
이 블로그를 읽고 있다면 아마 여러분은 사용자 설정 머신러닝(ML) 모델을 만드는 데 관심이 있을 겁니다. 필자는 최근에 직접 이 프로세스를 진행하면서 MediaPipe로 사용자 설정 객체 감지 웹 앱 만들기 Codelab을 이용해 사용자 설정 개 감별기를 만들었습니다. 새로운 코딩 작업과 마찬가지로, 그 과정에서 무엇을 하고 있는지 파악하기 위해 약간의 시행착오도 겪었습니다. 여러분이 '시행착오'에서 '착오'를 최소화할 수 있도록, 필자의 모델 학습 경험에서 깨달은 5가지 요점을 알려드리겠습니다.
학습용 데이터 준비는 사용자 설정하는 모델 유형에 따라 달라집니다. 일반적으로 데이터를 소싱하는 단계와 데이터에 주석을 다는 단계가 있습니다.
사용 사례를 가장 잘 나타내는 충분한 데이터 요소를 찾는 일이 어려울 수 있습니다. 우선, 데이터에 포함될 이미지나 텍스트를 사용할 권리가 있는지 확인해야 합니다. 학습 전에 데이터에 대한 라이선스를 확인하세요. 이 문제를 해결하는 한 가지 방법은 자체 데이터를 사용하는 것입니다. 필자에겐 반려견 사진이 수백 장 있었기에 고민할 것 없이 객체 감지기에 쓸 데이터로 직접 찍은 반려견 사진을 선택했습니다. Kaggle에서 기존 데이터 세트를 찾아볼 수도 있습니다. Kaggle에는 다양한 사용 사례에 맞는 옵션이 많습니다. 운이 좋으면 필요에 맞는 기존 데이터 세트를 찾을 수 있으며 이미 주석이 달려 있을 수도 있습니다!
MediaPipe Model Maker는 각 입력에 주석이 나열된 해당 XML 파일이 있는 데이터를 허용합니다. 예를 들면 다음과 같습니다.
주석 작성을 돕는 몇 가지 소프트웨어 프로그램이 있습니다. 주석은 이미지의 특정 영역을 강조표시할 때 특히 유용합니다. 일부 소프트웨어 프로그램은 협업을 지원하도록 설계되었습니다. 직관적인 UI와 주석 작성기 지침를 통해 다른 사람의 도움을 요청할 수 있습니다. 흔히 사용하는 오픈소스 옵션은 Label Studio입니다. 필자도 이미지에 주석을 달 때 이 프로그램을 사용했습니다.
이 단계는 시간이 오래 걸릴 것임을 각오하세요. 그럼에도 여러분의 예상보다 더 오래 걸릴 수 있습니다.
필자와 같은 분이라면 처음 만드는 사용자 설정 모델을 위해 멋지고 대단한 아이디어를 계획하고 계실 겁니다. 필자의 첫 번째 모델에 영감을 준 건 바로 반려견 벤이었습니다. 벤은 지역의 골든 리트리버 구조 센터에서 데려왔지만 DNA 검사 결과 골든 리트리버와는 전혀 관련이 없는 품종이었습니다! 그때 처음 떠올린 아이디어는 개가 '골든 리트리버'인지 '골든 리트리버가 아닌지' 알 수 있는 솔루션인 골든 리트리버 감별기를 만들어보자는 것이었습니다. 모델이 벤을 어떤 개로 판단하는지 보는 것이 재미있겠다고 생각했지만, 다른 개들에게도 모델을 실행할 수 있도록 개인적으로 소장한 것보다 훨씬 더 많은 개 이미지를 소싱해야 한다는 걸 이내 깨달았습니다. 모든 색조의 골든 리트리버를 정확하게 식별할 수 있는지 확인해야 했습니다. 이 문제를 해결하느라 여러 시간 씨름한 끝에, 단순화해야 한다는 점을 깨달았습니다. 그때 일단은 세 마리의 개를 위한 솔루션을 개발해 보자고 결심했습니다. 선택할 수 있는 사진이 많아서 개들을 가장 상세하게 보여주는 사진을 골랐습니다. 필자가 그 아이디어를 포기하지 않았기에 훨씬 더 성공적인 솔루션을 개발할 수 있었고 골든 리트리버 모델에 대한 훌륭한 개념 증명이 되었습니다.
