
JAX を使用して言語モデルをゼロから構築するために必要なことを知りたいという方は、ぜひこの投稿をお読みください。先日、Cloud Next 2025 でこのトピックに関するワークショップを開催し、好意的なフィードバックをいただきました。そこで、参加できなかった方々のためにガイドを作成することにしました。
この記事とコード例では、GPT-2 モデルを構築して事前トレーニングし、JAX で Google TPU の機能を簡単に活用できるようにする方法をご紹介します。Colab または Kaggle で TPU を使用し、プロジェクト全体を無料で実行できます。完全なノートブックについてはこちらをご覧ください。
これは実践的なチュートリアルのため、一般的な機械学習の概念に精通している方を前提としています。JAX が初めての方には、PyTorch デベロッパー向け JAX 基礎ガイドから始めることをおすすめします。
まず、使用するツールを簡単に確認しましょう。
モデルの構築を開始する前に、JAX エコシステムについて簡単に説明します。JAX エコシステムは、モジュール式のアプローチを採用しています。JAX コアは数値処理のコア機能を提供し、JAX の上に構築された豊富なライブラリのコレクションはアプリケーション固有の多様なニーズに対応します。ライブラリの例としては、ニューラル ネットワークを構築するための Flax、チェックポイントとモデルの永続化のための Orbax、最適化のための Optax などがあります(この記事ではこの 3 つすべてを使用します)。自動微分、ベクトル化、JIT コンパイルなどの組み込み関数変換をサポートする JAX は、優れたパフォーマンスと API の使いやすさという観点からも、大規模言語モデルのトレーニングに最適です。
OpenAI は GPT2 のモデルコードと重みを公開しており、これらは良い参考資料となっています。また、nanoGPT など、GPT2 モデルを複製する取り組みもコミュニティで多く行われています。以下は、GPT2 のモデル アーキテクチャの概略図です。
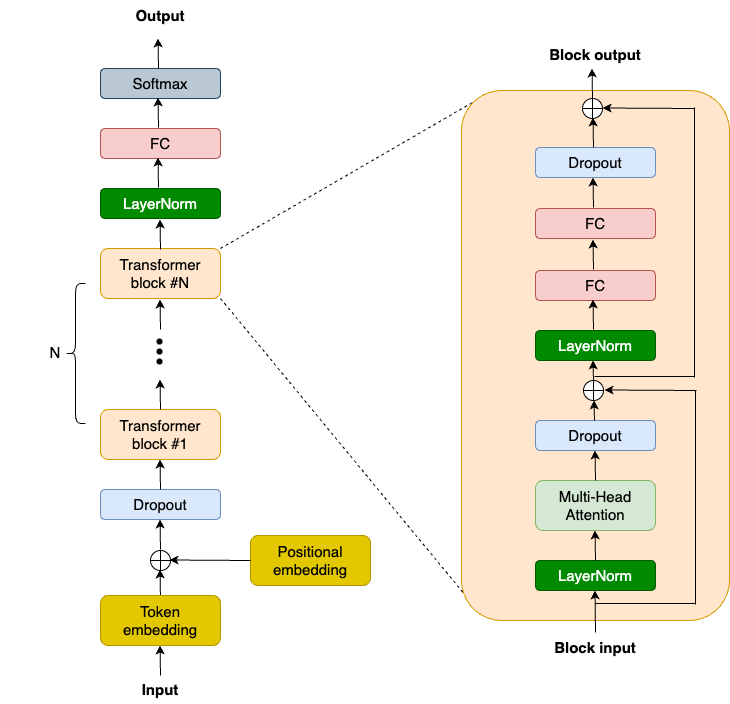
NNX(新しい Flax インターフェース)を使用して、GPT2 モデルを構築します。簡潔にするために、現代の大規模言語モデルの鍵であるトランスフォーマー ブロックに焦点を当てます。トランスフォーマー ブロックは、任意のシーケンスで長距離依存関係をキャプチャし、それについての豊富な文脈理解を構築します。GPT2 のトランスフォーマー ブロックは、2 つの LayerNorm 層、1 つの Multi-Head Attention(MHA)層、2 つのドロップアウト層、2 つの線形投影層、および 2 つの残差接続で構成されています。まず、TransformerBlock クラスの __init__ 関数でこれらの層を定義します。
class TransformerBlock(nnx.Module):
def __init__(
self,
embed_dim: int,
num_heads: int,
ff_dim: int,
dropout_rate: float,
rngs: nnx.Rngs,
):
self.layer_norm1 = nnx.LayerNorm(
epsilon=1e-6, num_features=embed_dim, rngs=rngs
)
self.mha = nnx.MultiHeadAttention(
num_heads=num_heads, in_features=embed_dim, rngs=rngs
)
self.dropout1 = nnx.Dropout(rate=dropout_rate)
self.layer_norm2 = nnx.LayerNorm(
epsilon=1e-6, num_features=embed_dim, rngs=rngs
)
self.linear1 = nnx.Linear(
in_features=embed_dim, out_features=ff_dim, rngs=rngs
)
self.linear2 = nnx.Linear(
in_features=ff_dim, out_features=embed_dim, rngs=rngs
)
self.dropout2 = nnx.Dropout(rate=dropout_rate)次に、__ call __ 関数でこれらの層を組み立てます。
class TransformerBlock(nnx.Module):
def __call__(self, inputs, training: bool = False):
input_shape = inputs.shape
bs, seq_len, emb_sz = input_shape
attention_output = self.mha(
inputs_q=self.layer_norm1(inputs),
mask=causal_attention_mask(seq_len),
decode=False,
)
x = inputs + self.dropout1(
attention_output, deterministic=not training
)
# MLP
mlp_output = self.linear1(self.layer_norm2(x))
mlp_output = nnx.gelu(mlp_output)
mlp_output = self.linear2(mlp_output)
mlp_output = self.dropout2(
mlp_output, deterministic=not training
)
return x + mlp_outputこのコードは、PyTorch や TensorFlow などの他の ML フレームワークを使用して言語モデルをトレーニングしたことがある方にはなじみがあると思います。しかし、JAX の素晴らしい点の一つは、SPMD(単一プログラム複数データ)を介してコードを自動的に並列実行するという驚くべき機能を備えていることです。この機能は、複数のアクセラレータ(複数の TPU コア)でコードを実行するために必要です。その仕組みを見てみましょう。
SPMD を実行するには、まず TPU を使用していることを確認する必要があります。Colab または Kaggle を使用している場合は、TPU ランタイムを選択します(Cloud TPU VM も使用できます)。
import jax
jax.devices()
# Free-tier Colab offers TPU v2:
# [TpuDevice(id=0, process_index=0, coords=(0,0,0), core_on_chip=0),
# TpuDevice(id=1, process_index=0, coords=(0,0,0), core_on_chip=1),
# TpuDevice(id=2, process_index=0, coords=(1,0,0), core_on_chip=0),
# TpuDevice(id=3, process_index=0, coords=(1,0,0), core_on_chip=1),
# TpuDevice(id=4, process_index=0, coords=(0,1,0), core_on_chip=0),
# TpuDevice(id=5, process_index=0, coords=(0,1,0), core_on_chip=1),
# TpuDevice(id=6, process_index=0, coords=(1,1,0), core_on_chip=0),
# TpuDevice(id=7, process_index=0, coords=(1,1,0), core_on_chip=1)]Colab と Kaggle では、8 つの個別 TPU コアを持つ TPU v2 または v3 を使用できます。TPU v3 のトレイは次のようになります。

GPT2 モデルを効率的にトレーニングするために、SPMD を介してすべての TPU コアを同時に実行し、JAX のデータ並列処理を活用します。そのために、ハードウェア メッシュを次のように定義します。
mesh = jax.make_mesh((8, 1), ('batch', 'model'))メッシュをアクセラレータの 2 次元の行列として考えます。この場合、バッチ軸とモデル軸の 2 つの軸をメッシュに定義します。合計で 8x1 となり、8 つのコアになります。これらの軸で、データとモデル パラメータの分割方法が決まります。他の並列処理スキームを試したい場合は、後で軸を変更できます。
次に、「モデル」軸を使用してモデル パラメータを分割する方法を JAX で指定し、__ init __ 関数を変更します。これを行うには、重みテンソルを初期化するときに nnx.with_partitioning を追加します。1 次元の重みテンソル(例: LayerNorm スケール / バイアス テンソル)の場合は、「モデル」軸に沿って直接シャードします。2 次元の重みテンソル(例: MHA や線形カーネル テンソル)の場合は、モデル軸に沿って 2 番目の次元をシャードします。
class TransformerBlock(nnx.Module):
def __init__(
self,
embed_dim: int,
num_heads: int,
ff_dim: int,
dropout_rate: float,
rngs: nnx.Rngs,
):
self.layer_norm1 = nnx.LayerNorm(
epsilon=1e-6, num_features=embed_dim,rngs=rngs, rngs=rngs,
scale_init=nnx.with_partitioning(
nnx.initializers.ones_init(),
("model"),
),
bias_init=nnx.with_partitioning(
nnx.initializers.zeros_init(),
("model"),
),
)
self.mha = nnx.MultiHeadAttention(
num_heads=num_heads, in_features=embed_dim,
kernel_init=nnx.with_partitioning(
nnx.initializers.xavier_uniform(),
(None, "model"),
),
bias_init=nnx.with_partitioning(
nnx.initializers.zeros_init(),
("model"),
),
)
# Other layers in the block are omitted for brevityGPT2 モデル全体でモデルテンソルの並列処理を可能にするには、他の層もこのように分割する必要があります。このチュートリアルではモデルテンソル並列処理を使用していませんが、モデルサイズは拡大する可能性があり、将来的にモデル パラメータを分割する必要が生じる可能性があるため、この機能を実装しておくことをおすすめします。モデルテンソル並列処理を実装しておくと、コードを 1 行変更するだけで、より大規模なモデルをすぐに実行できます。以下に例を示します。
mesh = jax.make_mesh((4, 2), ('batch', 'model'))次に、以前のブログと同様に、loss_fn 関数と train_step 関数を定義します。train_step () 関数は、交差エントロピー損失関数の勾配を計算し、オプティマイザーを介して重みを更新し、モデルをトレーニングするためにループ内で呼び出されます。両関数はコンピューティング負荷が高いため、最適なパフォーマンスを実現するために、@nnx.jit デコレータを使用して JIT コンパイルを行います。
@nnx.jit
def loss_fn(model, batch):
logits = model(batch[0])
loss = optax.softmax_cross_entropy_with_integer_labels(
logits=logits, labels=batch[1]
).mean()
return loss, logits
@nnx.jit
def train_step(
model: nnx.Module,
optimizer: nnx.Optimizer,
metrics: nnx.MultiMetric,
batch,
):
grad_fn = nnx.value_and_grad(loss_fn, has_aux=True)
(loss, logits), grads = grad_fn(model, batch)
metrics.update(loss=loss, logits=logits, lables=batch[1])
optimizer.update(grads)オプティマイザーには、Optax の AdamW を使用し、コサイン減衰スケジュールを採用しています。Optax では、他のオプティマイザーやスケジュールを試すこともできます。
schedule = optax.cosine_decay_schedule(
init_value=init_learning_rate, decay_steps=max_steps
)
optax_chain = optax.chain(
optax.adamw(learning_rate=schedule, weight_decay=weight_decay)
)
optimizer = nnx.Optimizer(model, optax_chain)最後に、シンプルなトレーニング ループを作成します。
while True:
input_batch, target_batch = get_batch("train")
train_step(
model,
optimizer,
train_metrics,
jax.device_put(
(input_batch, target_batch),
NamedSharding(mesh, P("batch", None)),
),
)
step += 1
if step > max_steps:
breakjax.device_put 関数を使用して、バッチ軸に沿って入力データを分割する方法に注意してください。この場合、JAX はデータの並列処理を有効にし、通信集合体(AllReduce)を自動的に挿入してすべてのデータをまとめ、可能な限りコンピューティングと通信を重複させます。並列計算について詳しくは、JAX の並列プログラミングの概要に関するドキュメントをご覧ください。
この時点でモデルはトレーニング中です。Weights and Biases を使用して実行をトラッキングしている場合は、トレーニングの損失を観察できます。GPT2 124M モデルをトレーニングするためのテスト実行は次のとおりです。
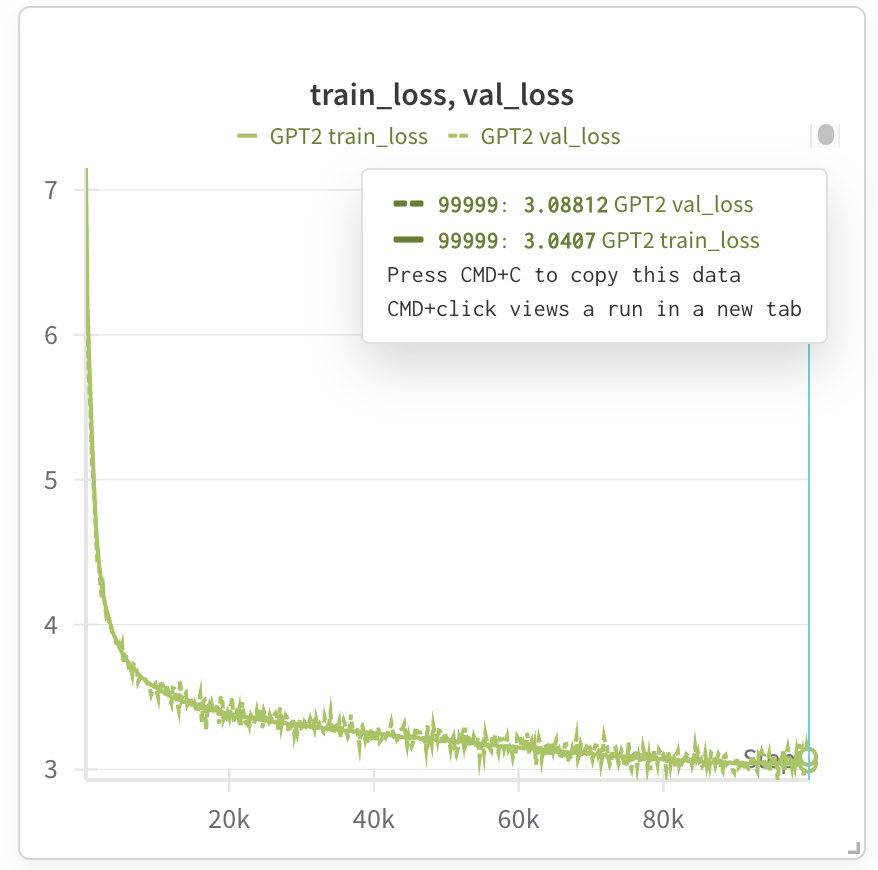
Kaggle TPU v3(中断なしで 9 時間使用可能)では約 7 時間かかりますが、Trillium を使用すると、トレーニング時間は約 1.5 時間に短縮されます(Trillium にはチップごとに 32G の HBM(高帯域幅メモリ)が搭載されているため、バッチサイズを 2 倍にしてトレーニング ステップを半分にすることができます)。
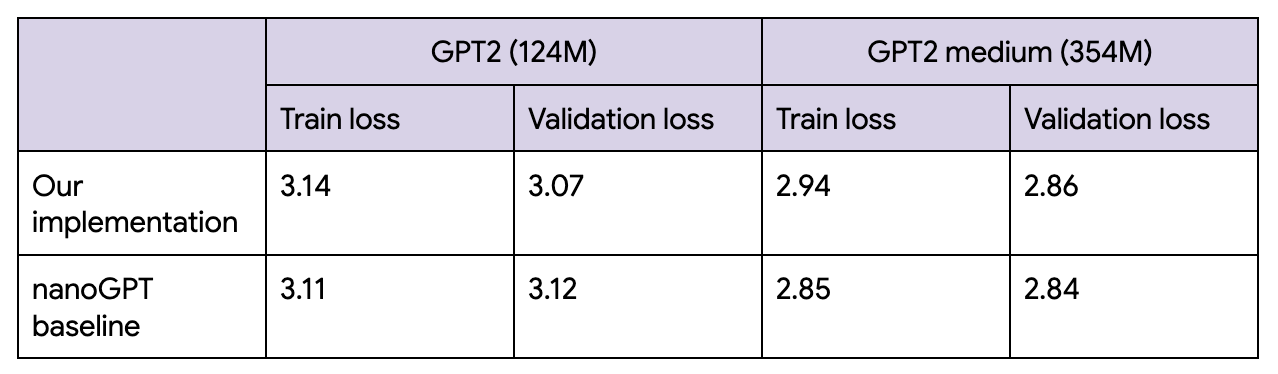
最終的な損失は、nanoGPT とほぼ一致しています。私は今回のコード例を書きながら楽しんで勉強することができました。
Cloud TPU を使用する場合、「tpu-info」コマンド(Cloud TPU Monitoring Debugging パッケージの一部)または Weights and Biases のダッシュボードを使用して、TPU 使用率をモニタリングすることもできます。TPU の稼働がわかるでしょう。
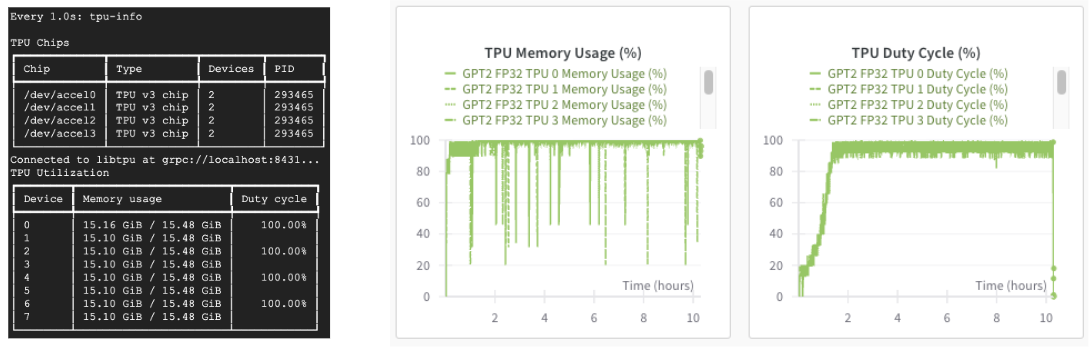
モデルのトレーニング後は、次のように Orbax を使用して保存できます。
checkpointer = orbax.PyTreeCheckpointer()
train_state = nnx.pure(nnx.state(model))
checkpointer.save(checkpoint_path, train_state)以上で完了です。これが GPT2 モデルをトレーニングするために必要なほぼすべての内容です。データ読み込み、ハイパーパラメータ、指標などの詳細は、完全なノートブックをご確認ください。
もちろん、現在のところ GPT2 は小さなモデルであり、多くの最先端ラボでは数千億のパラメータを持つモデルをトレーニングしています。しかし、JAX と TPU を使用して小さな言語モデルを構築する方法を学んだ皆さんは、次にモデルをスケーリングする方法を学ぶことができます。
さらに、MaxText を使用して事前構築された最先端の LLM をトレーニングしたり、JAX LLM の例や Stanford Marin モデルを参考にして最新のモデルをゼロから構築する方法を学んだりすることもできるでしょう。
皆さんが JAX と TPU を使用して開発する素晴らしいモデルを楽しみにしています!
KerasHub を使用して Hugging Face で簡単なエンドツーエンドの機械学習ワークフローを実現

Java 向け ADK、LangChain4j 統合によってサードパーティ言語モデルに対応

Building with Gemini 3 in Jules
多言語 LLM のイノベーション: オープンモデルでグローバル コミュニケーションを推進する

Grain と ArrayRecord を使用した高性能データ パイプラインの構築

Announcing the Data Commons Gemini CLI extension