在快速发展的大型语言模型 (LLM) 领域,人们的注意力主要集中在 Decoder-only 架构上。尽管这些模型在各种生成任务中展现出令人印象深刻的能力,但经典的 Encoder-Decoder 架构,例如 T5(文本到文本传输转换器),仍然是许多实际应用的热门选择。Encoder-Decoder 模型凭借其高推理效率、设计灵活性以及更丰富的编码器表征(用于理解输入),在摘要、翻译、问答等方面往往表现出色。然而,强大的 Encoder-Decoder 架构受到的关注却相对较少。
如今,我们重新审视这一架构,并推出 T5Gemma。这是全新的 Encoder-Decoder LLM 系列,通过一种称为“自适应”的技术将预训练的 Decoder-only 模型转换为 Encoder-Decoder 架构而开发。T5Gemma 依托于 Gemma 2 框架,包含经过自适应的 Gemma 2 2B 和 9B 模型,以及一组新训练的多种规模的 T5 模型(Small、Base、Large 和 XL)。我们很高兴向社区发布经过预训练和指令调优的 T5Gemma 模型,以获取新的研发机遇。
在 T5Gemma 中,我们提出了以下问题:我们能否基于预训练的 Decoder-only 模型构建顶级 Encoder-Decoder 模型?我们通过探索一种称为模型自适应的技术来回答这个问题。其核心思想是先使用已预训练的 Decoder-only 模型的权重来初始化 Encoder-Decoder 模型的参数,然后再通过 UL2 或基于 PrefixLM 的预训练对其进行进一步调整。
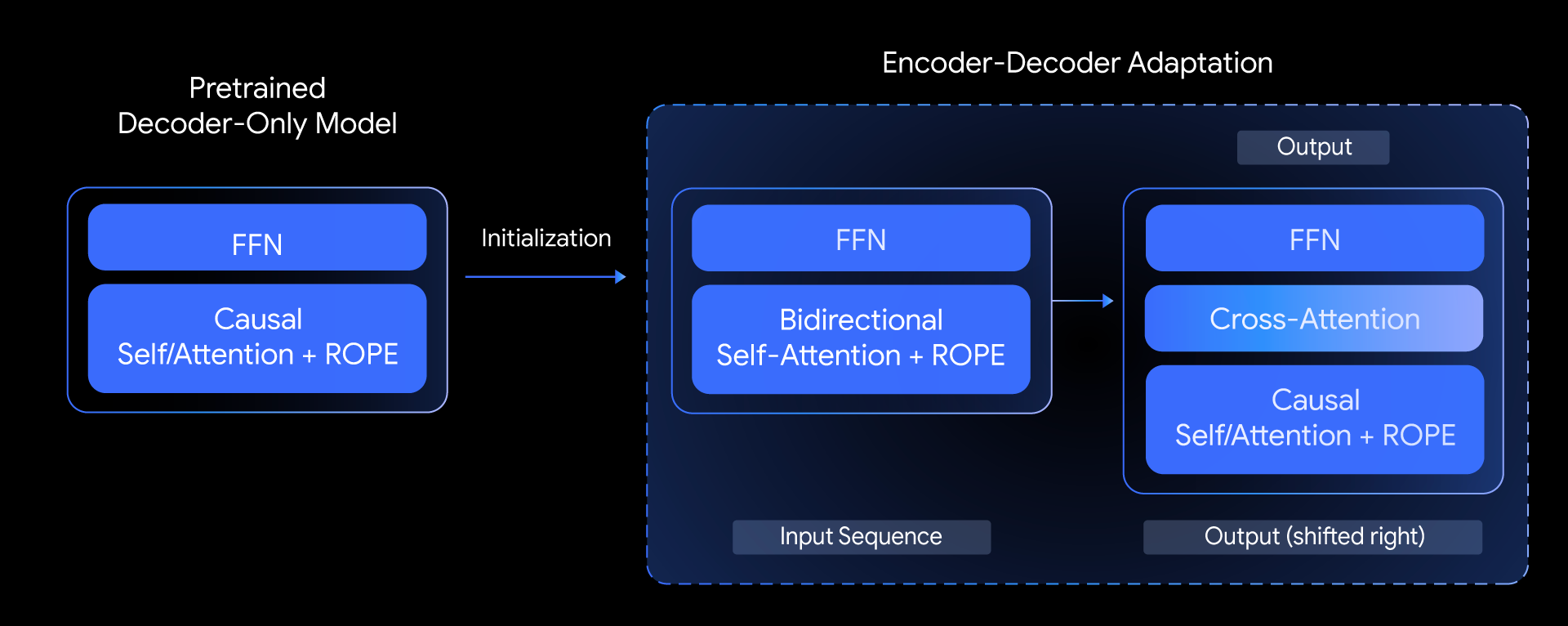
这种自适应方法高度灵活,能够实现模型规模的创造性组合。例如,我们可以将大型编码器与小型解码器(例如,9B 编码器与 2B 解码器)搭配使用,以创建一个“不平衡”模型。这使我们能够针对特定任务(例如摘要)调整质量与效率之间的平衡,因为对于特定任务而言,对输入的深入理解比生成输出的复杂程度更为重要。
T5Gemma 的表现如何?
