

[Image created by Google with Gemini 2.0 Flash native image generation]
Today, we’re making a new experimental Gemini Embedding text model (gemini-embedding-exp-03-07)1 available in the Gemini API.
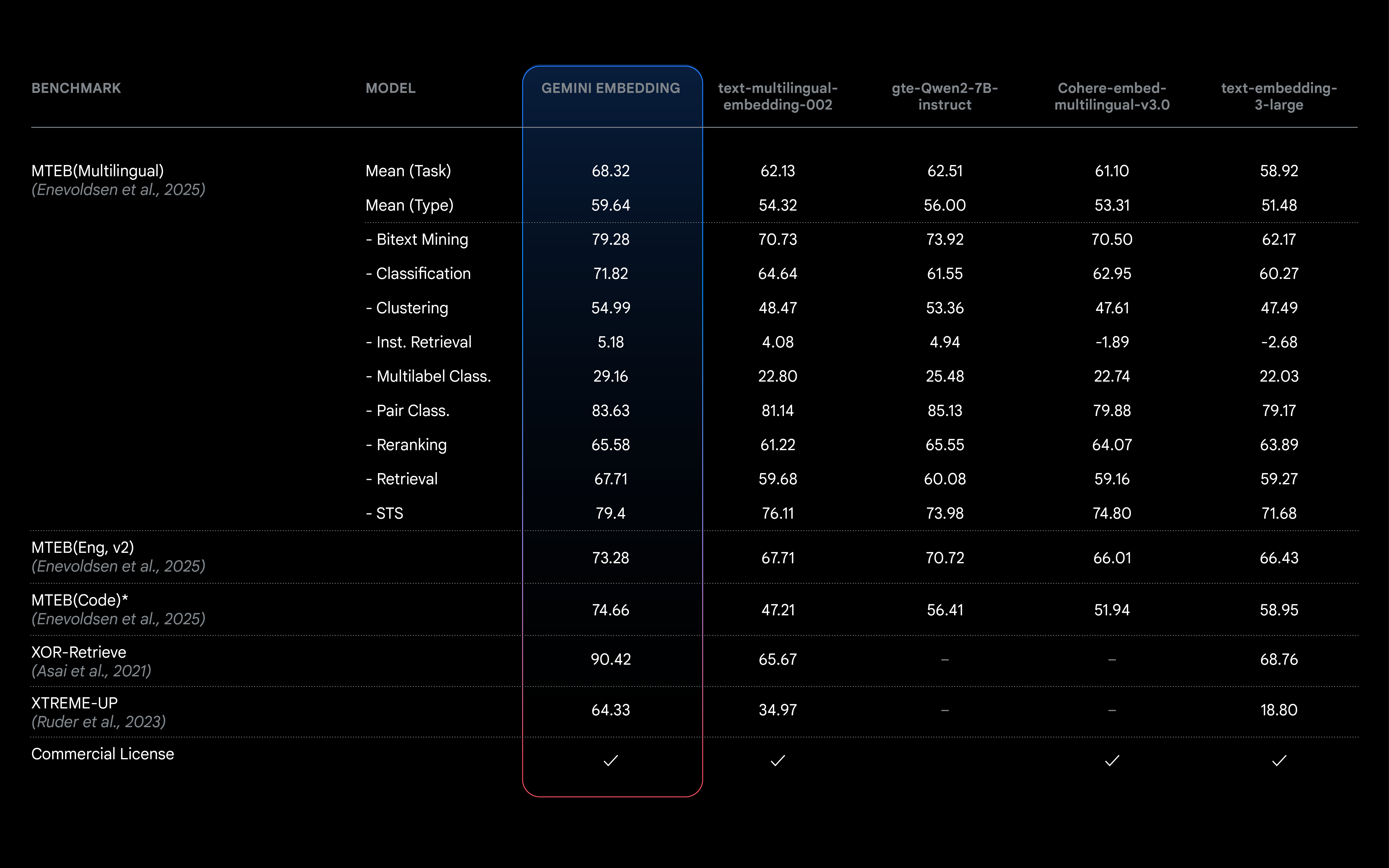
Trained on the Gemini model itself, this embedding model has inherited Gemini’s understanding of language and nuanced context making it applicable for a wide range of uses. This new embedding model surpasses our previous state-of-the-art model (text-embedding-004), achieves the top rank on the Massive Text Embedding Benchmark (MTEB) Multilingual leaderboard, and comes with new features like longer input token length!
We've trained our model to be remarkably general, delivering exceptional performance across diverse domains, including finance, science, legal, search, and more. It works effectively out-of-the-box, eliminating the need for extensive fine-tuning for specific tasks.
The MTEB (Multilingual) leaderboard ranks text embedding models across diverse tasks such as retrieval and classification to provide a comprehensive benchmark for model comparison. Our Gemini Embedding model achieves a mean (task) score of 68.32–a margin of +5.81 over the next competing model.
From building intelligent retrieval augmented generation (RAG) and recommendation systems to text classification, the ability for LLMs to understand the meaning behind text is crucial. Embeddings are often critical for building more efficient systems, reducing cost and latency while also generally providing better results than keyword matching systems. Embeddings capture semantic meaning and context through numerical representations of data. Data with similar semantic meaning have embeddings that are closer together. Embeddings enable a wide range of applications, including:
You can learn more about embeddings and common AI use cases in the Gemini API docs.
Developers can now access our new, experimental Gemini Embeddings model through the Gemini API. It’s compatible with the existing embed_content endpoint.
from google import genai
client = genai.Client(api_key="GEMINI_API_KEY")
result = client.models.embed_content(
model="gemini-embedding-exp-03-07",
contents="How does alphafold work?",
)
print(result.embeddings)
In addition to improved quality across all dimensions, Gemini Embedding also features:
While currently in an experimental phase with limited capacity, this release gives you an early opportunity to explore Gemini Embedding capabilities. As with all experimental models, it's subject to change, and we're working towards a stable, generally available release in the months to come. We’d love to hear your feedback on the embeddings feedback form.
1 On Vertex AI, the same model is served through the endpoint “text-embedding-large-exp-03-07.” For general availability, naming will be consistent.

CalCam: Transforming Food Tracking with the Gemini API
Start building with Gemini 2.0 Flash and Flash-Lite

Presentamos PaliGemma 2 Mix: un modelo de lenguaje-visión para varias tareas

Gemini 2.0 Deep Dive: Code Execution