

We are excited to announce Google AI Edge Torch - a direct path from PyTorch to the TensorFlow Lite (TFLite) runtime with great model coverage and CPU performance. TFLite already works with models written in Jax, Keras, and TensorFlow, and we are now adding PyTorch as part of a wider commitment to framework optionality.
This new offering is now available as part of Google AI Edge, a suite of tools with easy access to ready-to-use ML tasks, frameworks that enable you to build ML pipelines, and run popular LLMs and custom models – all on-device. This is the first of a series of blog posts covering Google AI Edge releases that will help developers build AI enabled features, and easily deploy them on multiple platforms.
AI Edge Torch is released in Beta today featuring:
Google AI Edge Torch was built from the ground up to provide a great experience to the PyTorch community, with APIs that feel native, and provide an easy conversion path.
import torchvision
import ai_edge_torch
# Initialize model
resnet18 = torchvision.models.resnet18().eval()
# Convert
sample_input = (torch.randn(4, 3, 224, 224),)
edge_model = ai_edge_torch.convert(resnet18, sample_input)
# Inference in Python
output = edge_model(*sample_input)
# Export to a TfLite model for on-device deployment
edge_model.export('resnet.tflite'))Under the hood, ai_edge_torch.convert() is integrated with TorchDynamo using torch.export - which is the PyTorch 2.x way to export PyTorch models into standardized model representations intended to be run on different environments. Our current implementation supports more than 60% of core_aten operators, which we plan to increase significantly as we build towards a 1.0 release of ai_edge_torch. We’ve included examples showing PT2E quantization, the quantization approach native to PyTorch2, to enable easy quantization workflows. We’re excited to hear from the PyTorch community to find ways to improve developer experience when bringing innovation that starts in PyTorch to a wide set of devices.
