지난달에 최신 세대 개방형 모델인 Gemma 3가 출시되었습니다. 최첨단 성능을 제공하는 Gemma 3는 기본 BFloat16(BF16) 정밀도를 사용하여 NVIDIA H100과 같은 단일 고성능 GPU에서 실행 가능한 선도적 모델로 빠르게 자리 잡았습니다.
Gemma 3에 대한 접근성을 높이고자, 고품질을 유지하면서 메모리 요구 사항을 획기적으로 줄인 QAT(Quantization-Aware Training)로 최적화된 새로운 버전을 발표합니다. 이를 통해 Gemma 3 27B 같은 강력한 모델을 NVIDIA RTX 3090 같은 소비자 등급 GPU에서 로컬로 실행할 수 있습니다.
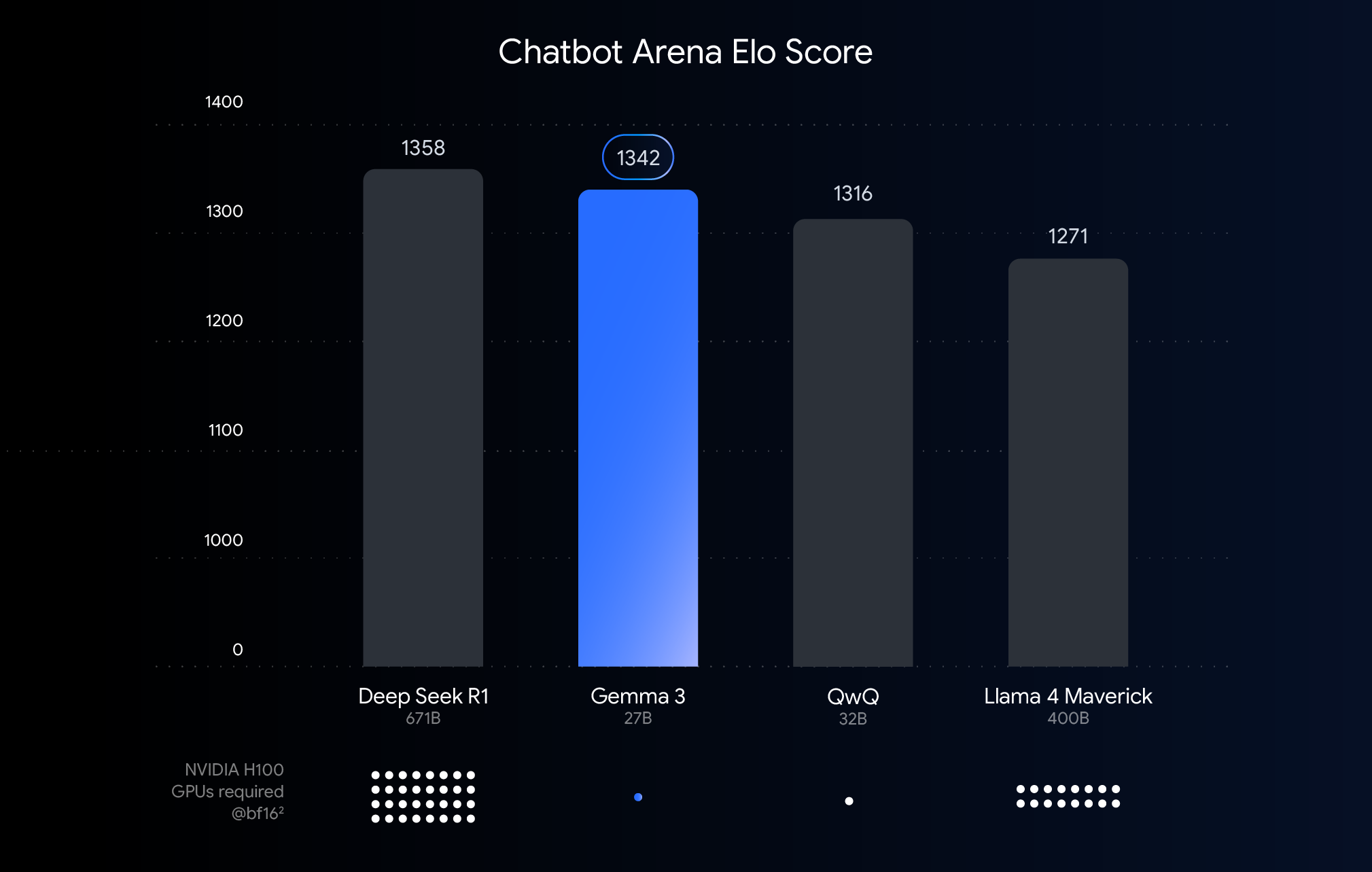
위 차트는 최근에 출시된 대형 언어 모델의 성능(엘로 점수)을 보여줍니다. 두 개의 익명 모델이 생성한 응답을 나란히 놓고 사람이 비교 평가한 결과, 막대가 높을수록 성능이 더 우수함을 의미합니다. 각 막대 아래에는 BF16 데이터 형식을 사용하여 해당 모델을 실행하는 데 필요할 것으로 예상되는 NVIDIA H100 GPU 수가 표시됩니다.
왜 이 비교에 BFloat16을 사용하는 걸까요? BF16은 많은 대형 모델을 추론하는 동안 사용되는 일반적인 숫자 형식입니다. 이는 모델 매개변수가 16비트의 정밀도로 표현된다는 의미입니다. 모든 모델에 BF16을 사용하면 공통 추론 설정에서 모델을 유사한 모델과 비교할 수 있습니다. 이를 통해 모델 자체의 고유한 기능을 비교하여 하드웨어의 차이나 최적화 기법(예: 양자화)과 같은 변수를 제거할 수 있습니다. 여기에 대해서는 다음에 설명하겠습니다.
이 차트는 공정한 비교를 위해 BF16을 사용합니다. 하지만 아주 큰 모델을 배포하려면 엄청난 하드웨어 요구 사항(예: GPU 수)을 줄이기 위해 실질적 필요에 따라 FP8 같은 저정밀 형식을 사용하는 경우가 많고, 이 과정에서 실행 가능성을 위해 성능 저하를 어느 정도 감수해야 할 수도 있음을 알아두심이 중요합니다.
최고급 하드웨어의 최고 성능은 클라우드 배포 및 연구에 적합하지만, 이미 소유하고 있는 하드웨어에서 Gemma 3의 강력한 성능을 누리고 싶다는 여러분의 뜻을 잘 알고 있습니다. 그래서 저희는 강력한 AI를 쉽게 사용할 수 있도록 만드는 데 최선을 다하고 있습니다. 이는 곧 데스크톱, 노트북, 심지어 스마트폰에 탑재된 일반 소비자 등급 GPU에서 효율적인 성능을 구현한다는 뜻입니다.
바로 이 지점에서 양자화가 등장합니다. AI 모델에서 양자화는 응답 계산을 위해 저장 및 사용하는 숫자(모델의 매개변수)의 정밀도를 낮춥니다. 양자화는 사용하는 색의 수를 줄여 이미지를 압축하는 것과 비슷합니다. 숫자당 16비트(BFloat16)를 사용하는 대신 8비트(int8)나 심지어 4비트(int4) 같이 더 적은 비트를 사용할 수 있습니다.
int4를 사용하면 4비트만 사용해 각각의 숫자가 표시되므로 BF16에 비해 데이터 크기가 4배 감소합니다. 양자화는 종종 성능 저하로 이어질 수 있으므로 양자화에 강한 Gemma 3 모델을 출시하게 되어 기쁩니다. 각 Gemma 3 모델에 대해 양자화된 대안 버전을 출시하여, Ollama, llama.cpp, MLX의 Q4_0(일반적인 양자화 형식) 같은 선호하는 추론 엔진을 사용해 추론할 수 있도록 했습니다.
어떻게 품질을 유지할 수 있을까요? 저희는 QAT를 사용합니다. 모델을 완전히 학습시킨 후에 양자화를 적용하는 대신, QAT는 학습 과정 중에 양자화 과정을 통합합니다. QAT는 학습 중에 정밀도가 낮은 작업을 시뮬레이션합니다. 이를 통해 이후 양자화 시 성능 저하가 적으면서도 더 작고 빠른 모델을 구현하고 정확도를 유지할 수 있도록 합니다. 더 자세히 설명하자면, 양자화되지 않은 검사점의 확률을 목표로 삼아 최대 5,000스텝까지 QAT를 적용했습니다. Q4_0 수준으로 낮추어 양자화할 때 퍼플렉서티 감소를 54% 줄입니다(llama.cpp 퍼플렉서티 평가를 사용).
int4 양자화의 효과는 매우 큽니다. 모델 가중치를 로드하는 데 필요한 VRAM(GPU 메모리) 용량을 살펴보세요.
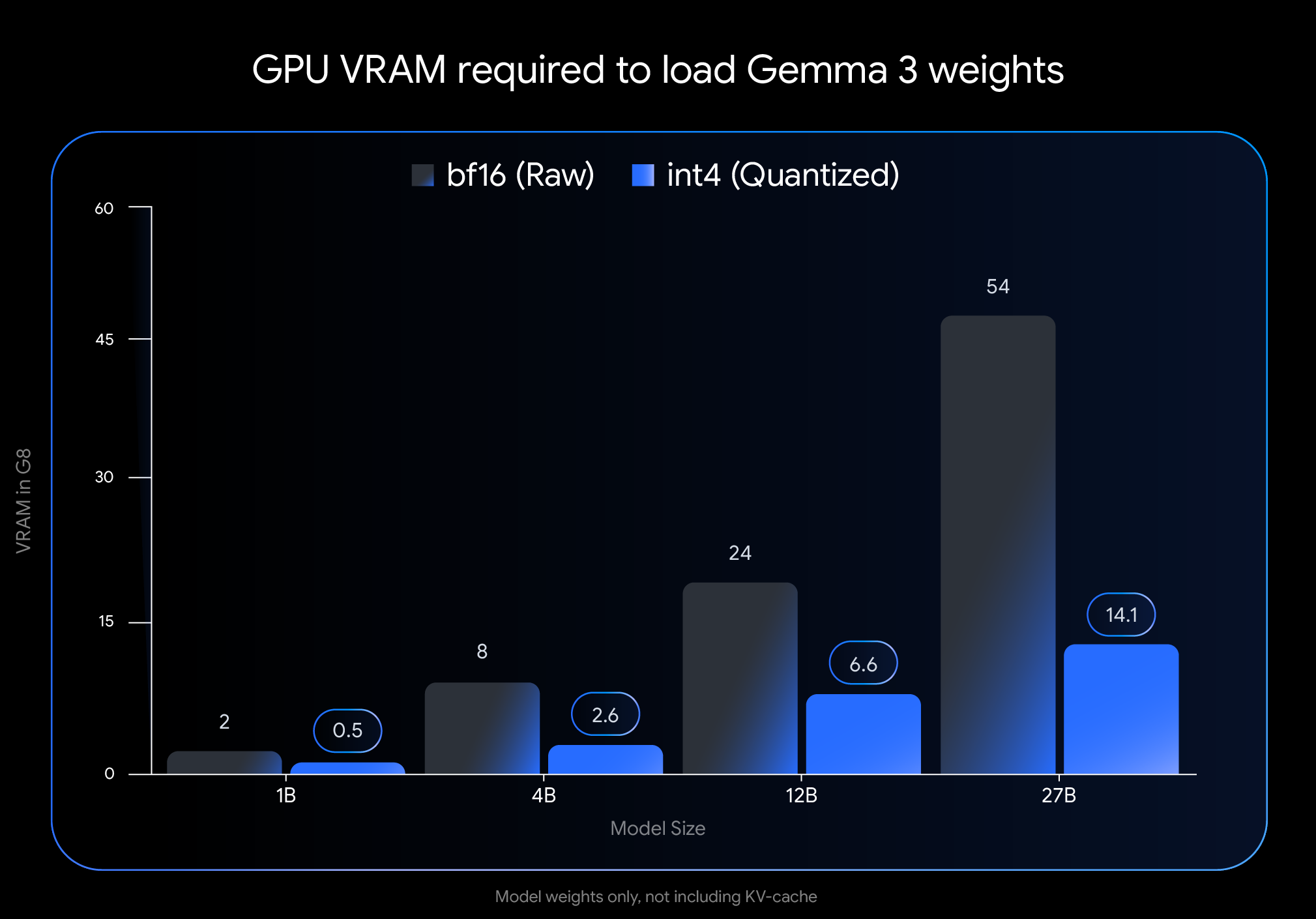
참고: 이 그림은 모델 가중치를 로드하는 데 필요한 VRAM 용량만 나타냅니다. 모델을 실행하려면 진행 중인 대화에 대한 정보를 저장하고 컨텍스트 길이에 따라 달라지는 KV 캐시에 대한 추가 VRAM도 필요합니다.
이처럼 획기적인 수준의 감소 덕분에 널리 사용 가능한 소비자 하드웨어에서 더 크고 강력한 모델을 실행할 수 있게 됩니다.
선호하는 워크플로 내에서 이러한 모델을 쉽게 사용하실 수 있도록 만들고자 노력했습니다. Google의 공식 int4 및 Q4_0 비양자화 QAT 모델은 Hugging Face와 Kaggle에서 이용 가능합니다. Google은 QAT 기반의 양자화 검사점을 원활하게 사용해 볼 수 있도록 인기 있는 개발자 도구 공급자와 협력하고 있습니다.
Google의 공식 QAT(Quantization Aware Trained) 모델은 품질 기준선이 높지만, 활기찬 Gemmaverse에서 많은 대안을 제공합니다. 이 대안 모델들은 주로 PTQ(Post-Training Quantization)를 사용하고, Bartowski, Unsloth, GGML과 같은 구성원들이 Hugging Face에 공개한 중요한 기능들도 쉽게 사용할 수 있습니다. 이러한 커뮤니티 옵션을 살펴보면 특정 요구 사항에 맞춰 크기, 속도, 품질 간 다양한 절충점을 선택할 수 있는 폭넓은 가능성이 제공됩니다.
접근 가능한 하드웨어에 최첨단 AI 성능을 도입하는 것은 AI 개발의 대중화에 있어 핵심적인 단계입니다. QAT를 통해 최적화된 Gemma 3 모델을 사용하면 이제 자신의 데스크톱이나 노트북에서 최첨단 기능을 활용할 수 있습니다.
양자화된 모델을 탐색하고 개발을 시작해 보세요.
Gemma 3를 로컬에서 실행하며 무엇을 개발하실지 정말 기대됩니다!