No mês passado, lançamos o Gemma 3, nossa mais recente geração de modelos abertos. Com desempenho de última geração, o Gemma 3 rapidamente se estabeleceu como um modelo líder, que pode ser executado em uma única GPU de ponta, como a NVIDIA H100, usando sua precisão BFloat16 (BF16) nativa.
Para tornar o Gemma 3 ainda mais acessível, estamos anunciando novas versões otimizadas com o treinamento com reconhecimento de quantização (QAT), que reduz drasticamente os requisitos de memória, sem perder em qualidade. Isso permite a execução de modelos poderosos, como o Gemma 3 27B, localmente em GPUs de consumidor final, como a NVIDIA RTX 3090.
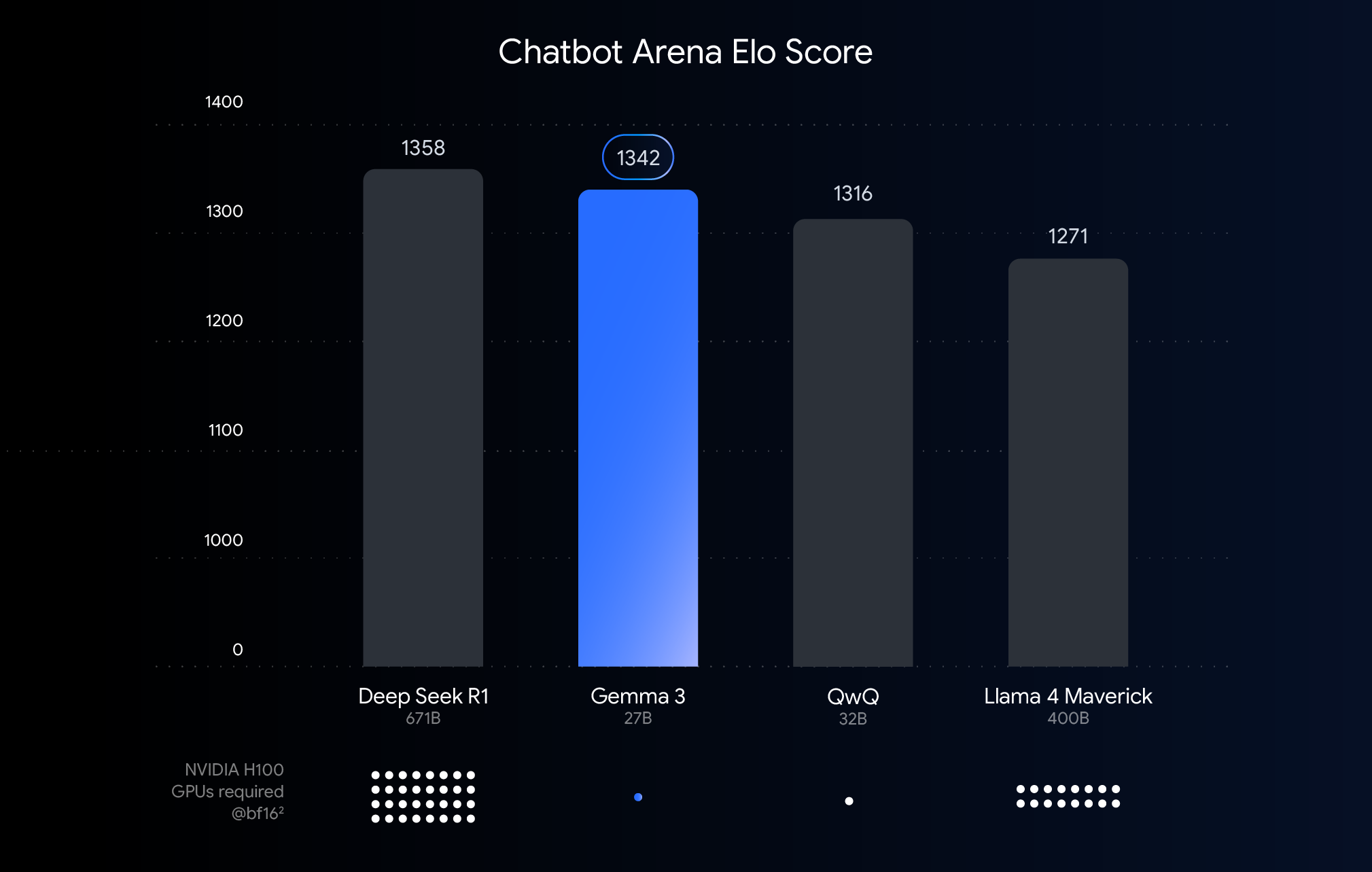
O gráfico acima mostra o desempenho (pontuação Elo) de modelos de linguagem grandes lançados recentemente. As barras mais altas significam desempenho melhor em comparações, conforme avaliação por seres humanos visualizando respostas de dois modelos anônimos, lado a lado. Abaixo de cada barra, indicamos o número estimado de GPUs NVIDIA H100 necessárias para executar esse modelo usando o tipo de dados BF16.