Prior to this release, many developers were using community provided paths such as ONNX2TF to enable PyTorch models on TFLite. Our goal in developing AI Edge Torch was to reduce developer friction, provide great model coverage, and to continue our mission of delivering best in class performance on Android devices.
On coverage, our tests demonstrate significant improvements over the defined set of models over existing workflows, particularly ONNX2TF
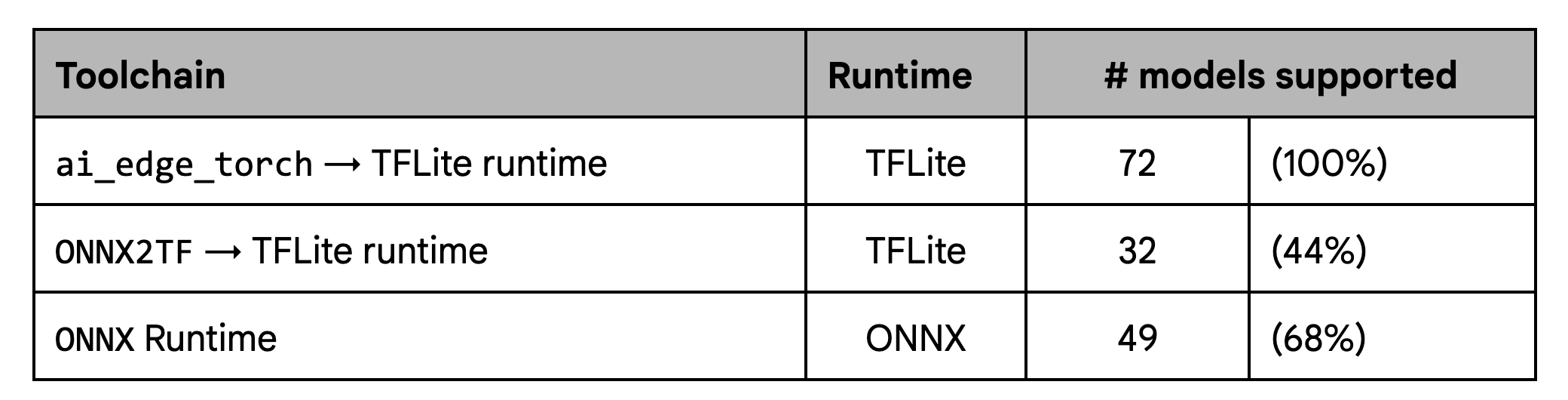
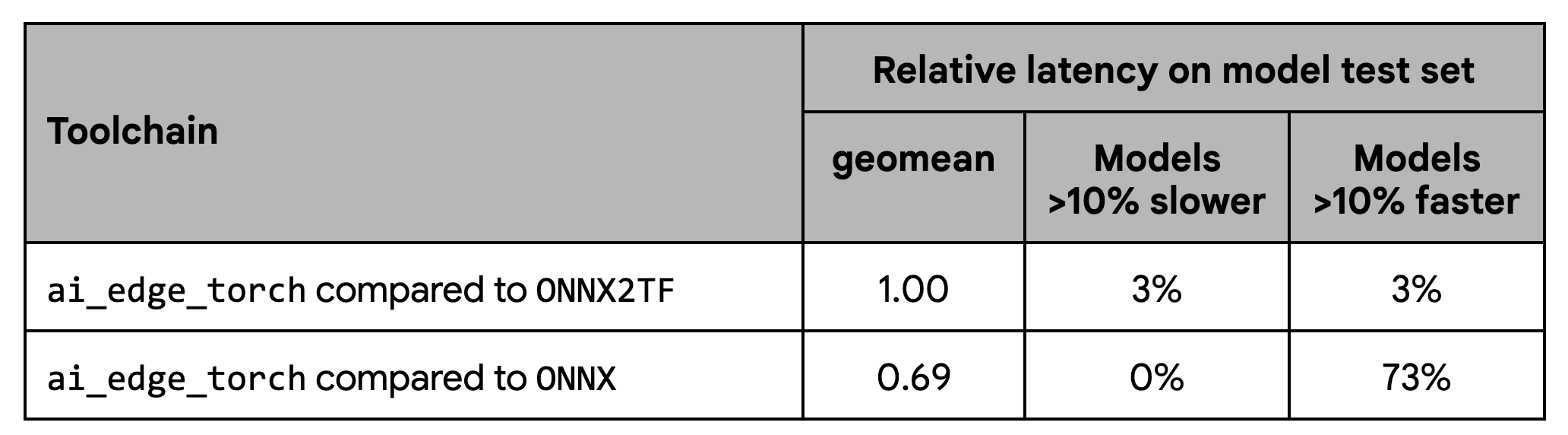
On performance, our tests show consistent performance with ONNX2TF baseline, while also showing meaningfully better performance than the ONNX runtime:
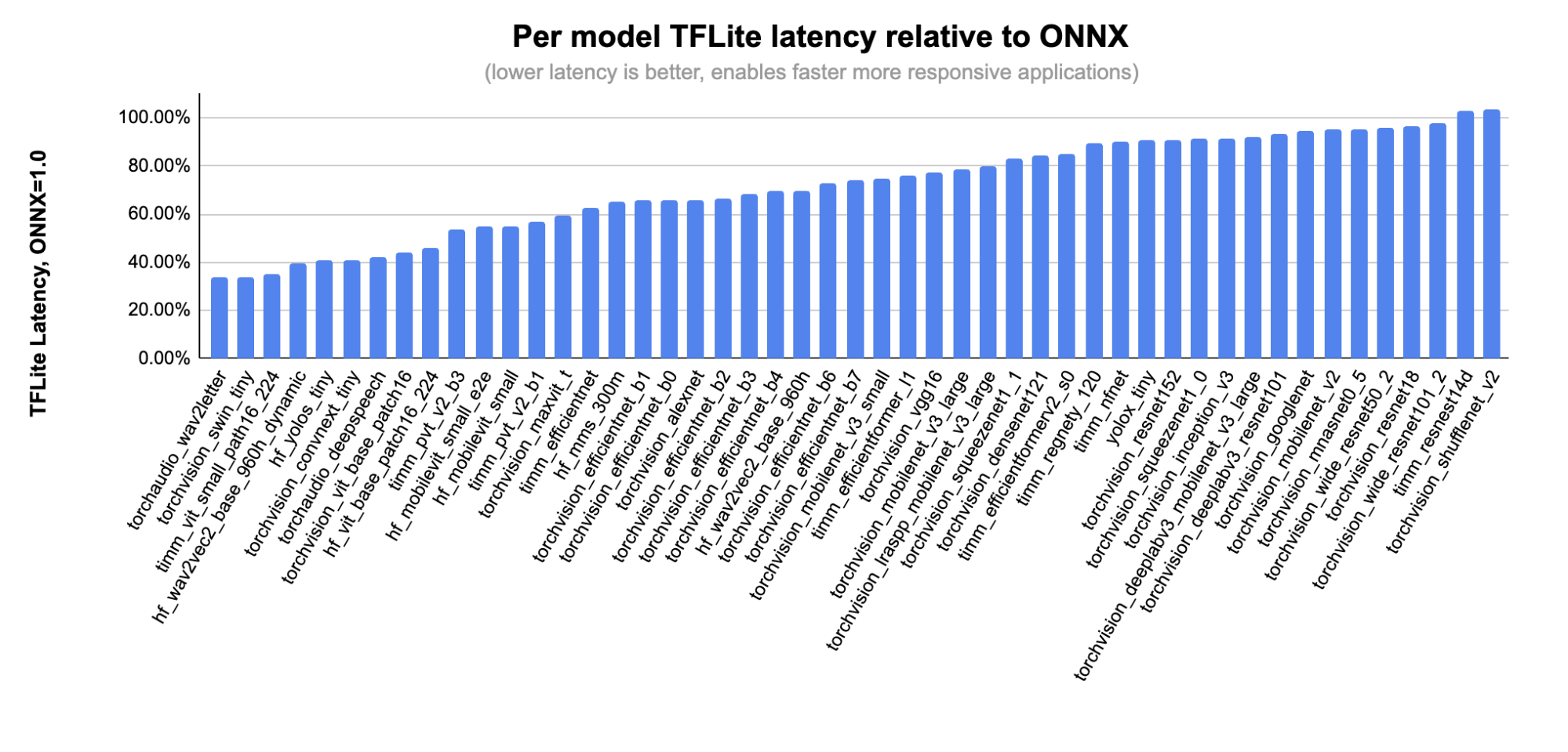
This shows detailed per-model performance on the subset of the models covered by ONNX:
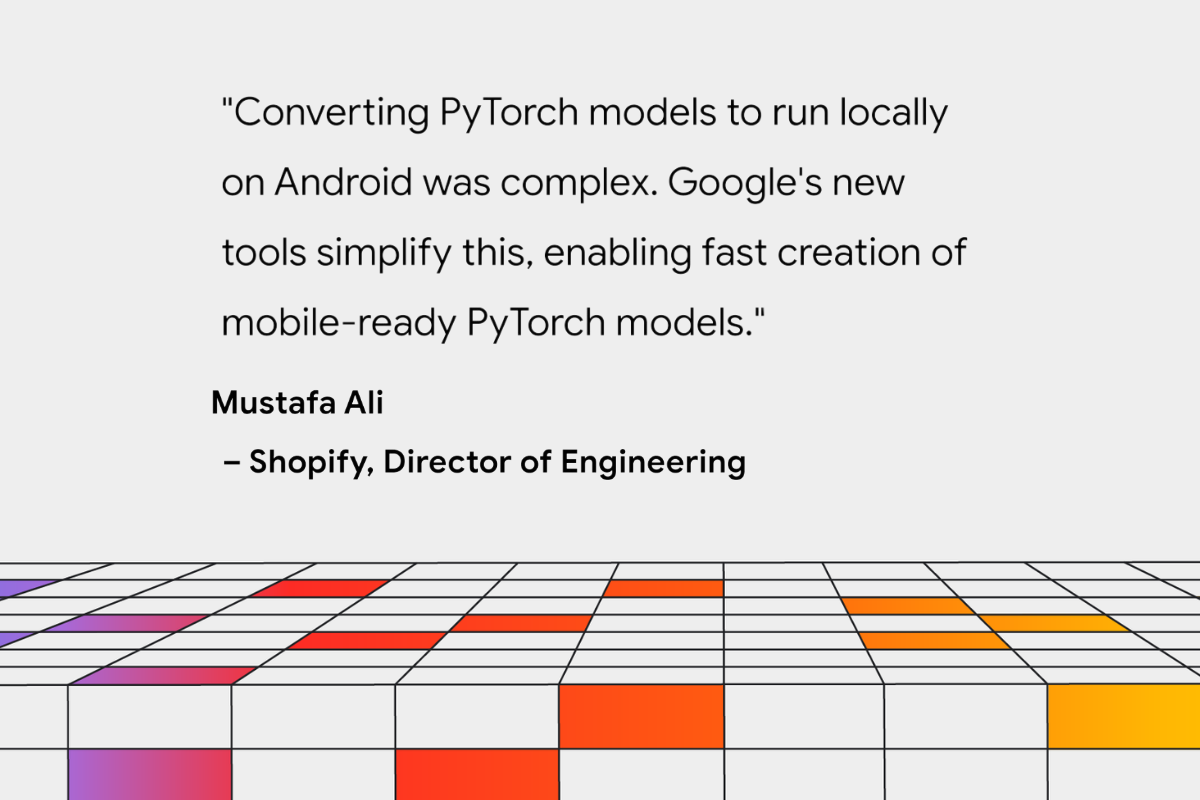
In the last few months, we have worked closely with early adoption partners including Shopify, Adobe, and Niantic to improve our PyTorch support. ai_edge_torch is already being used by the team at Shopify to perform on-device background removal for product images and will be available in an upcoming release of the Shopify app.