在我们的实验中,T5Gemma 模型与其 Decoder-only 版本的 Gemma 模型相比,取得了相当甚至更优的性能,在多个基准测试(如衡量所学习表征质量的 SuperGLUE)中几乎占据了质量-推理效率的帕累托前沿。
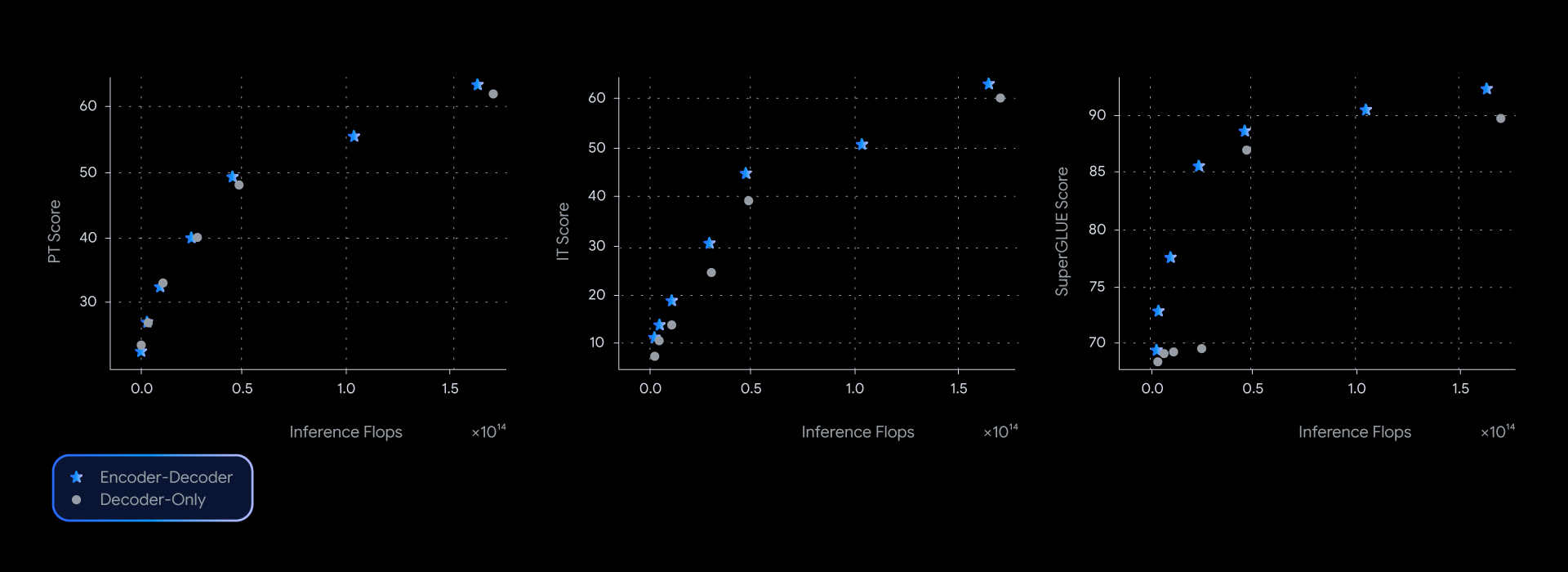
这种性能优势并非仅限于理论层面;它同样体现在实际应用的质量与速度上。在测量 GSM8K(数学推理)的实际延迟时,T5Gemma 展现出了明显优势。例如,T5Gemma 9B-9B 的准确率高于 Gemma 2 9B,但延迟却相近。更令人印象深刻的是,T5Gemma 9B-2B 相较于 2B-2B 模型提供了显著的准确率提升,而其延迟几乎与体积小得多的 Gemma 2 2B 模型相同。最终,这些实验证明,Encoder-Decoder 架构的改造能够以灵活且强大的方式在模型质量与推理速度之间实现平衡。
Encoder-Decoder LLM 的功能是否与 Decoder-only 模型类似?
