

VTuber(가상 유튜버)는 컴퓨터 그래픽을 사용하여 생성된 가상 아바타를 사용하는 온라인 엔터테이너입니다. 이러한 디지털 트렌드는 2010년 중반 일본에서 시작되어 온라인 세계에서는 국제적 현상이 되었습니다. 대다수의 VTuber는 영어와 일본어를 구사하는 유튜버이거나 아바타 디자인을 사용하는 라이브 스트리머입니다.
4천만 명 이상의 고객을 보유한 일본의 통신 사업자 KDDI는 5G 네트워크를 기반으로 구축된 다양한 기술을 실험하고자 했으나, 실시간으로 정확한 움직임과 사람 같은 표정을 구현하기 어렵다는 점을 인식하게 되었습니다.
5월 Google I/O 2023에서 발표된 MediaPipe Face Landmarker 솔루션은 얼굴 랜드마크를 감지하고 블렌드 셰이프 점수를 출력하여 사용자와 일치하는 3D 얼굴 모델을 렌더링합니다. MediaPipe Face Landmarker 솔루션을 통해 KDDI와 Google 파트너 혁신팀은 아바타에 사실감을 불어넣었습니다.
KDDI 개발자는 Mediapipe의 강력하고 효율적인 Python 패키지를 사용하여 실시간으로 표정 연기자의 얼굴 특징을 감지하고 52가지 블렌드 셰이프를 추출할 수 있었습니다.
import mediapipe as mp
from mediapipe.tasks import python as mp_python
MP_TASK_FILE = "face_landmarker_with_blendshapes.task"
class FaceMeshDetector:
def __init__(self):
with open(MP_TASK_FILE, mode="rb") as f:
f_buffer = f.read()
base_options = mp_python.BaseOptions(model_asset_buffer=f_buffer)
options = mp_python.vision.FaceLandmarkerOptions(
base_options=base_options,
output_face_blendshapes=True,
output_facial_transformation_matrixes=True,
running_mode=mp.tasks.vision.RunningMode.LIVE_STREAM,
num_faces=1,
result_callback=self.mp_callback)
self.model = mp_python.vision.FaceLandmarker.create_from_options(
options)
self.landmarks = None
self.blendshapes = None
self.latest_time_ms = 0
def mp_callback(self, mp_result, output_image, timestamp_ms: int):
if len(mp_result.face_landmarks) >= 1 and len(
mp_result.face_blendshapes) >= 1:
self.landmarks = mp_result.face_landmarks[0]
self.blendshapes = [b.score for b in mp_result.face_blendshapes[0]]
def update(self, frame):
t_ms = int(time.time() * 1000)
if t_ms <= self.latest_time_ms:
return
frame_mp = mp.Image(image_format=mp.ImageFormat.SRGB, data=frame)
self.model.detect_async(frame_mp, t_ms)
self.latest_time_ms = t_ms
def get_results(self):
return self.landmarks, self.blendshapesFirebase 실시간 데이터베이스는 52개의 블렌드 셰이프 부동 소수점 값 컬렉션을 저장합니다. 각 행은 순서대로 나열되는 특정 블렌드 셰이프에 해당합니다.
_neutral,
browDownLeft,
browDownRight,
browInnerUp,
browOuterUpLeft,
...이러한 블렌드 셰이프 값은 카메라가 열리고 FaceMesh 모델이 실행됨에 따라 실시간으로 계속 업데이트됩니다. 각 프레임에서 데이터베이스는 최신 블렌드 셰이프 값을 반영하여 FaceMesh 모델에서 감지된 얼굴 표정의 동적 변화를 캡처합니다.
