

Google AI Edge Torch を発表いたします。Google AI Edge Torch は、PyTorch から TensorFlow Lite(TFLite)ランタイムへの直接パスで、モデルのカバレッジと CPU パフォーマンスに優れています。TFLite では、すでに JAX、Keras、TensorFlow で記述したモデルが動作しています。そして今回、フレームワークの自由度を高める幅広い取り組みの一環として、PyTorch を追加します。
この新しい仕組みは、Google AI Edge の一部として利用できるようになっています。Google AI Edge は、すぐに使える ML タスクや ML パイプラインを構築できるフレームワークにアクセスしたり、人気の LLM やカスタムモデルを実行したりできるツール群で、すべてオンデバイスで利用できます。本投稿は、Google AI Edge のリリースについて説明するブログ投稿の初回です。一連のブログ投稿を通して、デベロッパーの皆さんが AI 機能を開発し、複数のプラットフォームに簡単にデプロイするのに役立つ情報をお届けします。
AI Edge Torch は、本日ベータ版としてリリースされました。主な機能は次のとおりです。
Google AI Edge Torch は、PyTorch コミュニティに優れたエクスペリエンスを提供できるように、ゼロから構築されました。ネイティブに感じられる API と、簡単な変換パスが提供されています。
import torchvision
import ai_edge_torch
# モデルを初期化
resnet18 = torchvision.models.resnet18().eval()
# 変換
sample_input = (torch.randn(4, 3, 224, 224),)
edge_model = ai_edge_torch.convert(resnet18, sample_input)
# Python で推論
output = edge_model(*sample_input)
