

極低温冷蔵庫の底で、絶対零度をわずかに超える温度まで冷却された超伝導チップの量子状態を操作することは、極めて困難です。そして計画は必ずしも予定どおりに進行するとは限りません。エラーが発生します。しかも大量に。大量のランダムな出力ビットになるであろうものから信頼性の高い計算を抽出するには、高度な戦略が必要です。エラーが圧倒的に多くない場合にのみ、成功の可能性があります。
本日、Google Quantum AI は、エラーが圧倒的に多くない量子チップの構造を発表しました。これは、本質的には単一の、最近傍結合された物理的量子ビットの正方形パッチである表面コードを利用するものです。この量子ビットは一緒に動作して、信頼性のより高い論理量子ビットを形成します。正方形パッチが大きくなるにつれ、論理量子ビットは信頼性を増してゆくはずで、これがまさに私たちが実証したこと、つまり論理量子ビットを持つチップは、パッチサイズが大きくなるたびに信頼性が 2 倍増すということです。
エラー訂正がなぜ必要なのか?量子エラーとは何で、それをどのように修正できるのか?
ここでは答えを簡単に説明します。簡単な概要以上のものが必要な場合は、Coursera で無料で利用できる実践的な量子エラー訂正コースに直接アクセスしてください。そこには理解を深めるための一連の動画とエ演習が用意されています。Coursera のコンテンツ最高責任者である Marni Baker Stein 氏は次のように述べています。「この新しいコースは、複雑なドメインへの扉を開き、世界中の何百万人もの学習者に量子エラー訂正を利用可能にするだけでなく、具体的なものにします。Google Quantum AI のような業界のパイオニアとのコラボレーションは、私たちが未来に向けてさらなる一歩を踏み出したことを意味します。そこでは、量子コンピューティングのパワーを活用するための知見が重要になります」

古典的なエラーから見ていきましょう。ここにビットがあります。0 になるべきなのですが、宇宙線が当たって 1 になってしまいました。これがビットフリップ エラーであり、古典的コンピュータでは、唯一のエラータイプになります。それに対して量子チップはビットではなく、非常に冷たいマルチレベル量子システムで構成されており、明確に定義された離散的基底と励起状態を有しています。これらの状態は、| 0>、| 1>、|> 2 などと書きます。宇宙線が | 0> であるはずの量子ビットに当たると、多くの状態の重ね合わせ a|0> + b|1> + c|2> + ... が生成されます。デバイスの慎重なエンジニアリングにより、量子ビットは、最もエネルギッシュな影響を除くすべての影響に対して堅牢になり、宇宙線が当てられた際にも出力を破棄して、結果を計算することができるようになります。
コンピューティングでは、できる限り状態 |0> と |1> のみを使用するようにしていますが、制御と測定の誤差によって、時折やむを得ずリークエラーとして知られる |2+> 状態になってしまいます。量子ビットをリセットするとこのエラーは消えますが、その量子ビット上のすべてのデータも消えてしまうため、データ量子ビットからより高い状態を、リセットされようとしている量子ビットに移動する特別なゲートが用意されています。これにより、コンピュータに |2+> 状態が蓄積されるのを防ぎます。
