

The last few months have been an exciting time for the Gemma family of open models. We introduced Gemma 3 and Gemma 3 QAT, delivering state-of-the-art performance for single cloud and desktop accelerators. Then, we announced the full release of Gemma 3n, a mobile-first architecture bringing powerful, real-time multimodal AI directly to edge devices. Our goal has been to provide useful tools for developers to build with AI, and we continue to be amazed by the vibrant Gemmaverse you are helping create, celebrating together as downloads surpassed 200 million last week.
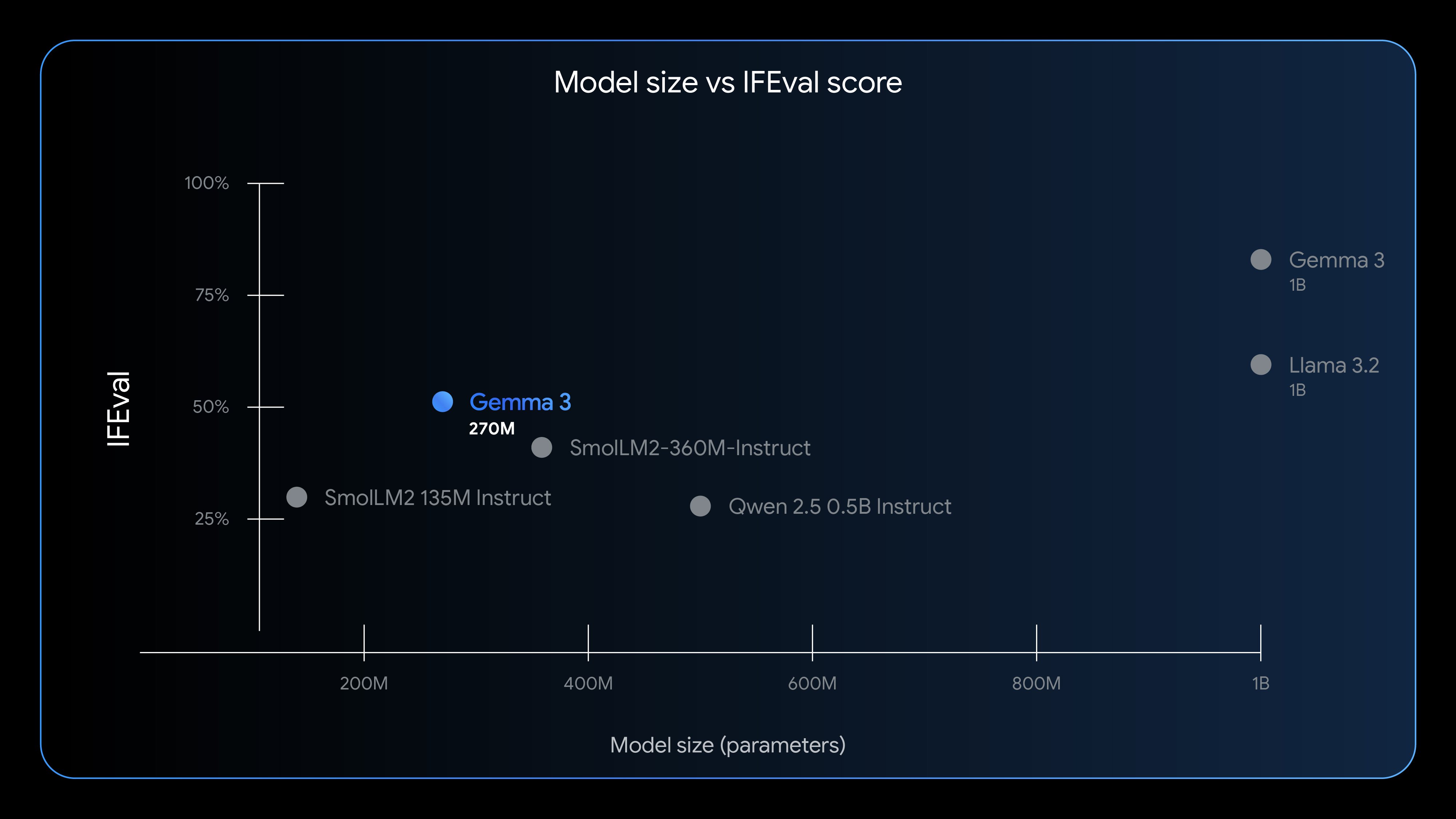
Today, we're adding a new, highly specialized tool to the Gemma 3 toolkit: Gemma 3 270M, a compact, 270-million parameter model designed from the ground up for task-specific fine-tuning with strong instruction-following and text structuring capabilities already trained in.
In engineering, success is defined by efficiency, not just raw power. You wouldn't use a sledgehammer to hang a picture frame. The same principle applies to building with AI.
Gemma 3 270M embodies this "right tool for the job" philosophy. It's a high-quality foundation model that follows instructions well out of the box, and its true power is unlocked through fine-tuning. Once specialized, it can execute tasks like text classification and data extraction with remarkable accuracy, speed, and cost-effectiveness. By starting with a compact, capable model, you can build production systems that are lean, fast, and dramatically cheaper to operate.
The power of this approach has already delivered incredible results in the real world. A perfect example is the work done by Adaptive ML with SK Telecom. Facing the challenge of nuanced, multilingual content moderation, they chose to specialize. Instead of using a massive, general-purpose model, Adaptive ML fine-tuned a Gemma 3 4B model. The results were stunning: the specialized Gemma model not only met but exceeded the performance of much larger proprietary models on its specific task.
Gemma 3 270M is designed to let developers take this approach even further, unlocking even greater efficiency for well-defined tasks. It's the perfect starting point for creating a fleet of small, specialized models, each an expert at its own task.
But this power of specialization isn't just for enterprise tasks; it also enables powerful creative applications. For example, check out this Bedtime Story Generator web app:
Link to Youtube Video (visible only when JS is disabled)
Gemma 3 270M inherits the advanced architecture and robust pre-training of the Gemma 3 collection, providing a solid foundation for your custom applications.
Here’s when it’s the perfect choice:
We want to make it as easy as possible to turn Gemma 3 270M into your own custom solution. It’s built on the same architecture as the rest of the Gemma 3 models, with recipes and tools to get you started quickly. You can find our guide on full fine-tuning using Gemma 3 270M as part of the Gemma docs.
The Gemmaverse is built on the idea that innovation comes in all sizes. With Gemma 3 270M, we’re empowering developers to build smarter, faster, and more efficient AI solutions. We can’t wait to see the specialized models you create.

Introducing EmbeddingGemma: The Best-in-Class Open Model for On-Device Embeddings
Unlocking Peak Performance on Qualcomm NPU with LiteRT

Architecting efficient context-aware multi-agent framework for production

T5Gemma: A new collection of encoder-decoder Gemma models

Announcing the Data Commons Gemini CLI extension