# オンデバイス デプロイ用に TFLite モデルにエクスポート
edge_model.export('resnet.tflite'))ai_edge_torch.convert() は、内部的に torch.export を使って TorchDynamo と連携しています。これは PyTorch 2.x の手法で、PyTorch モデルを標準モデル表現にエクスポートし、さまざまな環境で実行できるようにします。現在の実装では core_aten オペレータの 60% 以上をサポートしていますが、ai_edge_torch の 1.0 リリースに向けた作業の中で、その数を大幅に増やす予定です。また、量子化ワークフローを簡単に実現できるように、PyTorch 2 固有の量子化アプローチである PT2E 量子化の例も含めました。PyTorch で始まるイノベーションを幅広いデバイスに導入するうえで、デベロッパーのエクスペリエンスを向上させる方法を見つけたいと思っていますので、PyTorch コミュニティからのご意見をお待ちしています。
このリリース以前、多くのデベロッパーは、TFLite で PyTorch モデルを動作させるために、ONNX2TF などのコミュニティが提供するパスを使っていました。AI Edge Torch の開発目標は、デベロッパーの手間を軽減し、モデルのカバレッジを広げ、Android デバイスでクラス最高のパフォーマンスを提供するというミッションを継続することでした。
カバレッジのテストでは、既存のワークフロー、とりわけ ONNX2TF で定義されているモデルセットに対して、大幅な改善が示されています。
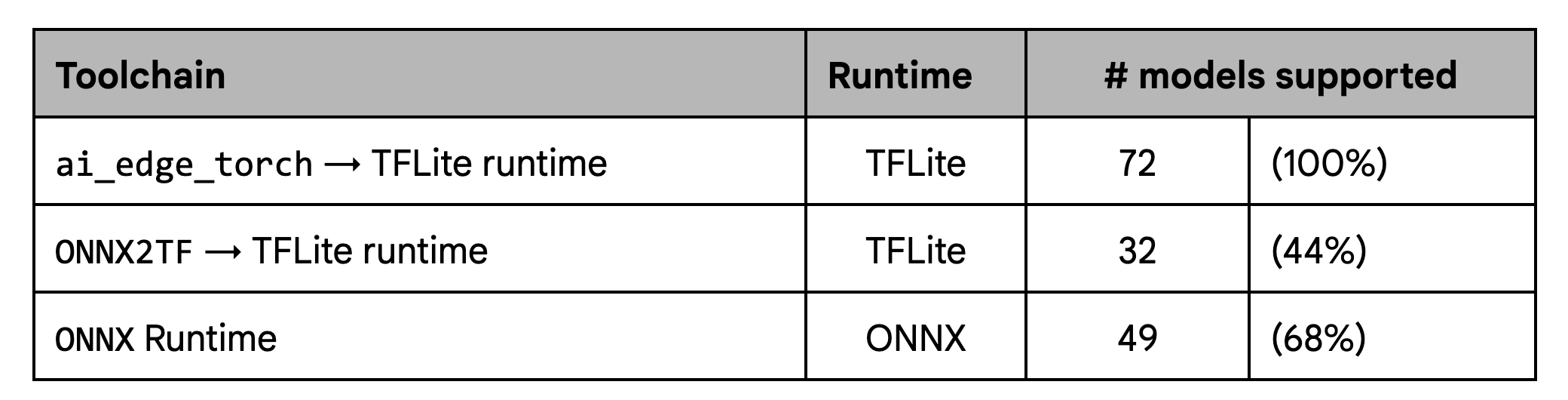
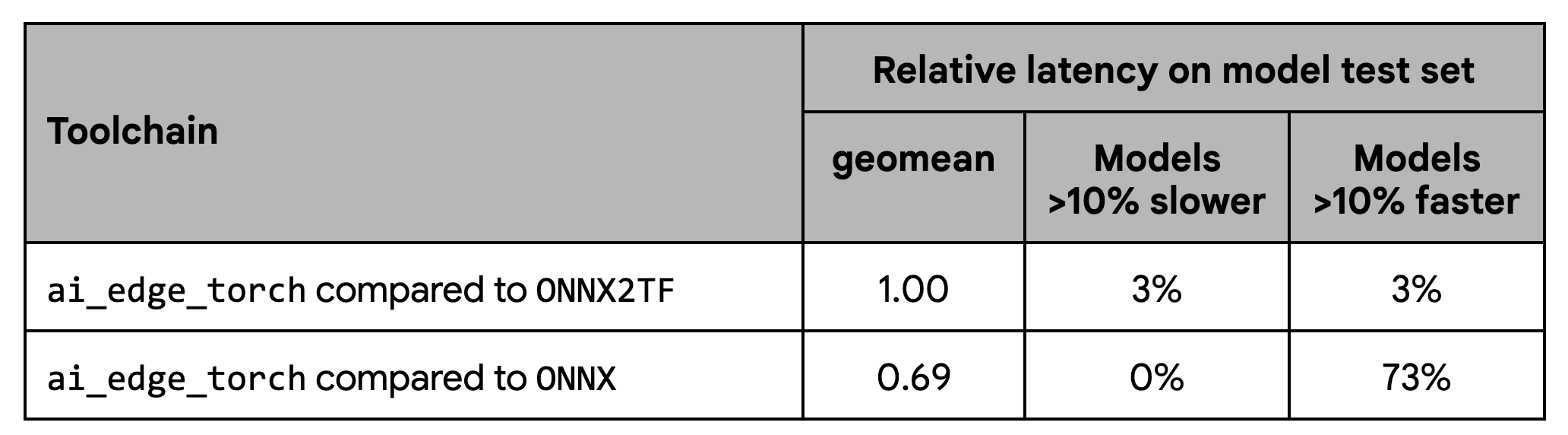
パフォーマンスのテストでは、ONNX2TF と同等のパフォーマンスを示しましたが、ONNX ランタイムよりは有意にパフォーマンスが優れていることも示されています。
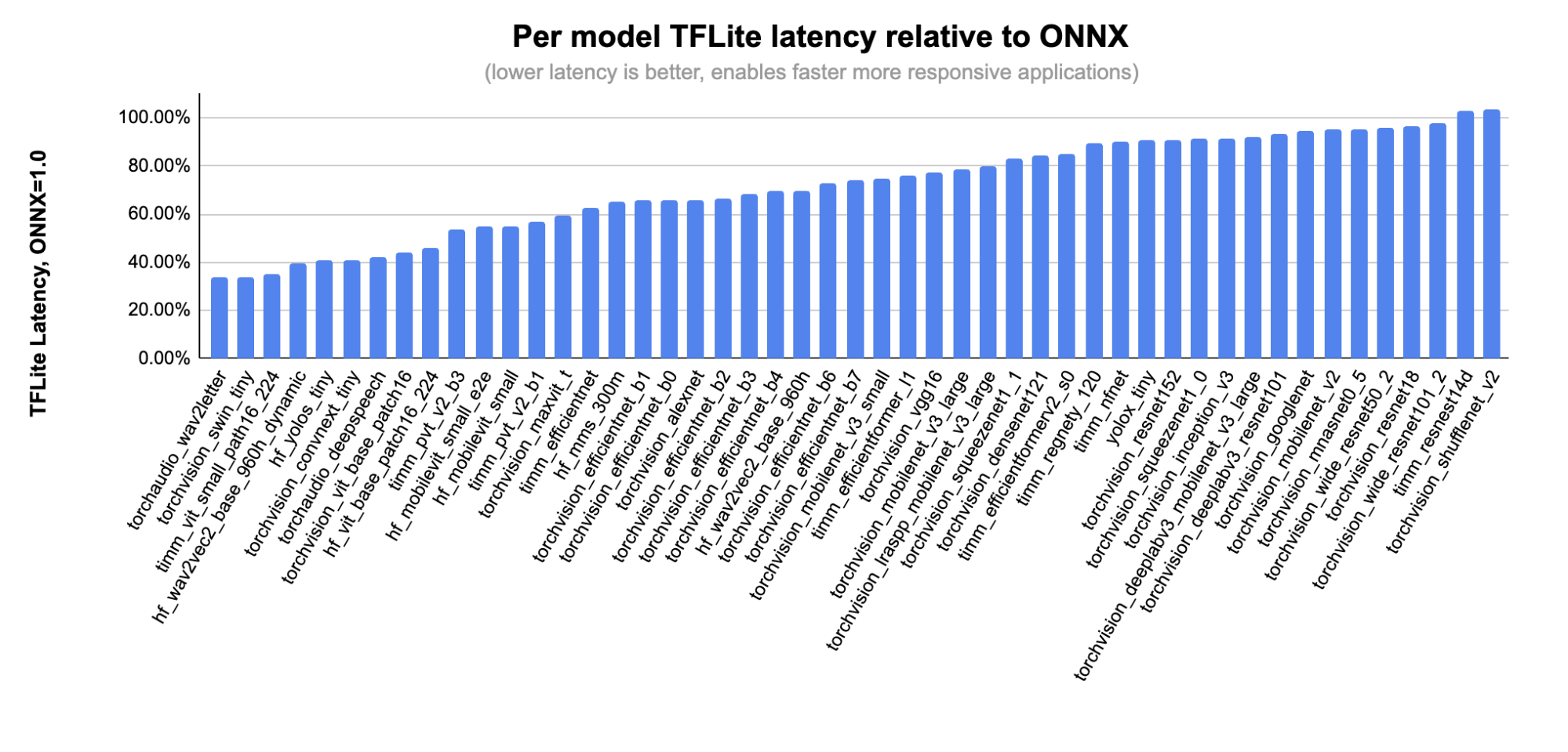
次の図では、ONNX に対応したモデルのサブセットごとに、各モデルの詳しいパフォーマンスを示します。
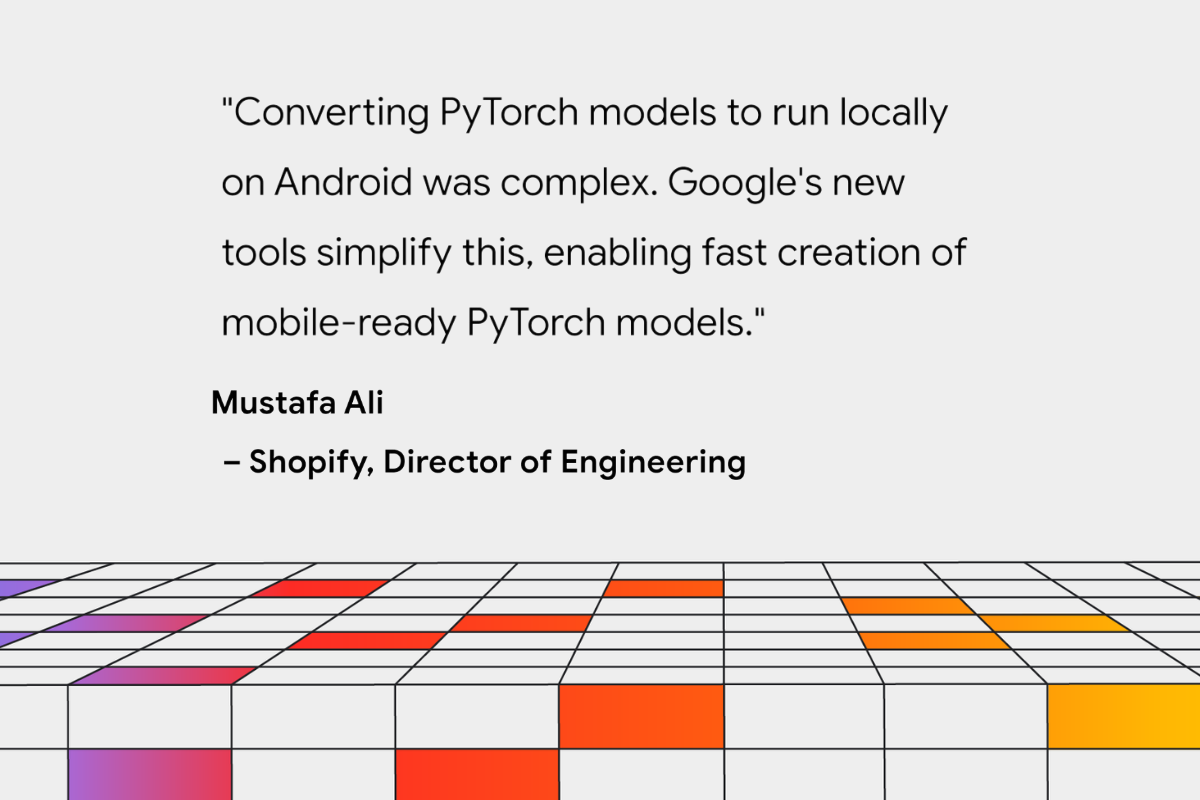
これまでの数か月間で、Shopify、Adobe、Niantic などの早期導入パートナーと密に連携しながら、PyTorch のサポートを改善してきました。Shopify のチームは、すでに ai_edge_torch を使ってオンデバイスで製品画像の背景を削除する処理を行っています。この機能は、Shopify アプリの今後のリリースで利用できるようになる予定です。
