

MongoDB Atlas 用の Google Cloud Dataflow テンプレートが大幅に強化されました。JSON データ型が直接サポートされたことで、MongoDB Atlas データと BigQuery がシームレスに連携できるようになり、複雑なデータ変換が不要になります。
この効率的なアプローチにより、時間とリソースを節約できます。さらに、高度なデータ分析と機械学習を通じて、データの可能性を最大限に引き出せるようになります。
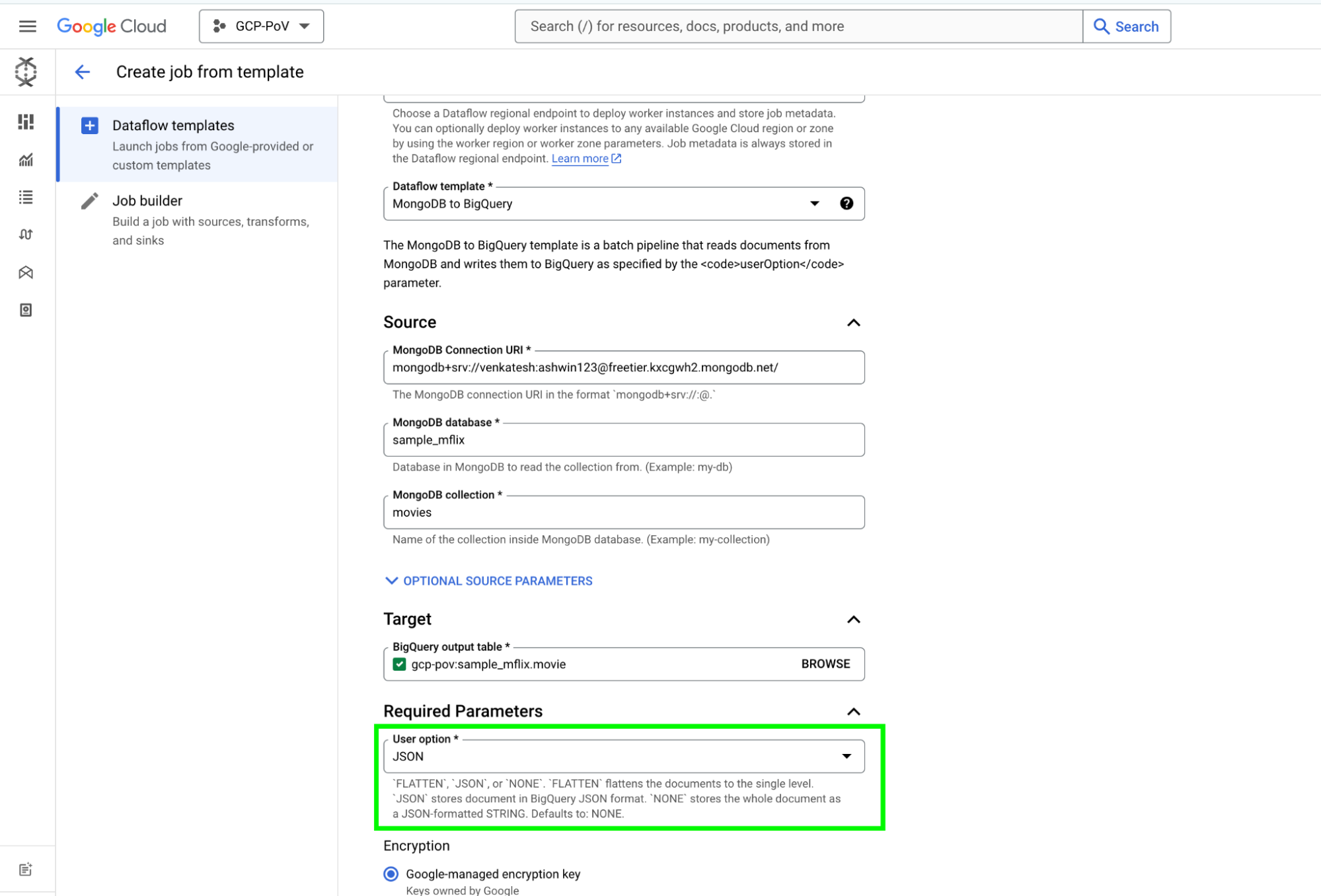
これまで、MongoDB Atlas データを処理する Dataflow パイプラインでは、BigQuery に読み込む前に、データを JSON 文字列に変換したり、複雑な構造をネストのないフラットな構造に変換したりする必要がありました。このアプローチは実現可能ですが、いくつかの欠点を伴います。
BigQuery のネイティブ JSON 形式では、ネストされた JSON データを中間変換なしに MongoDB Atlas から BigQuery に直接読み込めるようにすることで、前述の課題に対処します。
このアプローチは多くの利点をもたらします。
このパイプラインの大きな利点は、MongoDB データを BigQuery に読み込み、BigQuery の強力な JSON 関数を直接活用できる点にあります。これにより、複雑で時間のかかるデータ変換プロセスが不要になります。BigQuery の JSON データは、標準の BQML クエリを使って照会したり分析したりできます。
効率的なクラウドベースのアプローチがお好みの方も、実践的でカスタマイズ可能なソリューションがお好みの方も、Google Cloud コンソールから、または github リポジトリからコードを実行することで、Dataflow パイプラインをデプロイすることができます。
つまり、Google の Dataflow テンプレートは、MongoDB から BigQuery にデータを転送する柔軟なソリューションです。MongoDB の変更ストリーム機能を使えば、コレクション全体を処理したり、増分変更を取得したりできます。パイプラインの出力形式は、特定のニーズに合わせてカスタマイズできます。未加工の JSON 表現で扱いたい場合でも、個々のフィールドが存在するフラットなスキーマで扱いたい場合でも、userOption パラメータを使って簡単に構成できます。さらに、ユーザー定義関数(UDF)を使えば、テンプレート実行中にデータ変換を行うこともできます。
Dataflow パイプラインに BigQuery ネイティブ JSON 形式を採用することで、データ処理ワークフローの効率、パフォーマンス、費用対効果を大幅に向上させることができます。この強力な組み合わせにより、データから貴重な知見を抽出し、データドリブンな意思決定を実現できます。
MongoDB Atlas と BigQuery 用の Dataflow テンプレートの設定方法については、Google のドキュメントをご覧ください。

Google Colab is Coming to VS Code

スタンフォード大学の Marin 基盤モデル: JAX を使用して開発された初の完全オープンモデル

Firebase Studio でエージェント AI 開発を推進

Building with Gemini 3 in Jules

Announcing the Data Commons Gemini CLI extension

Building production AI on Google Cloud TPUs with JAX