Por que usar o BFloat16 para esta comparação? O BF16 é um formato numérico comum usado durante a inferência de muitos modelos grandes. Isso significa que os parâmetros dos modelos são representados com 16 bits de precisão. O uso do BF16 para todos os modelos nos ajuda a fazer uma comparação direta de modelos em uma configuração de inferência comum. Com isso, podemos comparar os recursos inerentes dos próprios modelos, removendo variáveis como diferenças de hardware ou técnicas de otimização, como a quantização, que discutiremos a seguir.
É importante notar que, embora este gráfico use o BF16 para uma comparação justa, a implantação de modelos muito maiores geralmente envolve o uso de formatos de baixa precisão, como o FP8, como uma necessidade prática para reduzir os imensos requisitos de hardware (como o número de GPUs), potencialmente aceitando uma perda no desempenho para viabilidade.
Embora o desempenho máximo em hardware de ponta seja ótimo para pesquisas e implantações em nuvem, nós ouvimos os seus desejos: você quer aproveitar o poder do Gemma 3 no hardware que já possui. Estamos empenhados em tornar a IA avançada acessível, e isso significa possibilitar um desempenho eficiente nas GPUs de consumidor final encontradas em computadores, laptops e até telefones.
É aqui que a quantização entra em ação. Nos modelos de IA, a quantização reduz a precisão dos números (os parâmetros do modelo) que ela armazena e usa para calcular as respostas. Pense na quantização como a compactação de uma imagem por meio da redução do número de cores que ela usa. Em vez de usar 16 bits por número (BFloat16), podemos usar menos bits, por exemplo, 8 (int8) ou até mesmo 4 (int4).
O uso de int4 significa que cada número é representado usando apenas 4 bits, uma redução de quatro vezes no tamanho dos dados em comparação com o BF16. A quantização muitas vezes pode levar à degradação do desempenho, por isso estamos empolgados com o lançamento de modelos Gemma 3 que são robustos para a quantização. Lançamos diversas variantes quantizadas para cada modelo Gemma 3 a fim de permitir a inferência com o seu mecanismo de inferência favorito, como o Q4_0 (um formato de quantização comum) para Ollama, llama.cpp e MLX.
Como mantemos a qualidade? Usando o QAT. Em vez de apenas quantizar o modelo depois que ele está totalmente treinado, o QAT incorpora o processo de quantização durante o treinamento. O QAT simula operações de baixa precisão durante o treinamento para permitir a quantização com menos degradação posterior para modelos menores e mais rápidos, sem perder em acurácia. Fomos ainda mais fundo e aplicamos o QAT a aproximadamente 5.000 etapas usando probabilidades do ponto de verificação não quantizado como metas. Reduzimos a queda de perplexidade em 54% (usando a avaliação de perplexidade do llama.cpp) ao quantizar até Q4_0.