また、パートナーと密に協力して、Arm、Google Tensor G3、MediaTek、Qualcomm、Samsung System LSI など、さまざまな CPU、GPU、アクセラレータのハードウェア サポートに取り組んできました。こういったパートナーシップを通じて、パフォーマンスとカバレッジを向上させ、複数のアクセラレータ デリゲートで PyTorch から生成した TFLite ファイルを検証しました。
ここでは、うれしいことに、Qualcomm の新しい TensorFlow Lite デリゲートについても共同発表します。こちらから、すべてのデベロッパーが利用できます。TFLite Delegates は、GPU とハードウェア アクセラレータでの実行を高速化するアドオン ソフトウェア モジュールです。この新しい QNN デリゲートは、さまざまな Qualcomm チップセットをサポートしながら、PyTorch ベータ版テストセットのほとんどのモデルをサポートしています。さらに、Qualcomm の DSP とニューラル プロセッシング ユニットを使えば、平均速度が CPU(20 倍)や GPU(5 倍)よりも大幅に向上します。先日、Qualcomm は、簡単にテストできるようにするための新しい AI ハブもリリースしています。Qualcomm AI Hub は、デベロッパーが多様な Android デバイス群で TFLite モデルをテストできるようにするクラウド サービスです。さまざまなデバイスで QNN デリゲートを使って向上させることができるパフォーマンスを可視化することもできます。
今後数か月間では、1.0 リリースに向けて、モデルのカバレッジの拡大、GPU サポートの改善、新しい量子化モードなどにオープンに取り組んでゆきます。このシリーズのパート 2 では、AI Edge Torch Generative API について詳しく説明する予定です。これは、高いパフォーマンスのカスタム生成 AI モデルをエッジに導入できるようにする仕組みです。
早期アクセス ユーザーの皆さんの貴重なフィードバックのおかげで、早い段階でバグを発見し、スムーズなデベロッパー エクスペリエンスを確保することができました。また、さまざまなデバイスのパフォーマンス向上に貢献してくれたハードウェア パートナーや、XNNPACK エコシステムの貢献者の皆さんにも感謝いたします。また、さまざまな Pytorch コミュニティの皆さんのご指導とご支援に感謝いたします。
