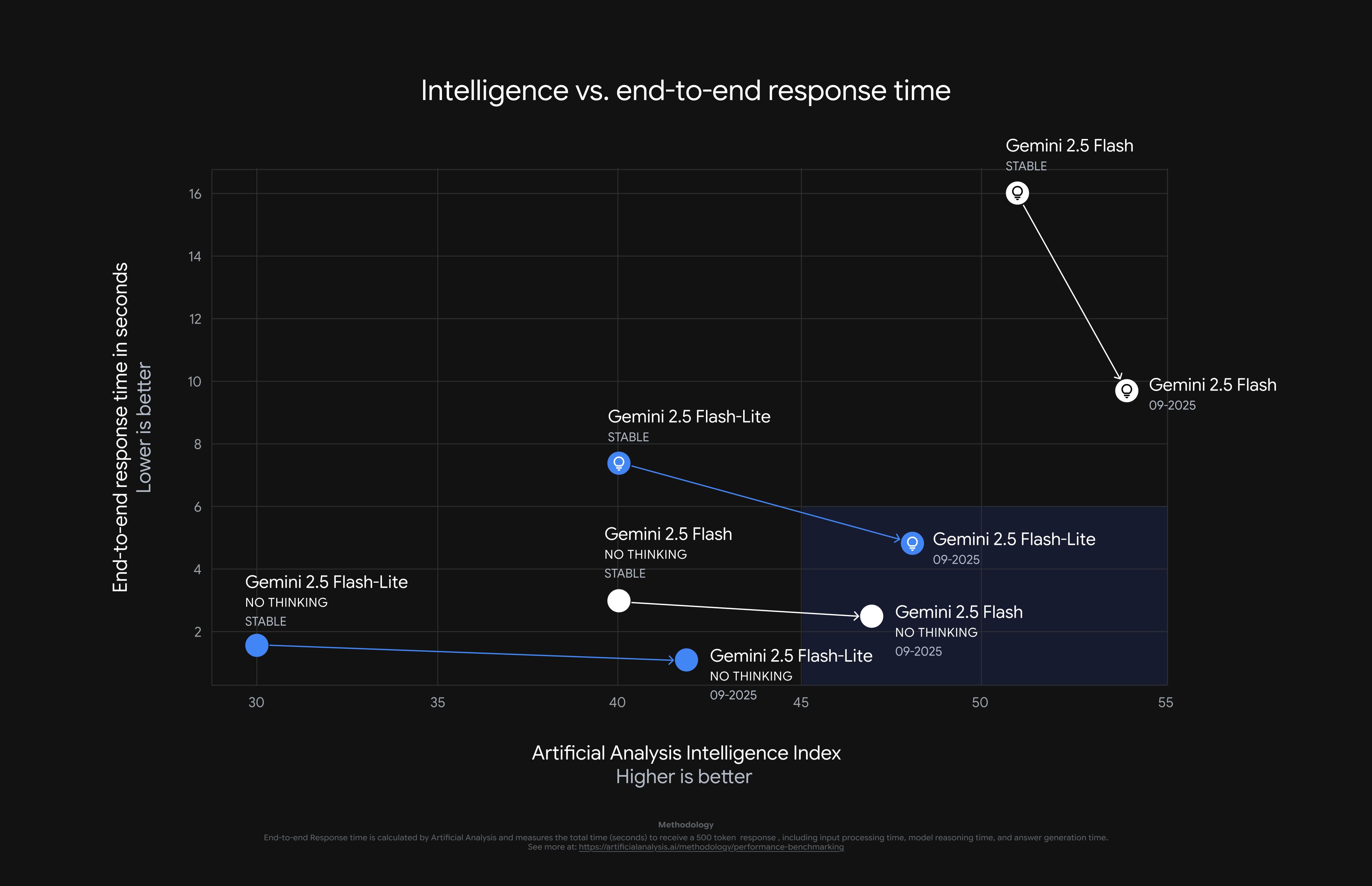
Today, we are releasing updated versions of Gemini 2.5 Flash and 2.5 Flash-Lite, available on Google AI Studio and Vertex AI, aimed at continuing to deliver better quality while also improving the efficiency.