O impacto da quantização int4 é dramático. Veja a VRAM (memória de GPU) necessária apenas para carregar os pesos do modelo:
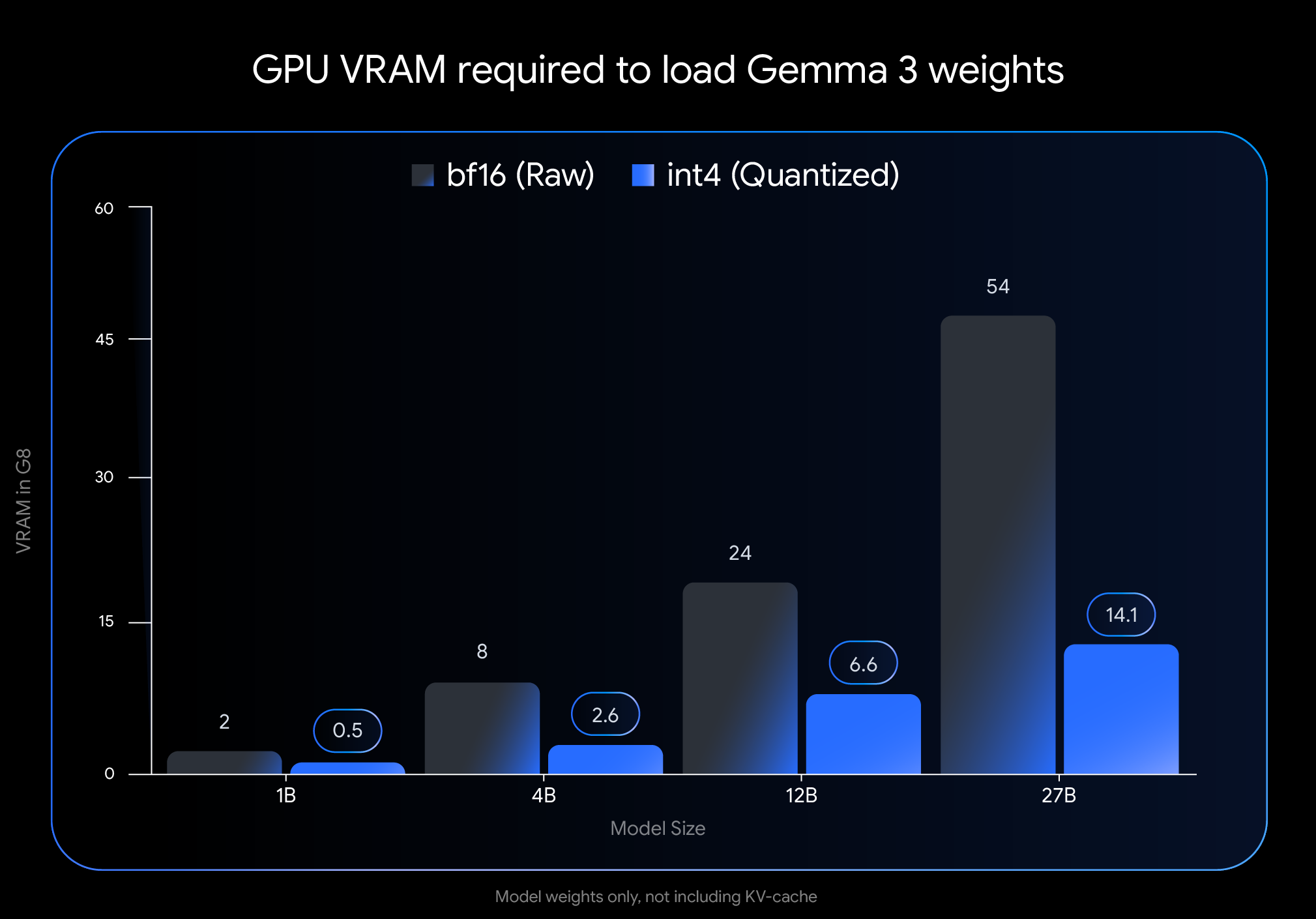
Observação: esta imagem representa apenas a VRAM necessária para carregar os pesos do modelo. A execução do modelo também requer VRAM adicional para o cache KV, que armazena informações sobre a conversa em andamento e depende da duração do contexto.
Essas reduções drásticas habilitam a capacidade de executar modelos maiores e poderosos em hardware de consumidor final amplamente disponível:
Queremos que você possa usar esses modelos facilmente dentro do seu fluxo de trabalho preferido. Nossos modelos QAT int4 e Q4_0 não quantizados oficiais estão disponíveis na Hugging Face e no Kaggle. Fizemos uma parceria com ferramentas para desenvolvedores populares que permitem experimentar facilmente os pontos de verificação quantizados baseados em QAT:
Nossos modelos com treinamento com reconhecimento de quantização (QAT) oficiais fornecem uma linha de base de alta qualidade, mas o vibrante Gemmaverse oferece muitas alternativas. Elas costumam usar a quantização pós-treinamento (PTQ, na sigla em inglês), com contribuições importantes de participantes como Bartowski Unsloth e GGML prontamente disponíveis na Hugging Face. Explorar essas opções da comunidade fornece um espectro mais amplo de compensações entre tamanho, velocidade e qualidade para atender a necessidades específicas.
Trazer o desempenho da IA de última geração para um hardware acessível é um passo fundamental na democratização do desenvolvimento da IA. Com os modelos Gemma 3, otimizados por meio do QAT, você já pode aproveitar recursos de ponta em seu próprio computador ou laptop.
Explore os modelos quantizados e comece a criar:
Mal podemos esperar para ver o que você vai criar com o Gemma 3 executado localmente!