謝辞
この作業に協力していただいたすべてのチームメンバー、Aaron Karp、Advait Jain、Akshat Sharma、Alan Kelly、Arian Arfaian、Chun-nien Chan、Chuo-Ling Chang、Claudio Basille、Cormac Brick、Dwarak Rajagopal、Eric Yang、Gunhyun Park、Han Qi、Haoliang Zhang、Jing Jin、Juhyun Lee、Jun Jiang、Kevin Gleason、Khanh LeViet、Kris Tonthat、Kristen Wright、Lu Wang、Luke Boyer、Majid Dadashi、Maria Lyubimtseva、Mark Sherwood、Matthew Soulanille、Matthias Grundmann、Meghna Johar、Milad Mohammadi、Na Li、Paul Ruiz、Pauline Sho、Ping Yu、Pulkit Bhuwalka、Ram Iyengar、Sachin Kotwani、Sandeep Dasgupta、Sharbani Roy、Shauheen Zahirazami、Siyuan Liu、Vamsi Manchala、Vitalii Dziuba、Weiyi Wang、Wonjoo Lee、Yishuang Pang、Zoe Wang、そして StableHLO チームに感謝いたします。

Google AI Edge Gallery: 音声サポートが追加され Google Play で利用可能に

マルチモダリティ、RAG、および関数呼び出しに対応したオンデバイス小型言語モデル

Building with Gemini 3 in Jules

LiteRT: シンプルさとパフォーマンスが向上

LiteRT-LM を活用した Chrome、Chromebook Plus、Google Pixel Watch でのオンデバイス生成 AI

Announcing the Data Commons Gemini CLI extension