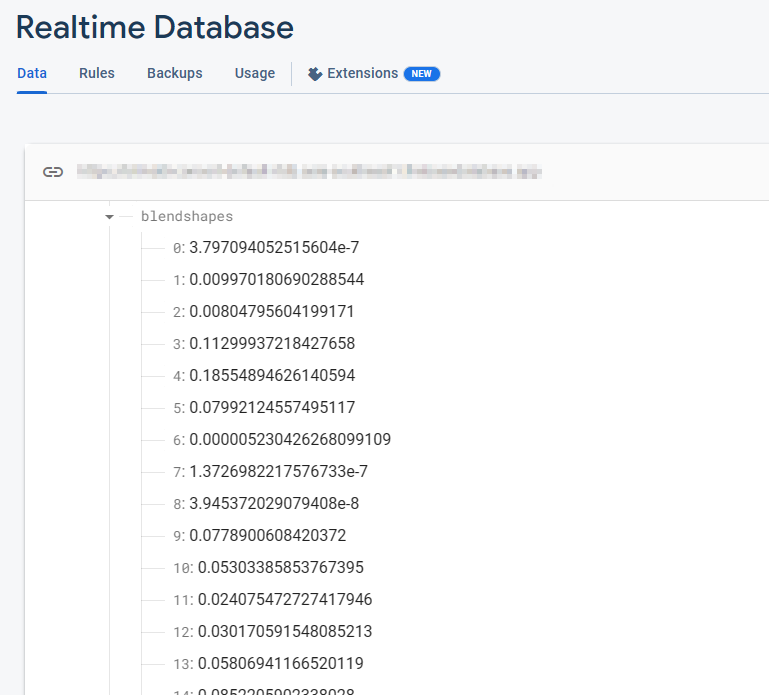
블렌드 셰이프 데이터를 추출한 후 다음 단계는 추출한 데이터를 Firebase 실시간 데이터베이스로 전송하는 것입니다. 이 고급 데이터베이스 시스템을 활용하면 클라이언트에 대한 실시간 데이터의 원활한 흐름이 보장되어 서버 확장성에 대한 우려를 없애고 KDDI가 간소화된 사용자 경험을 제공하는 데 집중할 수 있습니다.
import concurrent.futures
import time
import cv2
import firebase_admin
import mediapipe as mp
import numpy as np
from firebase_admin import credentials, db
pool = concurrent.futures.ThreadPoolExecutor(max_workers=4)
cred = credentials.Certificate('your-certificate.json')
firebase_admin.initialize_app(
cred, {
'databaseURL': 'https://your-project.firebasedatabase.app/'
})
ref = db.reference('projects/1234/blendshapes')
def main():
facemesh_detector = FaceMeshDetector()
cap = cv2.VideoCapture(0)
while True:
ret, frame = cap.read()
facemesh_detector.update(frame)
landmarks, blendshapes = facemesh_detector.get_results()
if (landmarks is None) or (blendshapes is None):
continue
blendshapes_dict = {k: v for k, v in enumerate(blendshapes)}
exe = pool.submit(ref.set, blendshapes_dict)
cv2.imshow('frame', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
exit()계속 진행하기 위해 개발자는 Firebase 실시간 데이터베이스에서 Google Cloud의 Immersive Stream for XR 인스턴스로 블렌드 셰이프 데이터를 실시간으로 원활하게 전송합니다. Google Cloud의 Immersive Stream for XR은 클라우드에서 Unreal Engine 프로젝트를 실행하고, 실시간으로 몰입감 있는 사실적 3D 및 증강 현실(AR) 경험을 렌더링하여 스마트폰과 브라우저에 스트리밍하는 관리형 서비스입니다.
이와 같은 통합을 통해 KDDI는 캐릭터 얼굴 애니메이션을 구동하고 지연 시간을 최소화하면서 얼굴 애니메이션의 실시간 스트리밍을 실현하여 몰입감 있는 사용자 경험을 보장할 수 있습니다.
Immersive Stream for XR에서 실행하는 Unreal Engine 측에서는 Firebase C++ SDK를 사용하여 Firebase에서 데이터를 원활하게 수신합니다. 데이터베이스 리스너를 설정하면 Firebase 실시간 데이터베이스 테이블에서 업데이트가 발생하는 즉시 블렌드 셰이프 값을 바로 검색할 수 있습니다. 이러한 통합을 통해 최신 블렌드 셰이프 데이터에 실시간으로 액세스하여 Unreal Engine 프로젝트에서 역동적인 반응형 얼굴 애니메이션을 구현할 수 있습니다.
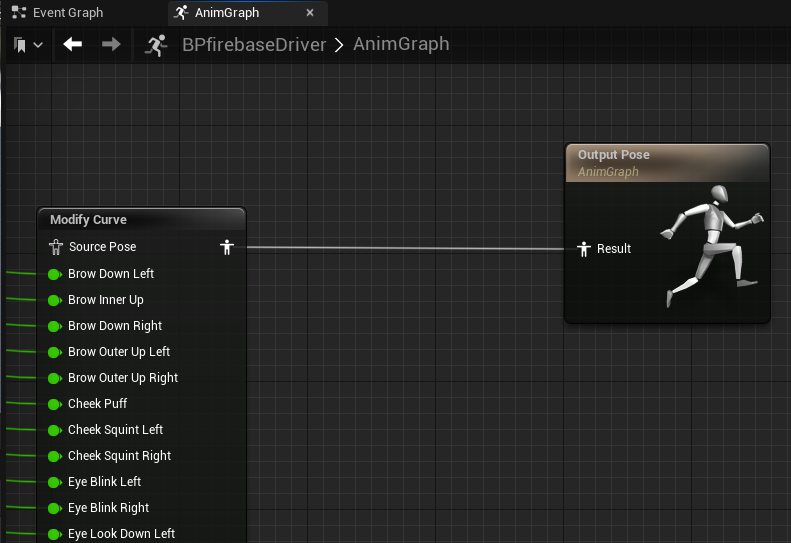
Firebase SDK에서 블렌드 셰이프 값을 검색한 후 애니메이션 청사진에서 'Modify Curve' 노드를 사용하면 Unreal Engine에서 얼굴 애니메이션을 구동할 수 있습니다. 각 블렌드 셰이프 값은 모든 프레임에서 개별적으로 캐릭터에 할당되므로 캐릭터의 얼굴 표정을 실시간으로 정밀하게 제어할 수 있습니다.
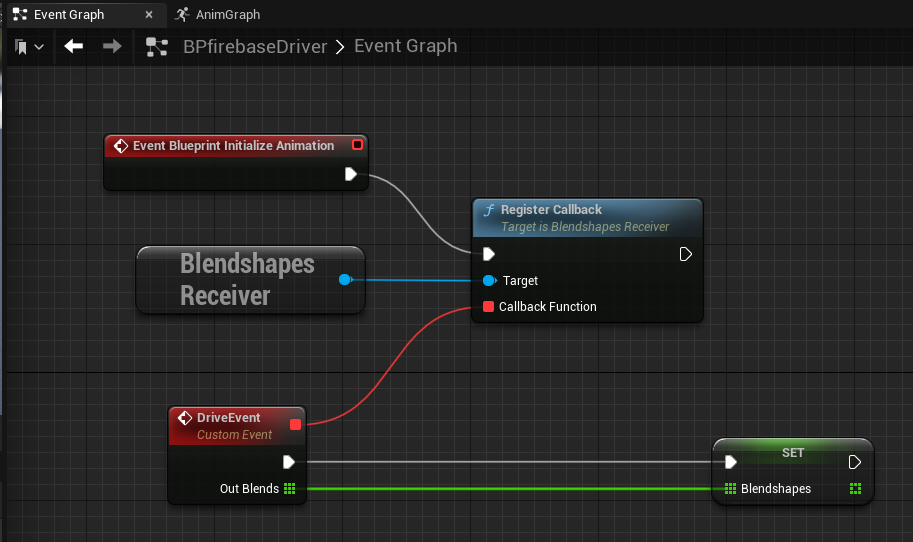
Unreal Engine에서 실시간 데이터베이스 리스너를 구현하기 위한 효과적인 접근 방식은 대체 싱글톤 패턴으로 사용되는 GameInstance Subsystem을 활용하는 것입니다. 이를 통해 백그라운드에서 데이터베이스 연결, 인증 및 연속 데이터 수신을 처리하는 전용 BlendshapesReceiver 인스턴스를 생성할 수 있습니다.
GameInstance Subsystem을 활용하여 BlendshapesReceiver 인스턴스를 인스턴스화하고 게임 세션의 수명 기간 동안 유지 관리할 수 있습니다. 이를 통해 애니메이션 청사진이 수신된 블렌드 셰이프 데이터를 사용하여 얼굴 애니메이션을 읽고 구동하는 동안 데이터베이스 연결이 지속되도록 합니다.
KDDI는 MediaPipe를 실행하는 로컬 PC만 사용하여 실제 연기자의 얼굴 표정과 움직임을 캡처하는 데 성공하고 고품질의 3D 리타게팅 애니메이션을 실시간으로 생성했습니다.
KDDI는 Adastria Co., Ltd.와 같은 메타버스 애니메이션 패션 분야 개발자와 협력하고 있습니다.
자세히 알아보려면 Google I/O 2023 세션 Easy on-device ML with MediaPipe(MediaPipe를 사용하는 간편한 온디바이스 ML), Supercharge your web app with machine learning and MediaPipe(머신러닝과 MediaPipe를 사용한 웹 앱 강화), What's new in machine learning(머신러닝의 새로운 기능)을 시청하고 developers.google.com/mediapipe에서 공식 문서를 확인해 보세요.
이러한 MediaPipe 통합은 KDDI가 실제 세계와 가상 세계 사이의 경계를 허물어서 사용자가 언제 어디서나 라이브 음악 공연에 참석하고, 예술 작품을 감상하고, 친구와 대화하고, 쇼핑하는 등의 일상적인 경험을 누릴 수 있도록 하는 방법을 보여주는 한 예입니다.
KDDI의 αU는 메타버스, 라이브 스트리밍, 가상 쇼핑 등 Web3 시대를 위한 서비스를 제공하여, 누구나 크리에이터가 될 수 있는 생태계를 조성하고 실제 세계와 가상 세계를 쉽게 오가는 차세대 사용자를 지원합니다.