加えて、量子データはあまり長く続かないという問題があります。量子ビットは緩和する傾向があります。励起状態を使用して |1> を表す場合、しばらくすると |0> に緩和します。また、私たちは、a|0> + b|1> のような重ね合わせを保存できるようにしたいと考えています。そして、その「プラス」も自然発生的に「マイナス」、つまりフェーズフリップ エラーになることがあります。量子ビットがデータを失う原因の幾つかを、総称してデコヒーレンスと呼びます。一般的に、デコヒーレンスは私たちが望む状態とはまったく異なる状態を作り出すことがありますが、幸いなことに、この違いはビットフリップとフェーズフリップの混合に分散することができます。簡潔にするため、それらを X エラー、および Z エラーと呼びます。
まずは、私たちの量子チップの写真を見てみましょう。
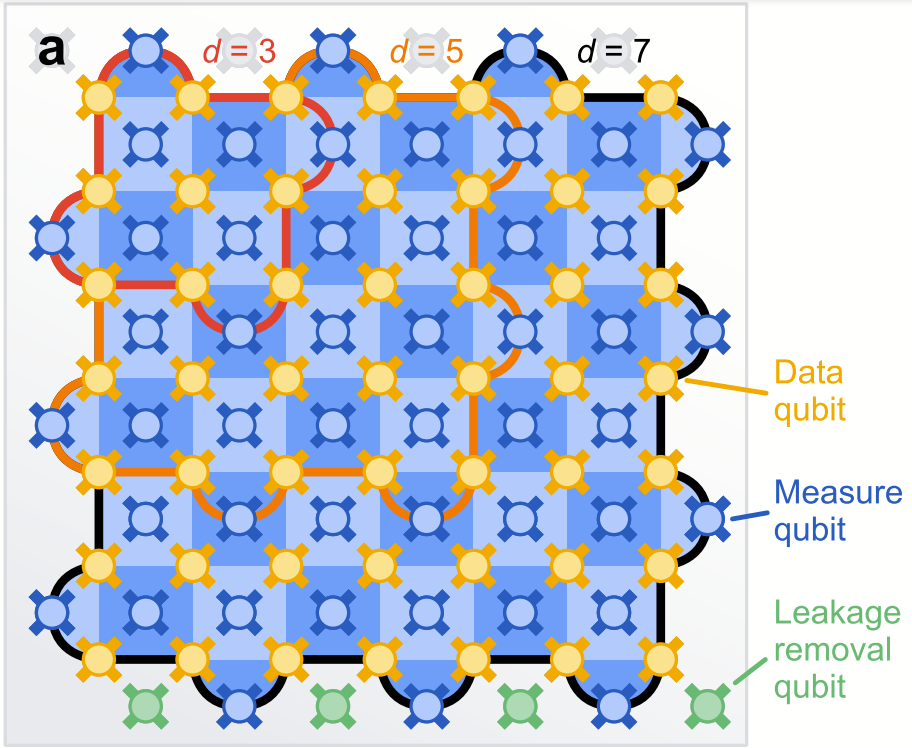
これは、最近傍相互作用のみを持つ量子ビットの 2D 配列です。データ量子ビットは、貴重な量子状態を保存します。測定量子ビットは、X および Z エラーの検出に用いられます。これを理解するには、薄い青色の各領域が、接触するデータ量子ビット上の Z エラーを検出し、濃い青色の各領域が、X エラーを検出すると考えればよいでしょう。データ量子ビットの Z エラーが、隣接する薄い青色の領域を活性化し、位置を特定するので、ソフトウェアでその存在を補正することができます。X および Z エラーの密度が十分に低ければ、点灯している領域のパターンがこれらのエラーを見つけて補正するための明確な情報を提供してくれます。
測定量子ビットにエラーが発生した場合、誤って活性化された領域が表示される可能性があります。対策として、エラー検索をできるだけ頻繁に繰り返し、次回のチェックが実行されるときにエラーが解決される可能性を高めます。これによって測定エラーの識別可能なシグネチャが作成され、それらもソフトウェアで処理することが可能です。これは進行中の研究分野であり、より高度なアルゴリズムを考案して、量子コンピュータのペースを維持しながら測定量子ビットの出力を処理し、エラーの位置とタイプをより正確に識別することを目指しています。
上記で説明したのは、量子エラー訂正と、それが量子コンピューティングの進歩において果たす重要な役割のほんの一部です。基本中の基本から、量子の状態や回路、今日使用されている最新のエラー訂正ツールまで、ステップごとの詳しい説明やラボについては、Coursera の実践的な量子エラー訂正コースにアクセスしてください。
あなたが量子問題に取り組みたいと常々思っているソフトウェアエンジニアなら、コース修了後に量子 AI オープンソース ツールに進みましょう。そこでは Cirq、Stim、Crumble などのオープンソース ソフトウェア構築を通して、量子回路のシミュレーションやエラー修正技術の開発を行っています。量子アルゴリズムの設計や、実用的な量子コンピューティングの実現を可能にするツールの開発に貢献できる方法を学んでください。
ここでは、理論的コンピュータ サイエンス、ソフトウェア工学、量子物理学を組み合わせたエキサイティングな研究領域を紹介します。
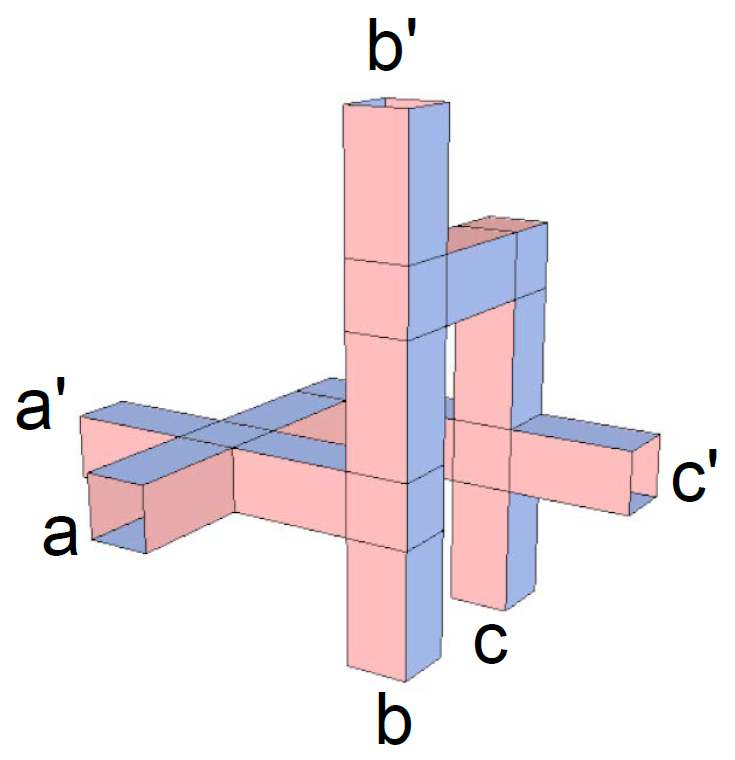
このグループに参加して、TQEC プロジェクトにアクセスし、このイメージがなぜ、スケーラブルなフォールト トレラント量子コンピューティングの画像なのか、3 つの論理量子ビット abc が、制御 NOT ゲートを 3 つ経て出力 a'b'c' を生成するのかを学びましょう。