

O TensorFlow Lite tem sido uma ferramenta eficiente para o aprendizado de máquina no dispositivo desde seu lançamento em 2017, e o MediaPipe ampliou ainda mais essa eficiência em 2019 ao oferecer suporte a pipelines completos de ML. Embora essas ferramentas inicialmente se concentrassem em modelos menores no dispositivo, o dia de hoje marca uma grande mudança com a API MediaPipe LLM Inference experimental.
Com esse lançamento, os modelos de linguagem grandes (LLMs, na sigla em inglês) podem ser executados totalmente no dispositivo em todas as plataformas. Esse novo recurso é particularmente transformador, considerando as demandas de memória e computação dos LLMs, que são mais de cem vezes maiores que as demandas dos modelos tradicionais no dispositivo. As otimizações na pilha no dispositivo tornam isso possível, incluindo novas ops, quantização, armazenamento em cache e compartilhamento de pesos.
A API MediaPipe LLM Inference experimental multiplataforma, projetada para simplificar a integração de LLM no dispositivo para desenvolvedores da Web, é compatível com Web, Android e iOS, com suporte inicial a quatro LLMs disponíveis abertamente: Gemma, Phi 2, Falcon e Stable LM. Com ela, pesquisadores e desenvolvedores têm a flexibilidade de criar protótipos de modelos de LLM populares disponíveis abertamente no dispositivo e testá-los.
No Android, a API MediaPipe LLM Inference destina-se apenas ao uso experimental e de pesquisa. Os aplicativos de produção com LLMs podem usar a API Gemini ou o Gemini Nano no dispositivo por meio do Android AICore. O AICore é o novo recurso de nível de sistema introduzido no Android 14 para fornecer soluções com tecnologia Gemini para dispositivos de última geração, incluindo integrações com os mais recentes aceleradores de ML, com adaptadores LoRA otimizados para casos de uso e com filtros de segurança. Para começar a usar o Gemini Nano no dispositivo com seu app, inscreva-se no Pré-lançamento de acesso antecipado.
A partir de hoje, você pode testar a API MediaPipe LLM Inference por meio de nossa demonstração na Web ou criando nossos apps de demonstração de exemplo. Você pode experimentá-la e integrá-la a projetos usando nossos SDKs para Web, Android ou iOS.
Com a API LLM Inference, você pode incluir LLMs no dispositivo em apenas algumas etapas. Essas etapas se aplicam à Web, ao iOS e ao Android, embora o SDK e a API nativa sejam específicos de plataforma. Os exemplos de código a seguir mostram o SDK para Web.
2. Converta os pesos de modelo em um flatbuffer do TensorFlow Lite usando o pacote MediaPipe Python.
from mediapipe.tasks.python.genai import converter
config = converter.ConversionConfig(...)
converter.convert_checkpoint(config)3. Inclua o SDK do LLM Inference no aplicativo.
import { FilesetResolver, LlmInference } from "https://cdn.jsdelivr.net/npm/@mediapipe/tasks-genai”4. Hospede o flatbuffer do TensorFlow Lite com o aplicativo.
5. Use a API LLM Inference para aplicar um prompt de texto e obter uma resposta de texto do modelo.
const fileset = await FilesetResolver.forGenAiTasks("https://cdn.jsdelivr.net/npm/@mediapipe/tasks-genai/wasm");
const llmInference = await LlmInference.createFromModelPath(fileset, “model.bin”);
const responseText = await llmInference.generateResponse("Hello, nice to meet you");
document.getElementById('output').textContent = responseText;Consulte a documentação e os exemplos de código para obter uma explicação detalhada de cada uma dessas etapas.
Estes são gifs em tempo real do Gemma 2B em execução por meio da API MediaPipe LLM Inference.
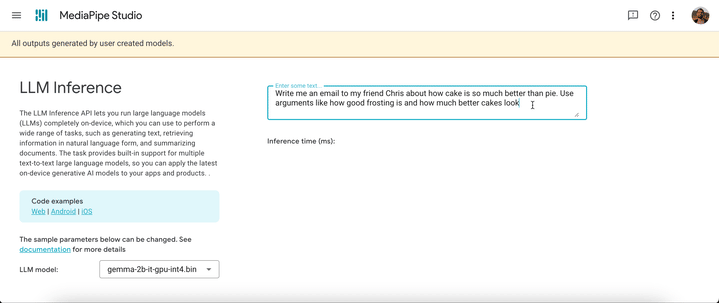
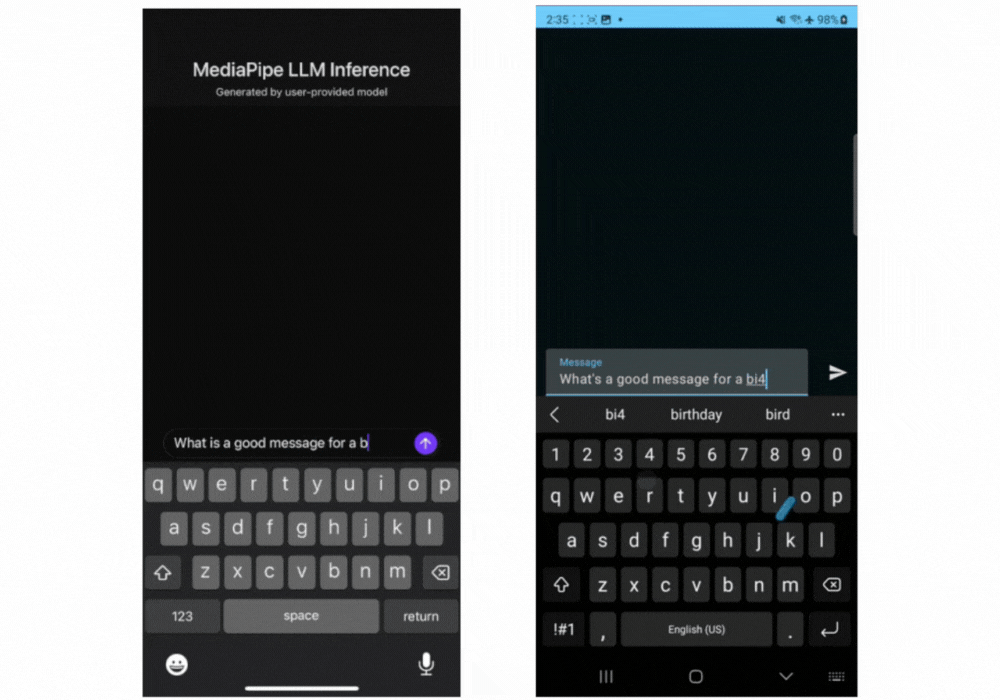
A versão inicial é compatível com as quatro arquiteturas de modelo a seguir. Quaisquer pesos de modelo compatíveis com essas arquiteturas funcionarão com a API LLM Inference. Use os pesos de modelo base, use uma versão dos pesos ajustada pela comunidade ou ajuste os pesos usando seus próprios dados.
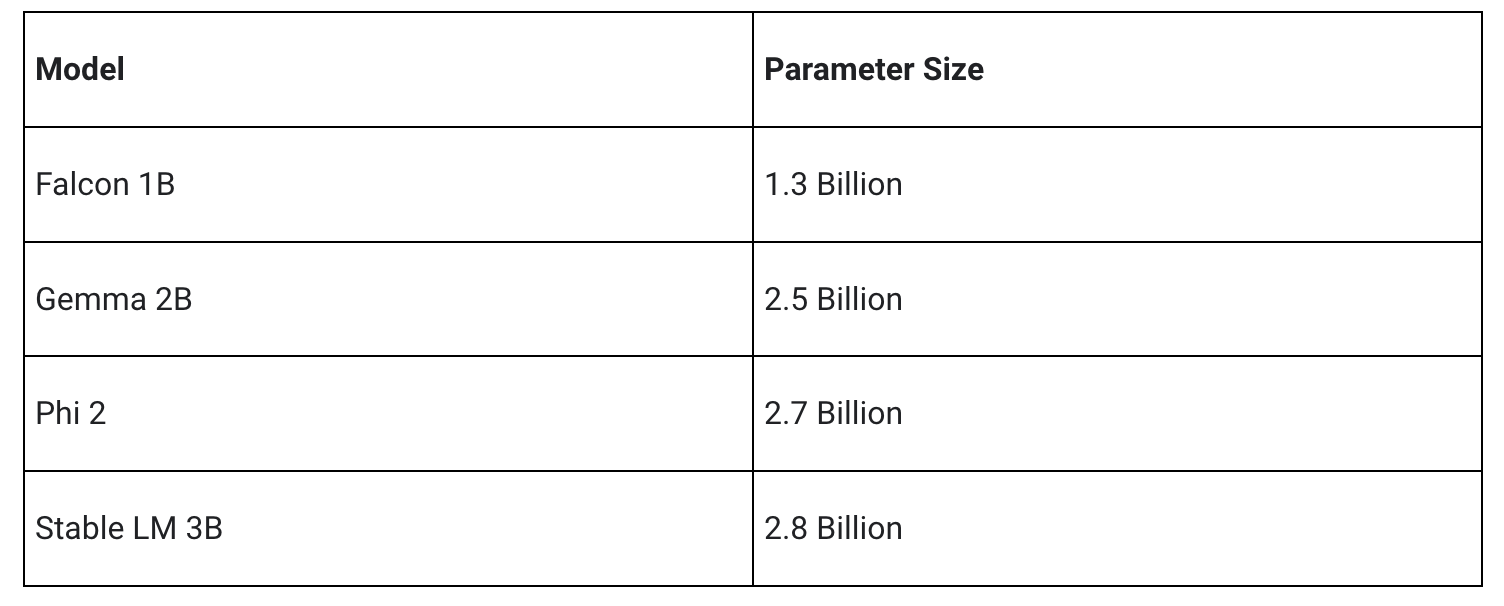
Por meio de otimizações significativas, algumas das quais são detalhadas abaixo, a API MediaPipe LLM Inference é capaz de fornecer latência de última geração no dispositivo, com foco em CPU e GPU para suportar várias plataformas. Para um desempenho sustentado em um ambiente de produção em telefones premium selecionados, o Android AICore pode usar aceleradores neurais específicos de hardware.
Ao medir a latência de um LLM, é necessário considerar alguns termos e algumas medidas. O Tempo para o primeiro token e a Velocidade de decodificação serão os dois elementos mais significativos, pois medem a rapidez com que você obtém o início da resposta e a rapidez com que a resposta é gerada assim que começa.
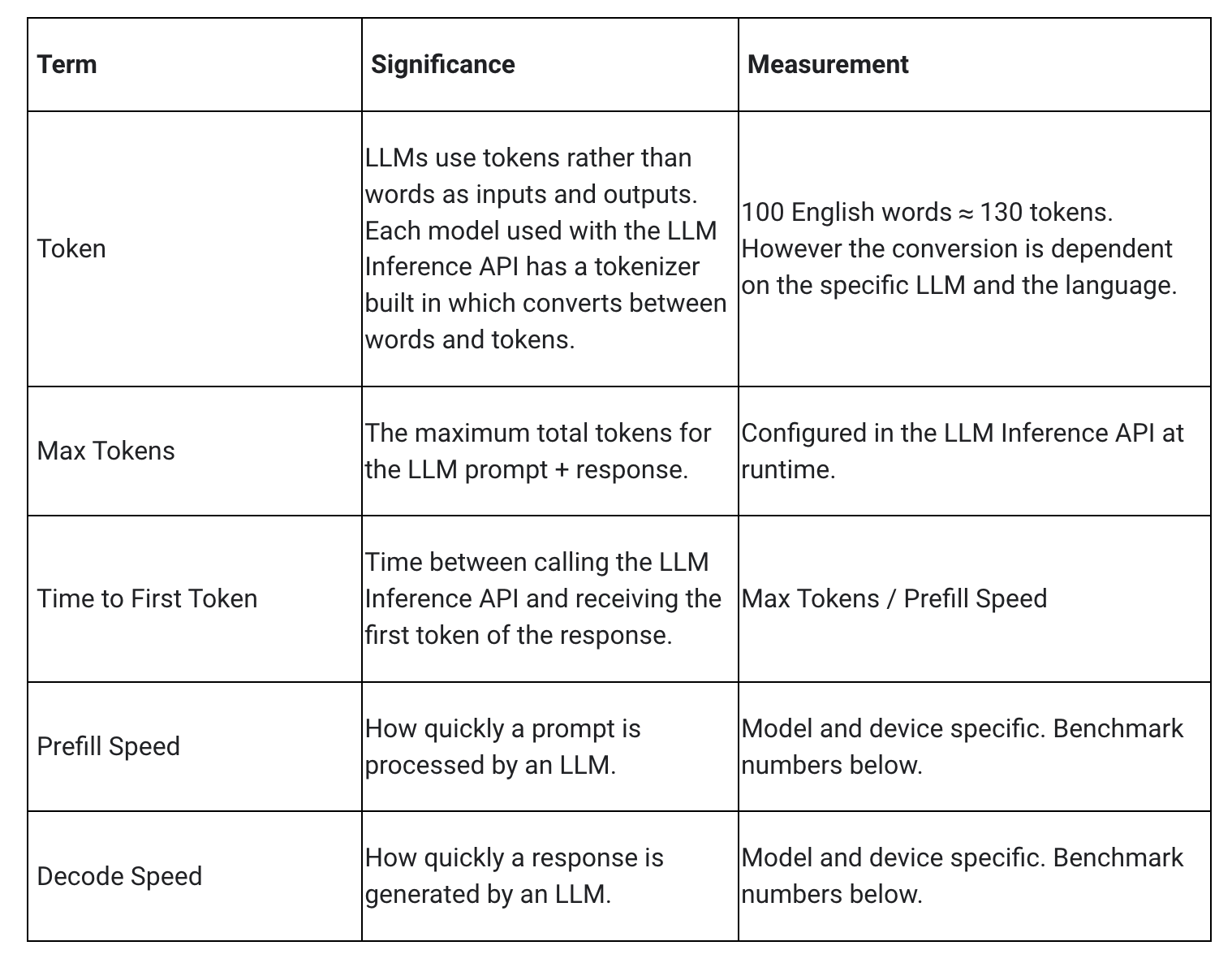
A Velocidade de preenchimento e a Velocidade de decodificação dependem do modelo, do hardware e do Máximo de tokens. Elas também podem mudar dependendo da carga atual do dispositivo.
As seguintes velocidades foram obtidas em dispositivos de última geração usando um máximo de tokens de 1280 tokens, um prompt de entrada de 1024 tokens e uma quantização de peso int8. A exceção é Gemma 2B (int4), encontrada aqui no Kaggle, que usa uma quantização mista de peso de 4/8 bits.
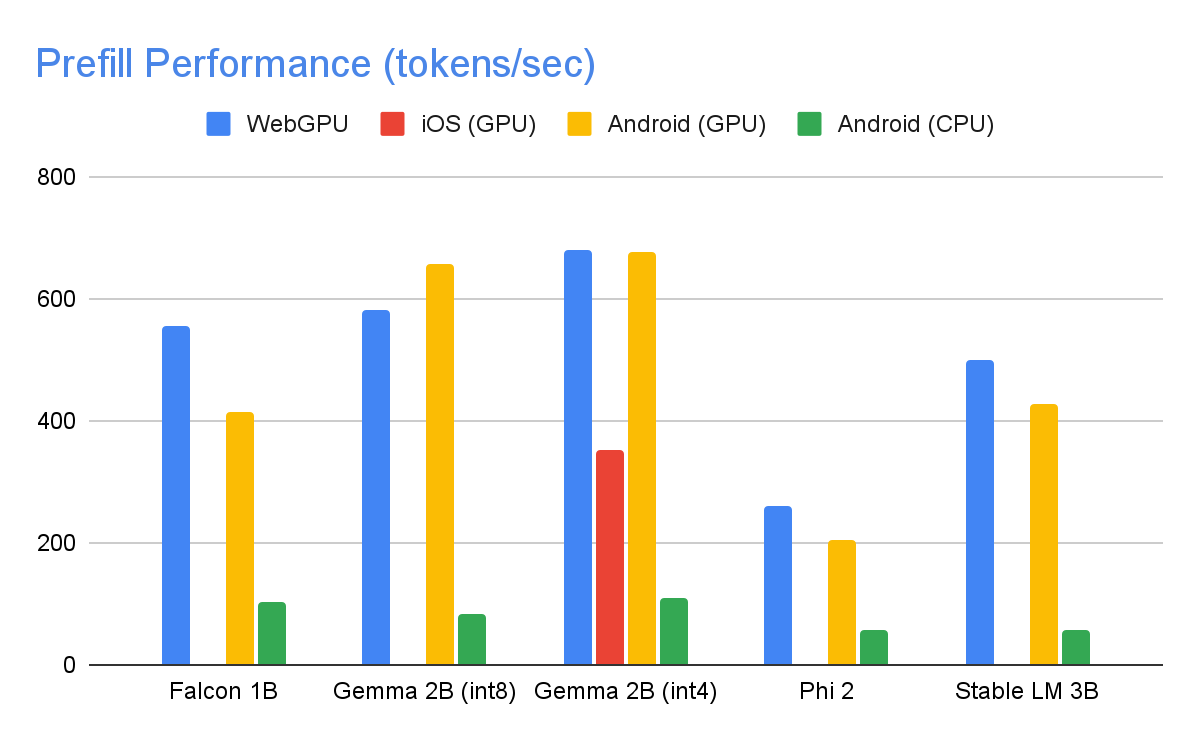
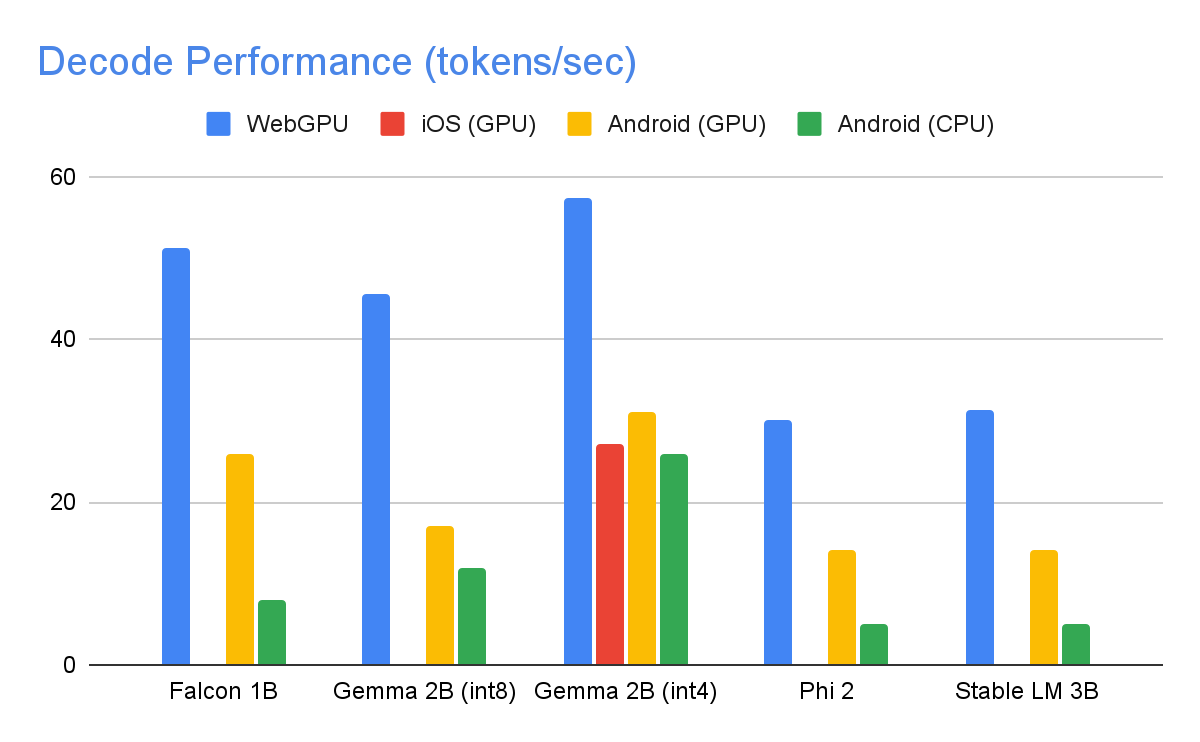
Para alcançar os números de desempenho acima, inúmeras otimizações foram feitas no MediaPipe, TensorFlow Lite, XNNPack (nossa biblioteca de operadores de rede neural de CPU) e no tempo de execução acelerado por GPU. A seguir, estão algumas otimizações que resultaram em melhorias significativas de desempenho.
Compartilhamento de pesos: o processo de inferência de LLM engloba duas fases: uma fase de preenchimento e uma fase de decodificação. Tradicionalmente, essa configuração exigiria dois contextos de inferência separados, cada um gerenciando recursos independentemente para seu modelo de ML correspondente. Diante das demandas de memória dos LLMs, adicionamos um recurso que permite compartilhar os pesos e o cache de KV em contextos de inferência. Embora o compartilhamento de pesos possa parecer simples, ele tem implicações significativas de desempenho ao compartilhar entre operações vinculadas à computação e à memória. Em cenários típicos de inferência de ML, em que os pesos não são compartilhados com outros operadores, eles são minuciosamente configurados para cada operador totalmente conectado separadamente para garantir o desempenho ideal. O compartilhamento de pesos com outro operador implica uma perda de otimização por operador, e isso exige a criação de novas implementações de kernel que possam ser executadas com eficiência mesmo em pesos abaixo do ideal.
Ops totalmente conectadas otimizadas: a operação FULLY_CONNECTED do XNNPack passou por duas otimizações significativas para inferência de LLM. Primeiro, a quantização de intervalo dinâmico mescla perfeitamente os benefícios computacionais e de memória da quantização inteira completa com as vantagens de precisão da inferência de ponto flutuante. A utilização de pesos int8/int4 aumenta a capacidade de processamento da memória e alcança um desempenho notável, principalmente com a decodificação eficiente no registro de pesos de 4 bits que requerem apenas uma instrução adicional. Em segundo lugar, usamos ativamente as instruções I8MM nas CPUs ARM v9 que permitem a multiplicação de uma matriz int8 2x8 por uma matriz int8 8x2 em uma única instrução, resultando em duas vezes a velocidade da implementação baseada em produto escalar NEON.
Balanceamento de computação e memória: ao traçar o perfil da inferência de LLM, identificamos limitações distintas para ambas as fases: a fase de preenchimento enfrenta restrições impostas pela capacidade de computação, enquanto a fase de decodificação é restrita pela largura de banda da memória. Consequentemente, cada fase emprega diferentes estratégias para desquantização dos pesos int8/int4 compartilhados. Na fase de preenchimento, cada operador de convolução primeiro desquantiza os pesos em valores de ponto flutuante antes da computação principal, garantindo um desempenho ideal para convoluções com uso intenso de computação. Por outro lado, a fase de decodificação minimiza a largura de banda da memória adicionando a computação de desquantização às principais operações de convolução matemática.