We’ve also worked closely with partners to work on hardware support across CPUs, GPUs and accelerators - this includes Arm, Google Tensor G3, MediaTek, Qualcomm and Samsung System LSI. Through these partnerships, we improved performance and coverage, and have validated PyTorch generated TFLite files on accelerator delegates.
We are also thrilled to co-announce Qualcomm’s new TensorFlow Lite delegate, which is now openly available here for any developer to use. TFLite Delegates are add-on software modules that help accelerate execution on GPUs and hardware accelerators. This new QNN delegate supports most models in our PyTorch Beta test set, while providing support for a wide set of Qualcomm silicon, and gives significant average speedups relative to CPU(20x) and GPU(5x) by utilizing Qualcomm’s DSP and neural processing units. To make it easy to test out, Qualcomm has also recently released their new AI Hub. The Qualcomm AI Hub is a cloud service that enables developers to test TFLite models against a wide device pool of Android devices, and provides visibility of performance gains available on different devices using the QNN delegate.
In the coming months we will continue to iterate in the open, with releases expanding model coverage, improving GPU support, and enabling new quantization modes as we build to a 1.0 release. In part 2 of this series, we’ll take a deeper look at the AI Edge Torch Generative API, which enables developers to bring custom GenAI models to the edge with great performance.
We’d like to thank all of our early access customers for their valuable feedback that helped us catch early bugs and ensure a smooth developer experience. We’d also like to thank hardware partners, and ecosystem contributors to XNNPACK that have helped us improve performance across a wide range of devices. We would also like to thank the wider Pytorch community for their guidance and support.
Acknowledgements
We’d like to thank all team members who contributed to this work: Aaron Karp, Advait Jain, Akshat Sharma, Alan Kelly, Arian Arfaian, Chun-nien Chan, Chuo-Ling Chang, Claudio Basille, Cormac Brick, Dwarak Rajagopal, Eric Yang, Gunhyun Park, Han Qi, Haoliang Zhang, Jing Jin, Juhyun Lee, Jun Jiang, Kevin Gleason, Khanh LeViet, Kris Tonthat, Kristen Wright, Lu Wang, Luke Boyer, Majid Dadashi, Maria Lyubimtseva, Mark Sherwood, Matthew Soulanille, Matthias Grundmann, Meghna Johar, Michael Levesque-Dion, Milad Mohammadi, Na Li, Paul Ruiz, Pauline Sho, Ping Yu, Pulkit Bhuwalka, Ram Iyengar, Sachin Kotwani, Sandeep Dasgupta, Sharbani Roy, Shauheen Zahirazami, Siyuan Liu, Vamsi Manchala, Vitalii Dziuba, Weiyi Wang, Wonjoo Lee, Yishuang Pang, Zoe Wang, and the StableHLO team.
On-Device Function Calling in Google AI Edge Gallery

Announcing ADK for Java 1.0.0: Building the Future of AI Agents in Java

LiteRT: Maximum performance, simplified

On-device small language models with multimodality, RAG, and Function Calling

Jump to play: Building with Gemini & MediaPipe

ADK Go 1.0 Arrives!