여러분의 첫 사용자 설정 모델을 단순화하는 몇 가지 방법을 알려드립니다.

따라서 첫 번째 ML 학습 경험에 있어서는 첫째도, 둘째도, 셋째도 단순화라는 것을 잊지 마세요.
단순화가 가장 중요합니다.
단순화가 가장 중요합니다.
첫 학습에서 모델이 곧바로 올바른 결과를 내놓을 것이라 여러분에게 자신 있게 말해 주고 싶지만, 아마도 그런 일은 일어나지 않을 것입니다. 데이터 샘플과 주석을 선택하는 데 시간을 할애하면 성공률이 확실히 향상되겠지만 모델의 동작 방식을 변경할 수 있는 요소가 너무 많습니다. 원하는 정확도에 도달하려면 다른 모델 아키텍처로 시작해야 할 수도 있습니다. 또는 학습 및 검증 데이터의 다른 분할을 시도할 수도 있고, 데이터 세트에 샘플을 더 추가해야 할 수도 있습니다. 다행히 MediaPipe Model Maker를 사용한 전이 학습은 일반적으로 몇 분 정도만 걸리므로 새 반복을 상당히 빠르게 진행할 수 있습니다.
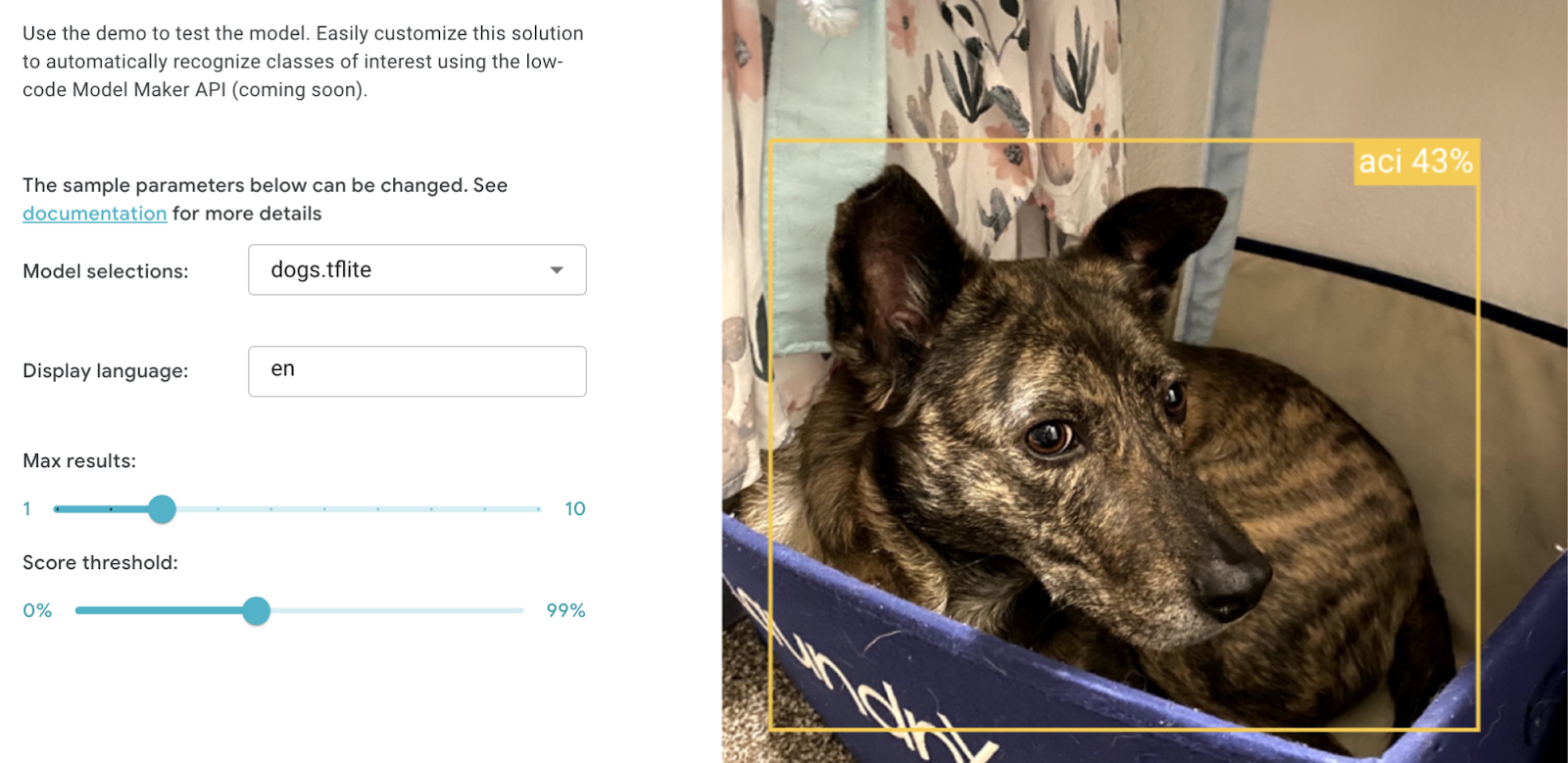
모델 학습을 마치면 아마 여러분은 설렘에 가득 차서 당장 앱에 모델을 추가하고 싶어질 겁니다. 하지만 몇 가지 이유로 MediaPipe Studio에서 모델을 먼저 시험해 보시기 바랍니다.
MediaPipe Studio를 사용하여 다양한 이미지에서 각기 다른 점수 기준점을 빠르게 시험하여 앱에서 어떤 기준점을 사용해야 하는지 결정할 수 있었습니다. 이 성능의 요인으로 자체 웹 앱도 제거했습니다.
품질 데이터 소싱과 사용 사례 간소화, 학습, 프로토타입 제작 후, 올바른 결과를 얻기 위해 이러한 사이클을 반복해야 할 수도 있습니다. 반복이 필요한 경우에는 프로세스에서 변경할 한 부분만 선택하여 작게 변경하세요. 필자의 경우, 동일한 파란색 소파에 반려견을 올려놓고 찍은 사진이 많았습니다. 모델이 종종 경계 상자 내부에 있어서 이 소파에서 픽업을 시작한 경우, 소파 위에 있지 않은 개의 이미지를 분류하는 방법에 영향을 미칠 수 있습니다. 소파 사진을 전부 버리기보다는 두어 개만 삭제하고 개가 소파 위에 있지 않은 사진을 한 마리당 10장 정도 더 추가했습니다. 그러자 결과가 현저히 개선되었습니다. 당장에 큰 변화를 시도하면 문제를 해결하기보다는 새로운 문제가 생길 수 있습니다.
자 이제, 이러한 팁을 염두에 두고 자신만의 ML 솔루션을 사용자 설정할 때입니다! MediaPipe 작업에서 사용할 이미지 분류, 동작 인식, 텍스트 분류 또는 객체 감지 모델을 사용자 설정할 수 있습니다.
여러분의 첫 모델을 학습시키면서 배운 점을 공유하고 싶다면 LinkedIn에 이 블로그 게시물에 대한 링크와 함께 세부 정보를 게시한 다음 저를 태그로 지정해 주세요. 여러분이 무엇을 배우고 만들지 무척 기대됩니다!