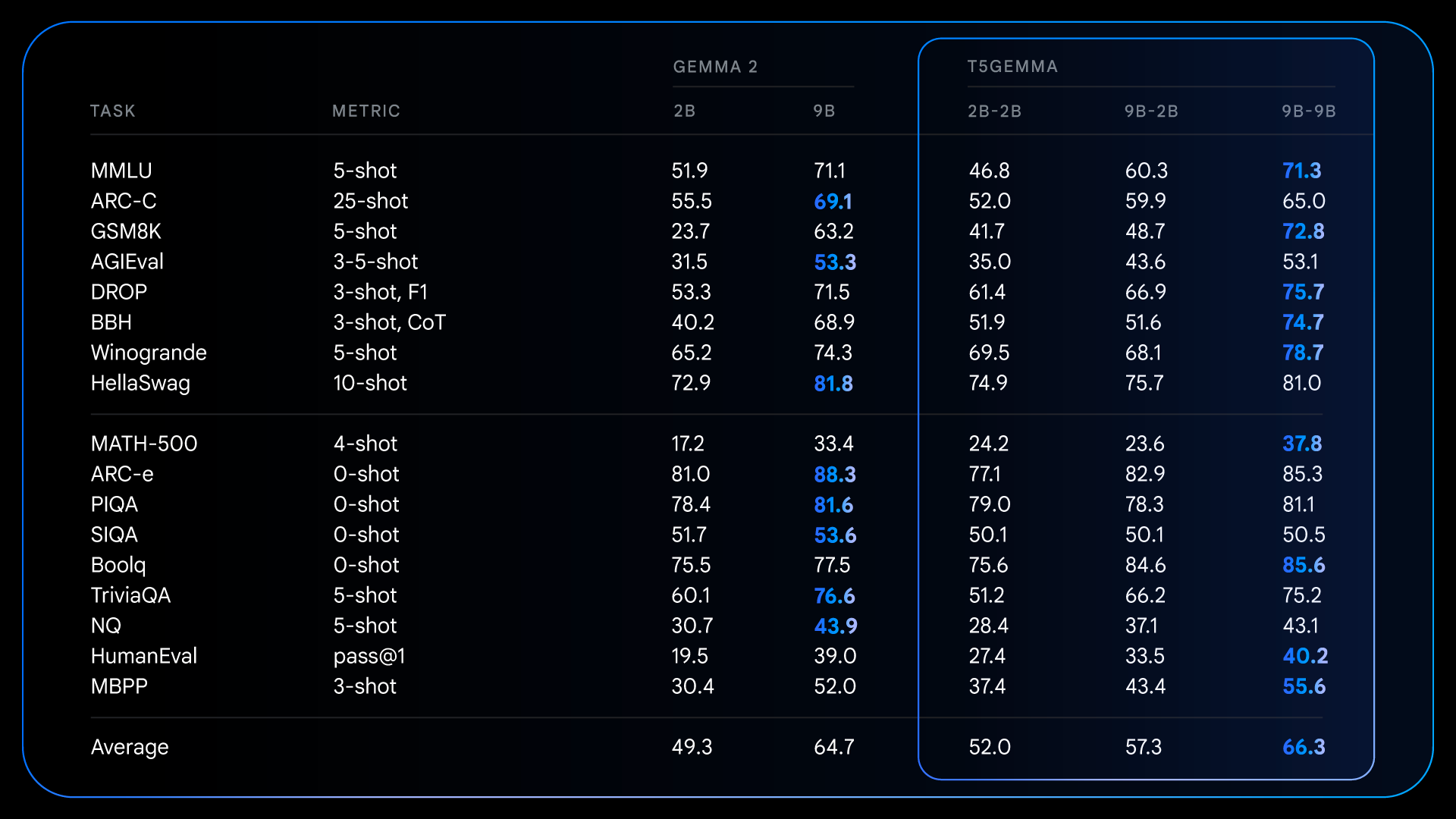
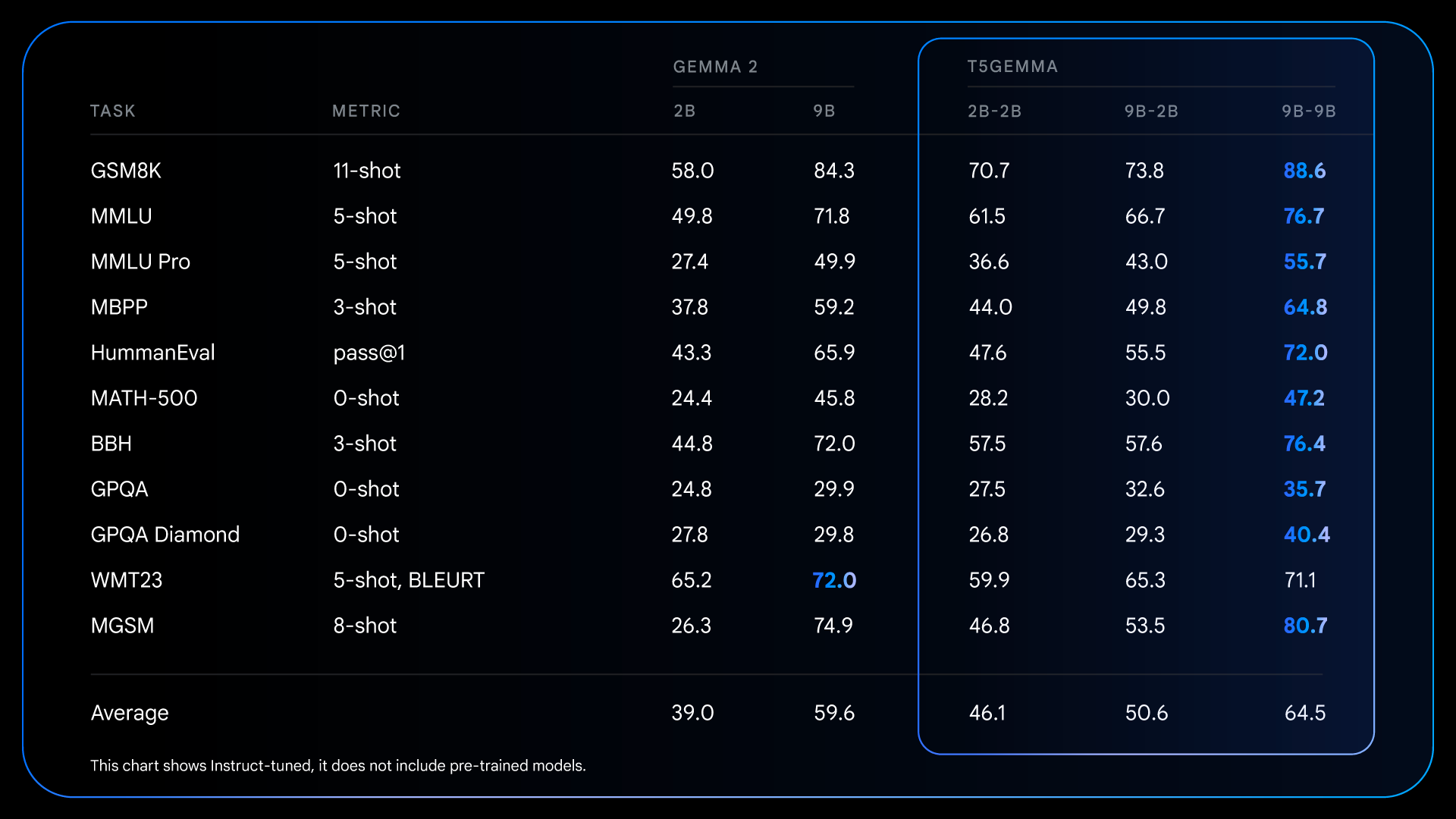
Essas melhorias fundamentais do pré-treinamento preparam o terreno para ganhos ainda mais dramáticos após o ajuste de instruções. Por exemplo, na comparação do Gemma 2 IT com o T5Gemma IT, a lacuna de desempenho aumenta significativamente em todos os aspectos. O T5Gemma 2B-2B IT vê sua pontuação do MMLU aumentar em quase 12 pontos em relação ao Gemma 2 2B, e sua pontuação no GSM8K aumenta de 58% para 70,7%. A arquitetura adaptada não apenas tem o potencial de oferecer um ponto de partida melhor, como também responde de forma mais eficaz ao ajuste de instruções, levando a um modelo final substancialmente mais capacitado e útil.
Temos o grande prazer de apresentar este novo método de criação de modelos codificadores-decodificadores de uso geral poderosos por meio da adaptação de LLMs somente decodificadores pré-treinados, como o Gemma 2. Para ajudar a acelerar ainda mais as pesquisas e permitir que a comunidade aprimore esse trabalho, anunciamos o lançamento de um pacote de nossos pontos de verificação do T5Gemma.
O lançamento inclui:
Esperamos que esses pontos de verificação sejam um recurso valioso para investigar a arquitetura, a eficiência e o desempenho de modelos.
Mal podemos esperar para ver o que você vai criar com o T5Gemma. Consulte os links a seguir para obter mais informações:
Introducing LangExtract: A Gemini powered information extraction library
Apresentamos o Opal: descreva, crie e compartilhe miniapps de IA
Inovação multilíngue em LLMs: como os modelos abertos ajudam a desbloquear a comunicação global

A roboticist's journey with JAX: Finding efficiency in optimal control and simulation

Apresentamos o Gemma 3n: o guia para desenvolvedores