是的,T5Gemma 在经过指令调优前后都表现出良好的性能。
经过预训练后,T5Gemma 在需要推理的复杂任务上取得了令人瞩目的进步。例如,T5Gemma 9B-9B 在 GSM8K(数学推理)上的得分比原始 Gemma 2 9B 模型高出 9 分以上,在 DROP(阅读理解)上的得分也高出 4 分。这表明,Encoder-Decoder 架构在通过自适应初始化后,有潜力构建一个功能更强大、性能更佳的基础模型。
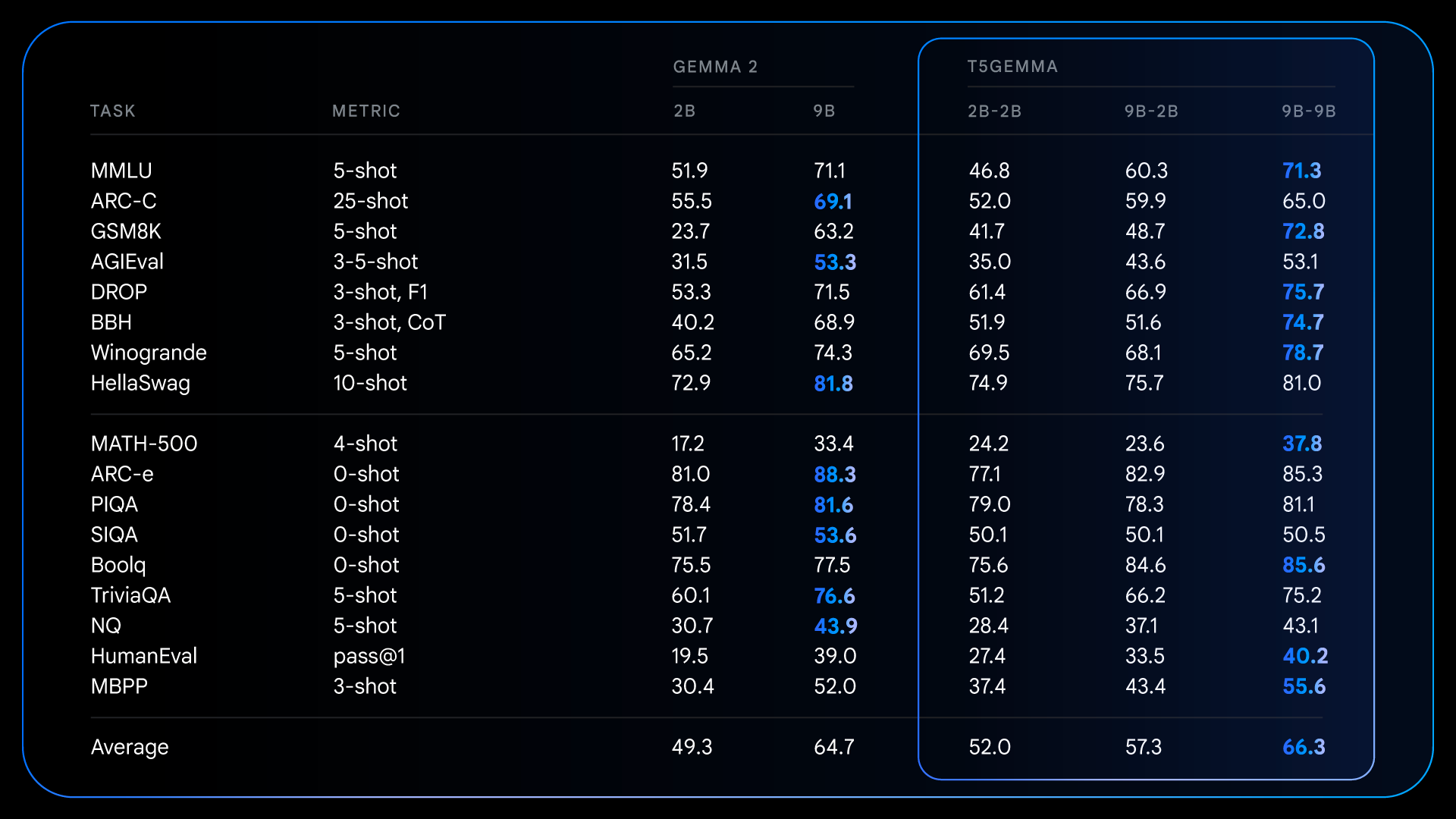
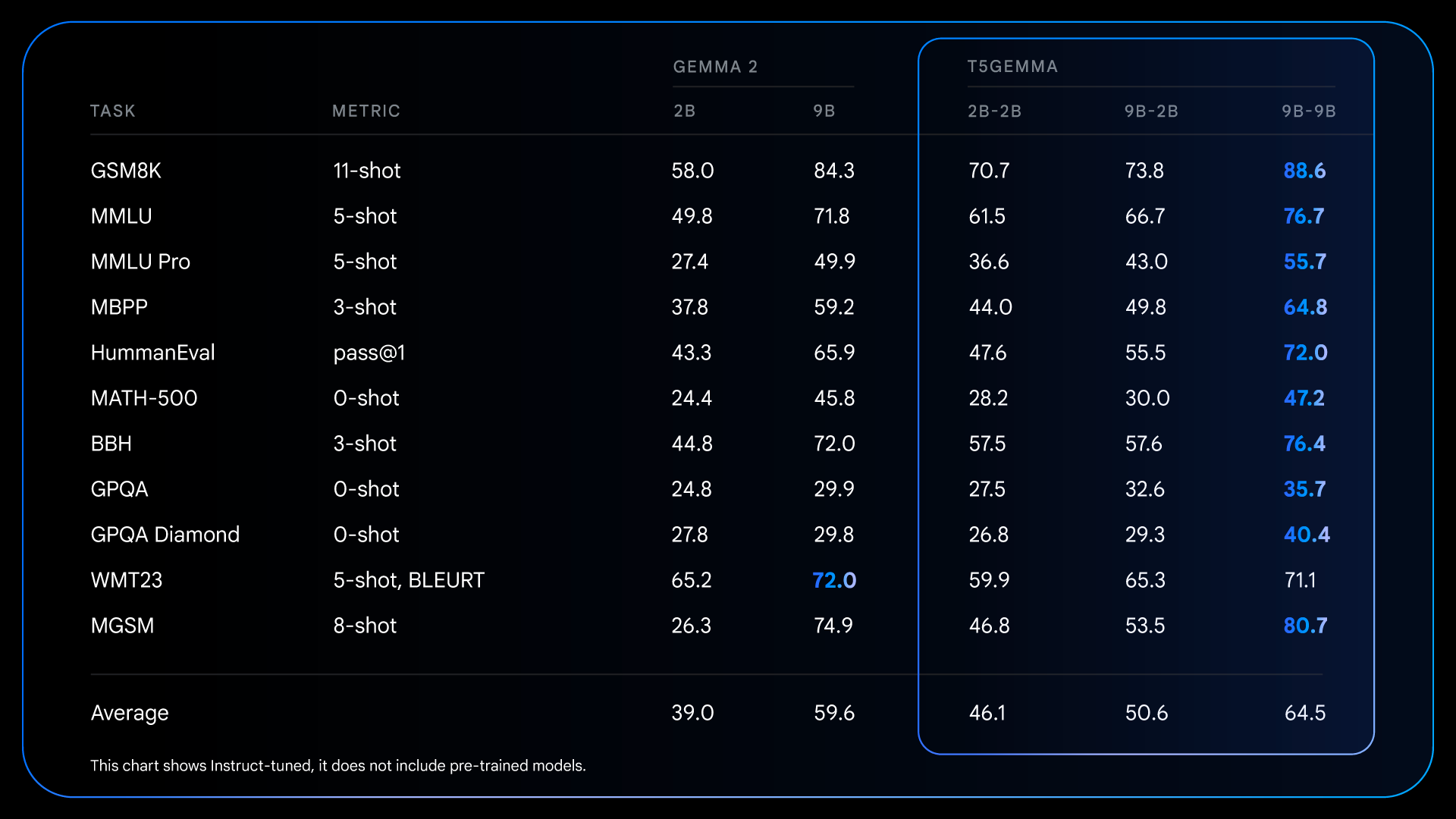
预训练阶段的这些基础性改进,为指令微调后取得更为显著的性能提升奠定了基础。例如,将 Gemma 2 IT 与 T5Gemma IT 进行比较时,性能差距在各方面的评测中都显著扩大。T5Gemma 2B-2B IT 的 MMLU 得分比 Gemma 2 2B 提升了近 12 分,其 GSM8K 得分也从 58.0% 提升至 70.7%。这种经过调整的架构不仅可能提供了一个更好的起点,而且能够更有效地响应指令调整,最终构建出一个功能更强大、更实用的最终模型。
我们非常高兴地推出这种新方法,以用于构建强大且通用的 Encoder-Decoder 模型,这种方法借鉴了 Gemma 2 等预训练的 Decoder-only LLM。为了帮助加速开展进一步的研究并让社区在此基础上继续发展,我们很高兴发布了一套 T5Gemma 检查点。
该版本包括:
我们希望这些检查点能为研究模型架构、效率和性能提供宝贵的资源。
我们迫不及待地想看到您使用 T5Gemma 打造的作品。如要了解更多信息,请访问以下链接: