

AI coding agents like Jules can build, refactor, and scaffold code while you focus on other things. That convenience and ease of use is thrilling, but can sometimes also mean subtle bugs, missed edge cases, and untested assumptions. That’s why we’re introducing a new capability in Jules that reviews and critiques code before you see it.
The role is simple but powerful: while Jules builds, the critic functionality challenges. Every proposed change undergoes adversarial review before completion. Think of the critic feature as Jules’ peer reviewer, deeply familiar with code quality principles and unafraid to point out when you’ve reinvented a risky wheel.
The critic is integrated directly into the code generation process, called critic-augmented generation. For this first version, it’s a one-shot process that evaluates the final output in a single pass. Future milestones will aim to make it a true multi-step agent, capable of using tool calls or triggering after subtasks or before planning, but for now it reviews the complete generation at once. This will draw on multi-step research, where a critic validates outputs using external tools (like a code interpreter or search engine) and learns from those outcomes.
The critic doesn’t fix code, it flags it, then hands it back to Jules to improve. For example:
Because this happens after patch generation and before submission (possibly multiple times if still flagged), Jules can replan in real time. Our goal is fewer slop PRs, better test coverage, stronger security.
Linters follow shallow, fixed rules; tests validate specific assertions. The critic capability understands the intent and context behind code. It’s closer to a reference-free evaluation method, judging correctness and robustness, without needing a gold-standard implementation.
It also takes cues from research on LLM-as-a-judge, where a model evaluates another model’s work for quality and correctness. This kind of automated judging is especially useful when integrated tightly with generation, turning review into a live feedback loop.
1: You prompt Jules to start a task.
2: The critic feature reviews the candidate patch and its description in a single pass, making an overall judgement.
3: Jules responds to feedback before finishing, after which the critic can review the updated patch again and continue flagging anything it deems necessary until no further issues remain.
4: You receive code that’s already been internally reviewed.
This draws from actor-critic reinforcement learning (RL), where an “actor” generates and a “critic” evaluates. In RL, this loop updates the actor and critic based on a learning signal. In our LLM-as-critic setup, the pattern is similar: propose, then evaluate. However, instead of updating learning parameters, the feedback influences the current state and next steps. This same principle also underpins research on LLM-as-a-judge, where the critic’s evaluation guides quality without retraining.
In a world of rapid iteration, the critic moves the review to earlier in the process and into the act of generation itself. This means the code you review has already been interrogated, refined, and stress-tested. Of course, you should always review the generated code carefully before use.
Great developers don’t just write code, they question it. And now, so does Jules.
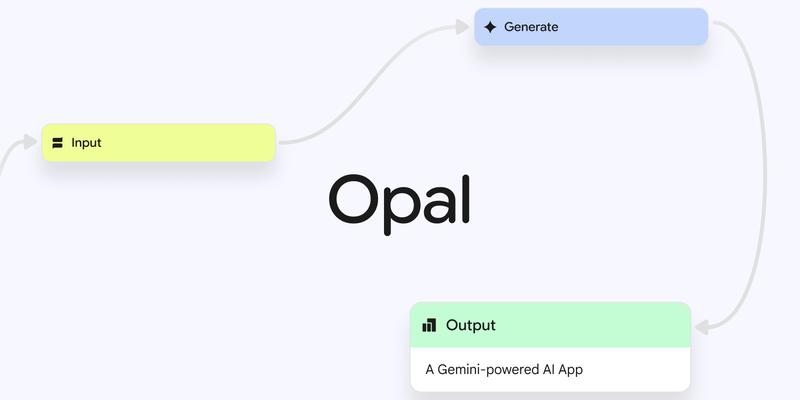
Introducing Opal: describe, create, and share your AI mini-apps
Unlocking Peak Performance on Qualcomm NPU with LiteRT

Architecting efficient context-aware multi-agent framework for production

Announcing the Data Commons Gemini CLI extension

Stop “vibe testing” your LLMs. It's time for real evals.