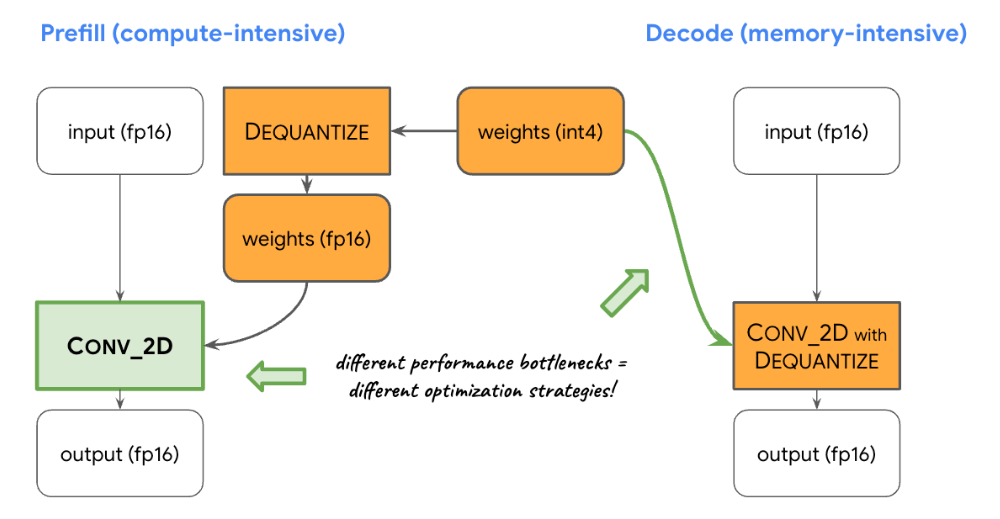
Operadores personalizados: para a inferência de LLM acelerada por GPU no dispositivo, usamos amplamente operações personalizadas para mitigar a ineficiência causada por vários sombreadores pequenos. Essas ops personalizadas permitem que fusões de operadores especiais e vários parâmetros de LLM, como ID de token, tamanho de patch de sequência e parâmetros de amostragem, sejam empacotados em um Tensor personalizado e especializado, utilizado principalmente dentro dessas operações especializadas.
Pseudodinamismo: no bloco de atenção, encontramos operações dinâmicas que aumentam com o tempo à medida que o contexto se expande. Como nosso tempo de execução de GPU não tem suporte para ops/Tensores dinâmicos, optamos por operações fixas com um tamanho máximo de cache predefinido. Para reduzir a complexidade computacional, introduzimos um parâmetro que permite pular certos cálculos de valor ou processar dados reduzidos.
Layout otimizado de cache de KV: como as entradas no cache de KV atuam, em última análise, como pesos para convoluções, usadas no lugar das multiplicações de matrizes, armazenamos essas entradas em um layout especializado adaptado para pesos de convolução. Esse ajuste estratégico elimina a necessidade de conversões extras ou a dependência de layouts não otimizados e, portanto, contribui para um processo mais eficiente e simplificado.
O entusiasmo é muito grande por conta das otimizações e do desempenho presentes no lançamento experimental de hoje da API MediaPipe LLM Inference. E isso é só o começo. Em 2024, expandiremos para mais plataformas e modelos e ofereceremos ferramentas de conversão mais amplas, componentes no dispositivo sem custo financeiro, tarefas de alto nível e muito mais.
Você pode conferir a amostra oficial no GitHub que demonstra tudo o que acabou de aprender e de ler na documentação oficial para obter ainda mais detalhes. Fique de olho no canal do Google for Developers no YouTube para atualizações e tutoriais.
Gostaríamos de agradecer a todos os membros da equipe que contribuíram para este trabalho: T.J. Alumbaugh, Alek Andreev, Frank Ban, Jeanine Banks, Frank Barchard, Pulkit Bhuwalka, Buck Bourdon, Maxime Brénon, Chuo-Ling Chang, Lin Chen, Linkun Chen, Yu-hui Chen, Nikolai Chinaev, Clark Duvall, Rosário Fernandes, Mig Gerard, Matthias Grundmann, Ayush Gupta, Mohammadreza Heydary, Ekaterina Ignasheva, Ram Iyengar, Grant Jensen, Alex Kanaukou, Prianka Liz Kariat, Alan Kelly, Kathleen Kenealy, Ho Ko, Sachin Kotwani, Andrei Kulik, Yi-Chun Kuo, Khanh LeViet, Yang Lu, Lalit Singh Manral, Tyler Mullen, Karthik Raveendran, Raman Sarokin, Sebastian Schmidt, Kris Tonthat, Lu Wang, Zoe Wang, Tris Warkentin, Geng Yan, Tenghui Zhu, e à equipe do Gemma.