
このブログを読んでいる皆さんは、カスタム機械学習(ML)モデルの作成に興味をお持ちの方でしょう。私自身も最近、Codelab を参考にカスタム犬検出ツールを作成したり、MediaPipe でカスタム オブジェクト検出ウェブアプリを作成したりしました。新しいコーディング作業も同じですが、自分が何を行っているのかを把握するために、多少の試行錯誤が必要になりました。ここでは、試行錯誤の「誤」の部分を最小限に抑えていただけるように、モデルのトレーニングを実際に行った経験をもとに、5 つのポイントを紹介します。
準備するトレーニング用データは、カスタマイズするモデルの種類によって異なりますが、一般的には、データを調達するステップと、データに注釈を付けるステップがあります。
ユースケースに最適なデータポイントを見つけるのは難しい場合があります。その 1 つは、データに含まれる画像やテキストの使用権を確認しなければならないことです。トレーニングの前に、データのライセンスを確認してください。これを解決する方法の 1 つは、独自のデータを使うことです。私はたまたま数百枚の犬の写真を持っていたので、それを物体検出ツールに活用しました。Kaggle で既存のデータセットを探すこともできます。Kaggle には非常に多くの選択肢があり、幅広いユースケースがカバーされています。運が良ければ、ニーズに一致し、すでに注釈が付いている既存のデータセットが見つかるかもしれません!
MediaPipe Model Maker に渡すデータについては、それぞれの入力に対応する XML ファイルを作成し、そこに注釈のリストを含めます。次に例を示します。
注釈を付ける際には、いくつかのソフトウェア プログラムを活用できます。特に、画像の特定の部分を強調しなければならない場合には、そういったプログラムが役立ちます。複数の人が共同で作業できるソフトウェア プログラムもあります。操作者にとって直感的な UI と手順を備えているので、他の人の助けを借りて作業を進めることができます。よく使われるオープンソースのソフトウェアの 1 つは Label Studio です。私はこれで画像に注釈を付けました。
このステップには長い時間がかかると覚悟しておく必要がありますが、予想よりも時間がかかることに注意してください。
皆さんが私のような人なら、最初のカスタムモデルを作成するにあたって、驚くほどすばらしいアイデアを計画するでしょう。私の最初のモデルのインスピレーションとなったのは、愛犬のベンでした。ベンは地元のゴールデン レトリーバー レスキューから引き取ったのですが、DNA 検査をしたところ、0% のゴールデン レトリーバーであることが判明したのです!私の最初のアイデアは、犬が「ゴールデン レトリーバーである」か「ゴールデン レトリーバーでない」かを知ることができるゴールデン レトリーバー検出ツールを作ることでした。モデルがベンをどう判断するかを見てみたいと思いましたが、他の犬に対してもモデルを実行できるようにするには、手元にあるものよりもはるかに多くの犬の画像を調達しなければならないことに、すぐに気づきました。さらに、あらゆる色のゴールデン レトリーバーを正確に識別できるようにする必要もあります。この作業に何時間も費やした後、シンプルにする必要があることに気づきました。そこで、私の 3 匹の犬だけのためのソリューションを作ってみることにしました。写真はたくさんあったので、犬の詳細がよくわかるものを選びました。このソリューションははるかにうまくいきました。このアイデアは捨てるべきではないと思っているので、ゴールデン レトリーバー モデルのすばらしい概念実証となっています。
最初のカスタムモデルをシンプルにするいくつかの方法を紹介します。

したがって、初めて ML をトレーニングする場合は、徹底的にシンプルにすることを心掛けましょう。
シンプルにすることです。
シンプルにすることです。
最初のトレーニングでモデルから正しい結果が得られるはずです、と自信を持って言いたいところですが、おそらくそうはならないでしょう。データ サンプルの選択と注釈付けに時間をかければ、間違いなく成功率は向上しますが、モデルの動作が変わる要因はたくさんあります。希望する精度に到達するためには、別のモデル アーキテクチャから始める必要があるかもしれません。または、トレーニング データと検証データの分割方法を変えることもできます。データセットにサンプルを追加する必要もあるかもしれません。幸いなことに、MediaPipe Model Maker の転移学習は通常数分で終わるため、かなり短時間で繰り返すことができます。
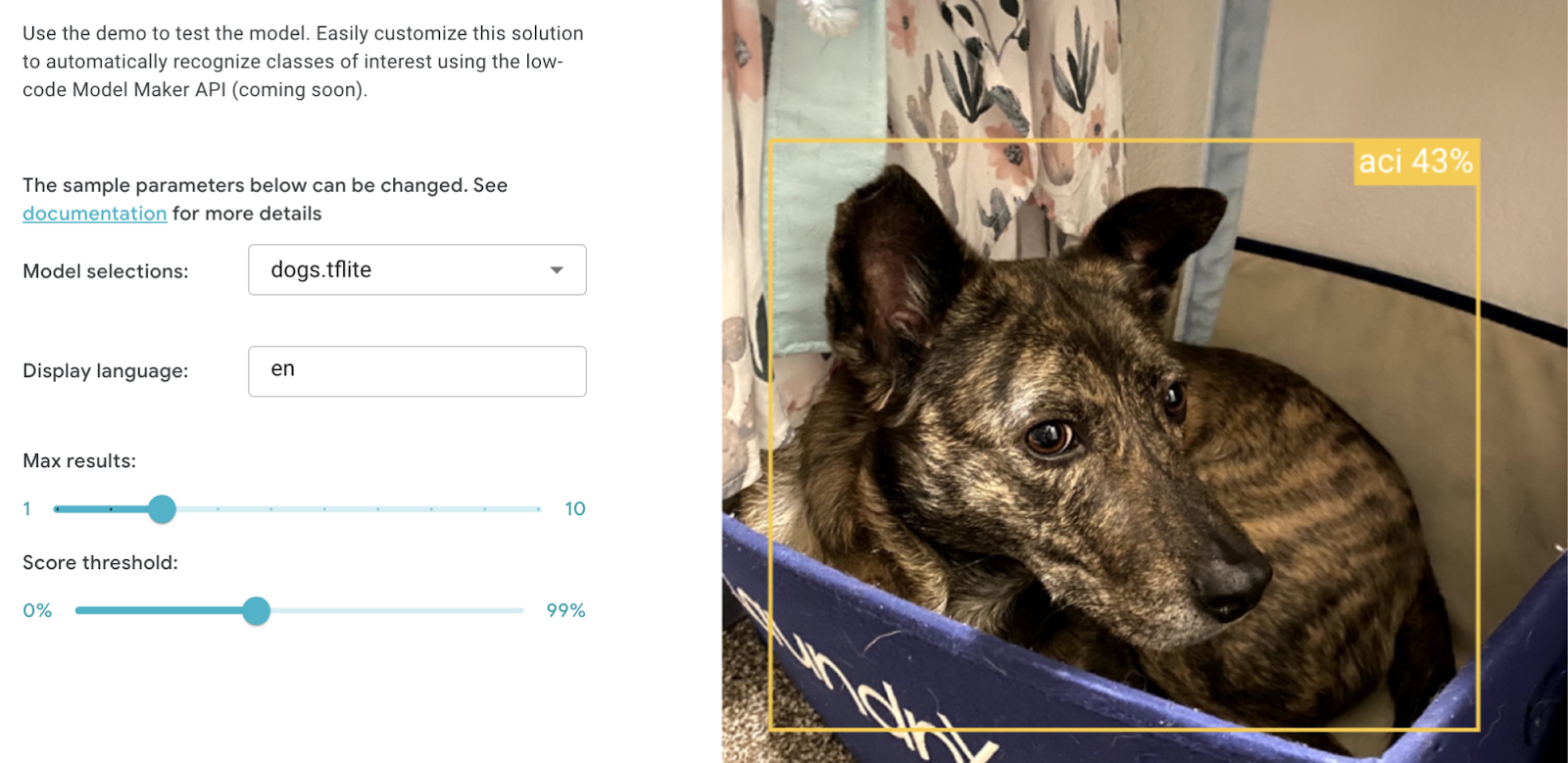
モデルのトレーニングが終わると、アプリに追加したくてたまらなくなるはずです。しかしまずは、MediaPipe Studio でモデルを試すことをお勧めします。理由は次のとおりです。
MediaPipe Studio を使ったことで、さまざまな画像でさまざまなスコアのしきい値をすばやく試し、アプリで使用するしきい値を決定することができました。また、ウェブアプリがパフォーマンスに影響する可能性を排除することもできました。
質の高いデータを調達し、ユースケースをシンプルにして、トレーニングとプロトタイピングを行っても、このサイクルを繰り返さなければ適切な結果が得られないことがあります。その場合は、プロセスの一部だけに小さな変更を加えるようにしましょう。私の場合、多くの犬の写真を同じ青いソファで撮影していました。このソファが境界ボックスの中にあることが多いため、モデルがソファを認識してしまい、ソファにいない犬の画像の分類に影響してしまう可能性がありました。ソファの写真をすべて捨てるのではなく、一部だけを削除し、ソファにいない犬の写真をそれぞれ約 10 枚ほど追加したところ、結果が大幅に改善しました。安易に大きな変更を加えると、問題を解決するのではなく、新しい問題を引き起こすことになりかねません。
以上のヒントを念頭に置いて、独自の ML ソリューションをカスタマイズしてみましょう!MediaPipe Tasks では、使用する画像分類、ジェスチャ認識、テキスト分類、オブジェクト検出モデルをカスタマイズできます。
初めてモデルをトレーニングして学んだ教訓を共有したい方は、LinkedIn に詳しく投稿してください。このブログ投稿へのリンクと、私のタグもお忘れなく。皆さんが学んだことや構築したものを見るのが待ちきれません!