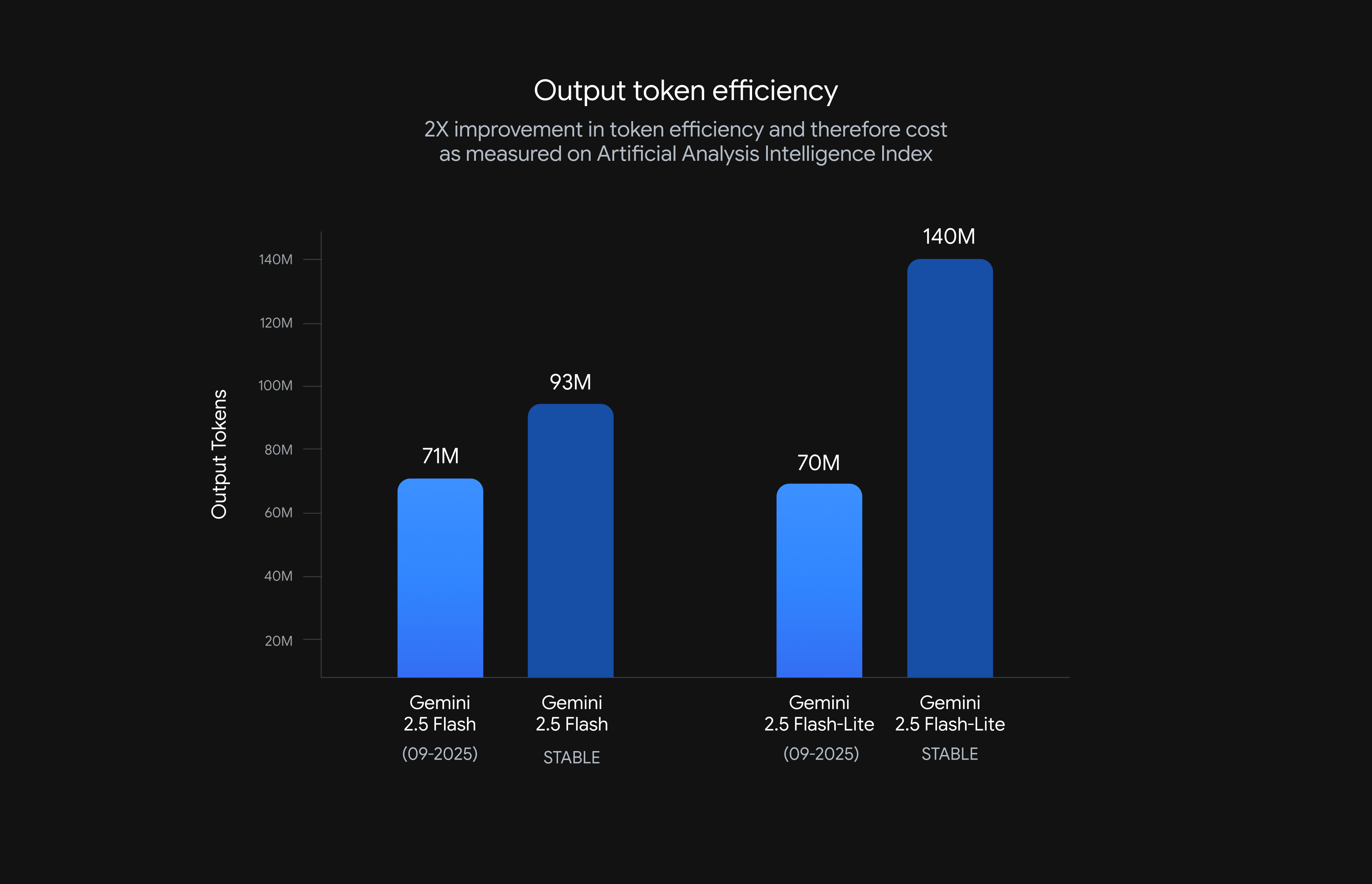
The latest version of Gemini 2.5 Flash-Lite was trained and built based on three key themes:
You can start testing this version today using the following model string: gemini-2.5-flash-lite-preview-09-2025.
This latest 2.5 Flash model comes with improvements in two key areas we heard consistent feedback on:
We’re already seeing positive feedback from early testers. As Yichao ‘Peak’ Ji, Co-Founder & Chief Scientist at Manus, an autonomous AI agent, noted: “The new Gemini 2.5 Flash model offers a remarkable blend of speed and intelligence. Our evaluation on internal benchmarks revealed a 15% leap in performance for long-horizon agentic tasks. Its outstanding cost-efficiency enables Manus to scale to unprecedented levels—advancing our mission to Extend Human Reach.”
You can start testing this preview version today by using the following model string: gemini-2.5-flash-preview-09-2025.
Over the last year, we’ve learned that shipping preview versions of our models allows you to test our latest improvements and innovations, provide feedback, and build production-ready experiences with the best of Gemini. Today’s releases are not intended to graduate to a new, stable version but will help us shape our future stable releases, and allow us to continue iterating and bring you the best of Gemini.
To make it even easier to access our latest models while also reducing the need to keep track of long model string names, we are also introducing a -latest alias for each model family. This alias always points to our most recent model versions, allowing you to experiment with new features without needing to update your code for each release. You can access the new previews using:
gemini-flash-latestgemini-flash-lite-latest
To ensure you have time to test new models, we will always provide a 2-week notice (via email) before we make updates or deprecate a specific version behind -latest. These are just model aliases so the rate limits, cost, and features available may fluctuate between releases.
For applications that require more stability, continue to use gemini-2.5-flash and gemini-2.5-flash-lite.
We continue to push the frontier of what is possible with Gemini and this release is just another step in that direction. We will have more to share soon, but in the meantime, happy building!