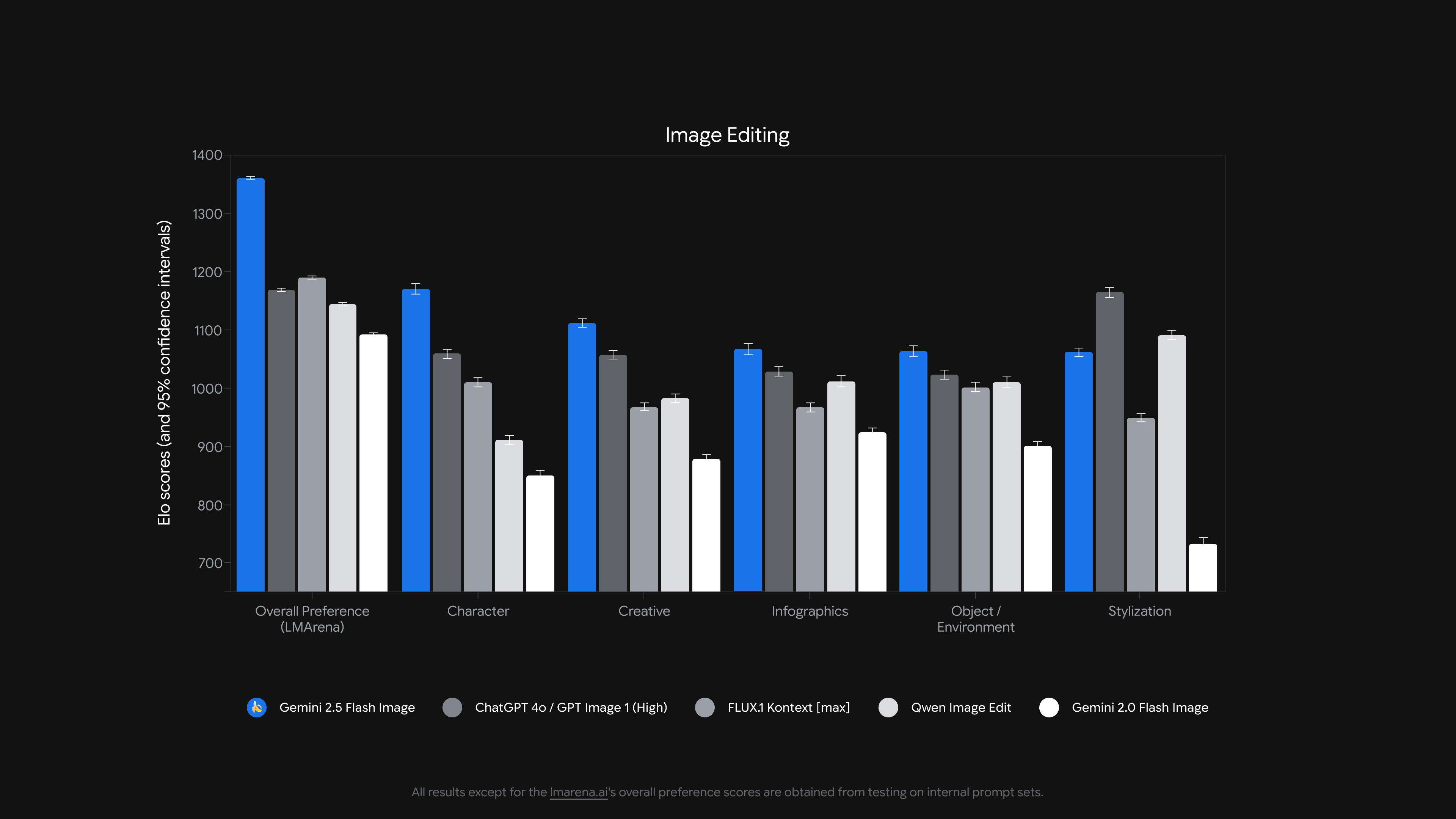
오늘, 최첨단 이미지 생성 및 편집 모델인 Gemini 2.5 Flash Image(일명 nano-banana)를 선보이게 되어 기쁩니다. 이 업데이트를 통해 여러 이미지를 하나의 이미지로 합성하고, 풍부한 스토리텔링을 위해 캐릭터 일관성을 유지하고, 자연어를 사용하여 목표로 하는 변환을 수행하며, 세상에 대한 Gemini의 지식을 사용해 이미지를 생성 및 편집할 수 있습니다.
올해 초 Gemini 2.0 Flash에서 네이티브 이미지 생성 기능을 처음 출시했을 때, 짧은 지연 시간과 비용 효율성, 사용 편의성이 마음에 들었다는 평가가 많았습니다. 하지만 더 높은 품질의 이미지와 더 강력한 크리에이티브 컨트롤이 필요하다는 의견도 있었습니다.
Gemini 2.5 Flash Image는 현재 개발자용으로는 Gemini API와 Google AI Studio를 통해, 기업용으로는 Vertex AI를 통해 제공됩니다. 이 모델의 가격은 출력 토큰 100만 개당 $30.00이며, 이미지 한 장당 출력 토큰 1,290개가 소요됩니다(즉, 이미지당 $0.039). 입력 및 출력에 대한 다른 모든 모달리티는 Gemini 2.5 Flash의 가격 책정을 따릅니다.
Gemini 2.5 Flash Image를 사용한 개발을 더 쉽게 할 수 있도록 Google AI Studio의 'build mode'를 대대적으로 업데이트했습니다(추가 업데이트도 예정). 아래 예에서는 맞춤형 AI 기반 앱으로 이 모델의 기능을 빠르게 테스트할 수 있을 뿐만 아니라, 하나의 프롬프트만으로 리믹스하거나 아이디어를 실현할 수 있습니다. 개발한 앱을 공유할 준비가 되면 Google AI Studio에서 바로 배포하거나 코드를 GitHub에 저장할 수 있습니다.
“사용자가 이미지를 업로드하고 다양한 필터를 적용할 수 있는 이미지 편집 앱을 만들어 줘"와 같은 프롬프트를 사용하거나 사전 설정된 템플릿 중 하나를 선택하여 리믹스해 보세요. 모두 무료 체험으로 제공됩니다!
이미지 생성의 근본적인 과제는 여러 프롬프트를 사용하고 편집하는 과정에서 캐릭터나 객체의 외형을 그대로 유지하는 것입니다. 이제 피사체를 그대로 보존하면서도 동일한 캐릭터를 다양한 환경에 배치하거나, 하나의 제품을 새로운 설정으로 여러 각도에서 보여주거나, 일관성 있는 브랜드 애셋을 생성할 수 있습니다.
모델의 캐릭터 일관성 기능을 입증하고자 Google AI Studio에서 템플릿 앱을 개발했습니다. 이를 사용해 손쉽게 맞춤 설정하고 원하는 스타일로 자유롭게 코드를 적용해 다양하게 실험해 볼 수 있습니다.
이 모델은 캐릭터 일관성을 넘어 시각적 템플릿을 준수하는 데도 탁월합니다. 이미 개발자들은 하나의 디자인 템플릿만으로 부동산 매물 정보 카드나 단일한 형태의 직원용 배지 또는 전체 카탈로그에 사용할 역동적인 제품 모형과 같은 분야에서 다양한 활용 방안을 모색하고 있습니다.

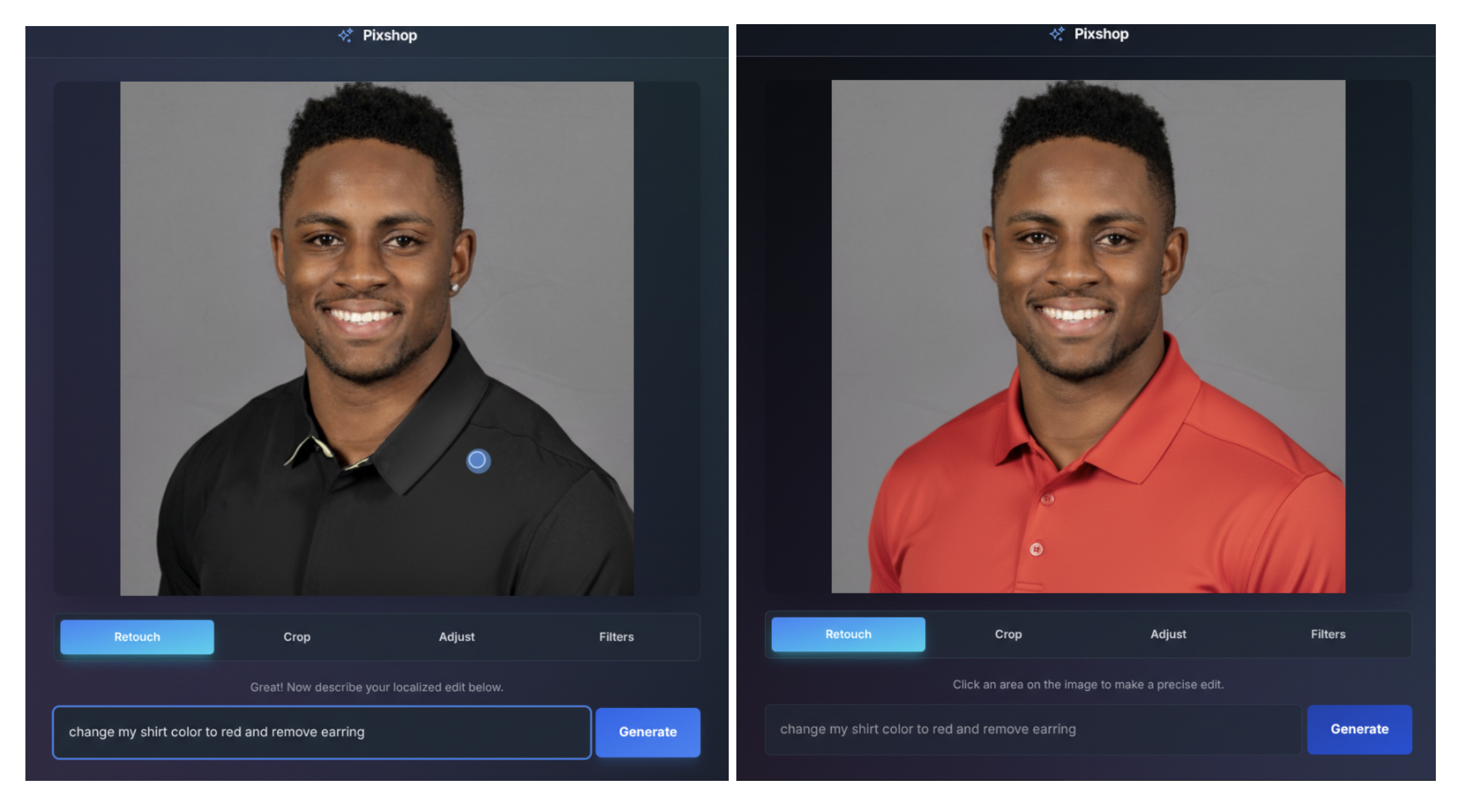
Gemini 2.5 Flash Image를 사용하면 타겟팅된 변환과 정밀한 로컬 편집을 자연어를 활용해 수행할 수 있습니다. 예를 들어, 이 모델은 간단한 프롬프트로 이미지의 배경을 흐리게 하거나, 티셔츠의 얼룩을 제거하거나, 사진에서 어떤 사람을 완전히 지우거나, 피사체의 포즈를 변경하거나, 흑백 사진에 색을 추가하는 등 상상하는 무엇이든 할 수 있습니다.
이러한 기능의 실제 사용 사례를 보여드리고자 AI Studio에서 UI와 프롬프트 기반 컨트롤을 모두 갖춘 사진 편집 템플릿 앱을 만들었습니다.
역사적으로 이미지 생성 모델은 미적인 측면에서는 뛰어났지만 현실 세계에 대한 심도 있고 의미론적인 이해는 부족했습니다. Gemini 2.5 Flash Image로 Gemini가 학습한 세상에 대한 지식을 활용하여 새로운 사용 사례를 만들어 갈 수 있습니다.
이를 입증하기 위해 Google AI Studio에서 템플릿 앱을 개발했습니다. 이것은 간단한 캔버스를 대화형 교육 튜터로 전환하는 앱으로, 손으로 그린 다이어그램을 읽고 이해하며, 현실 세계의 질문에 대한 답을 찾는 데 도움을 주고, 복잡한 편집 지시도 한 번에 수행할 수 있는 이 모델의 능력을 잘 보여줍니다.
Gemini 2.5 Flash Image는 여러 입력 이미지를 이해하고 병합할 수 있습니다. 단일 프롬프트로 여러 이미지를 합성하고, 장면에 객체를 넣고, 색 구성표 조합이나 텍스처로 실내 공간을 다시 꾸밀 수 있습니다.
다중 이미지 합성을 선보이기 위해 Google AI Studio에서 템플릿 앱을 제작했습니다. 이 앱을 통해 제품을 새로운 장면으로 끌어와서 사실적인 합성 이미지를 빠르게 새로 만들 수 있습니다.
Gemini 2.5 Flash Image로 개발을 시작하려면 개발자 문서를 확인해 보세요. 이 모델은 현재 Gemini API와 Google AI Studio를 통해 미리보기로 제공되지만 앞으로 몇 주 내에 안정화 버전으로 제공될 예정입니다. 이 글에서 집중 조명한 모든 데모 앱은 Google AI Studio에서 바이브 코딩된 것이므로, 프롬프트만으로 손쉽게 리믹스하고 맞춤 설정할 수 있습니다.
OpenRouter.ai는 저희와 파트너십을 맺고 현재 전 세계 3백만 명 이상의 개발자에게 Gemini 2.5 Flash Image를 제공합니다. 이는 현재 운영 중인 480여 개 모델 중 OpenRouter에서 이미지를 생성할 수 있는 최초의 모델입니다.
또한 생성형 미디어를 위한 선도적인 개발자 플랫폼인 fal.ai와 협력해 더욱 광범위한 개발자 커뮤니티에서 Gemini 2.5 Flash Image를 사용할 수 있도록 했습니다.
Gemini 2.5 Flash Image로 생성 또는 편집된 모든 이미지에는 보이지 않는 SynthID 디지털 워터마크가 포함되어 있으므로 AI로 생성 또는 편집된 이미지임을 쉽게 확인할 수 있습니다.
from google import genai
from PIL import Image
from io import BytesIO
client = genai.Client()
prompt = "Create a picture of my cat eating a nano-banana in a fancy restaurant under the gemini constellation"
image = Image.open('/path/to/image.png')
response = client.models.generate_content(
model="gemini-2.5-flash-image-preview",
contents=[prompt, image],
)
for part in response.candidates[0].content.parts:
if part.text is not None:
print(part.text)
elif part.inline_data is not None:
image = Image.open(BytesIO(part.inline_data.data))
image.save("generated_image.png")