
Today we are excited to share updates across the board to our Gemini 2.5 model family:
Gemini 2.5 models are thinking models, capable of reasoning through their thoughts before responding, resulting in enhanced performance and improved accuracy. Each model has control over the thinking budget, giving developers the ability to choose when and how much the model “thinks” before generating a response.
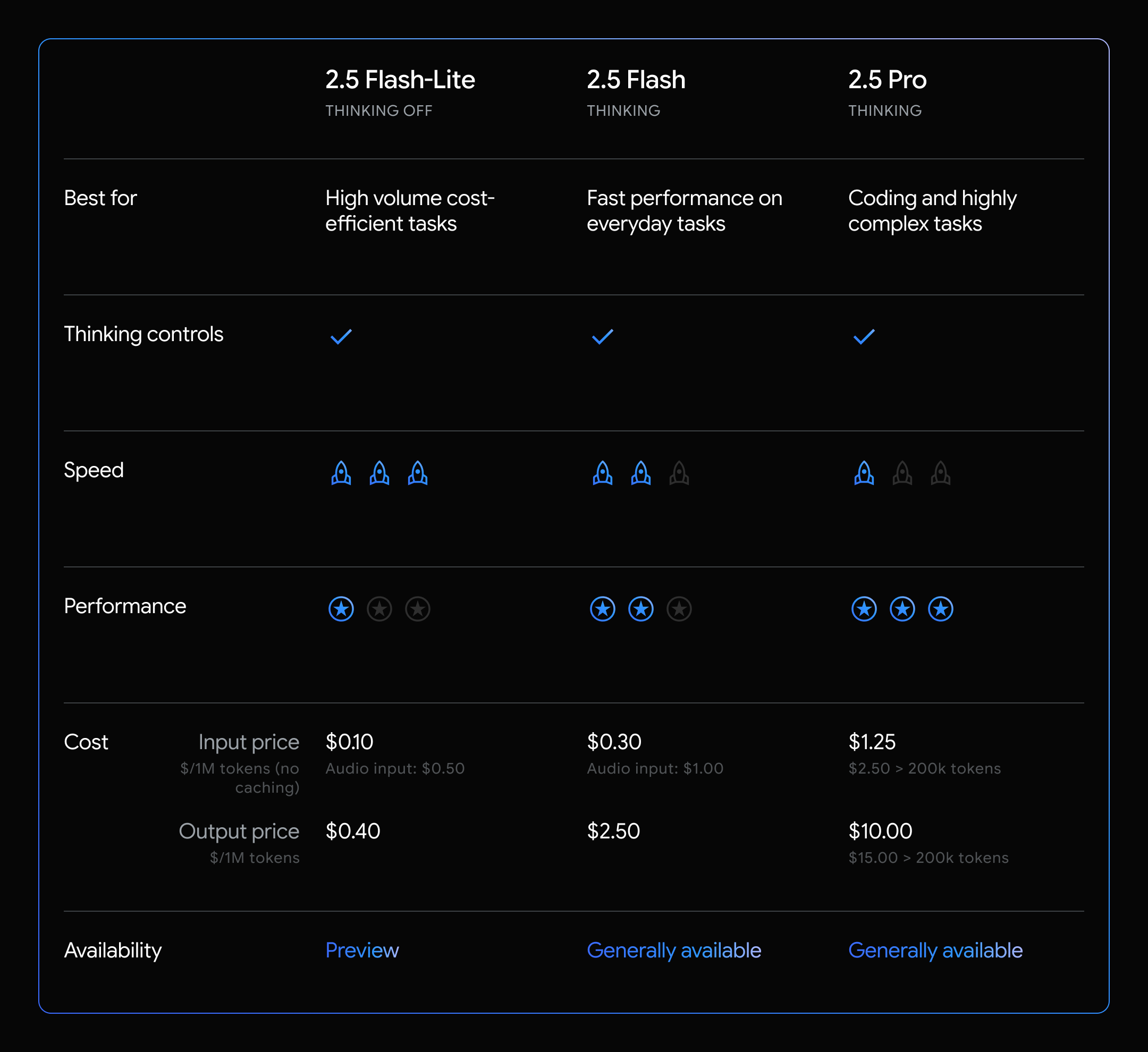
Today, we’re introducing 2.5 Flash-Lite in preview with the lowest latency and cost in the 2.5 model family. It’s designed as a cost-effective upgrade from our previous 1.5 and 2.0 Flash models. It also offers better performance across most evals, and lower time to first token while also achieving higher tokens per second decode. This model is great for high throughput tasks like classification or summarization at scale.
Gemini 2.5 Flash-Lite is a reasoning model, which allows for dynamic control of the thinking budget with an API parameter. Because Flash-Lite is optimized for cost and speed, “thinking” is off by default, unlike our other models. 2.5 Flash-Lite also supports all of our native tools like Grounding with Google Search, Code Execution, and URL Context in addition to function calling.
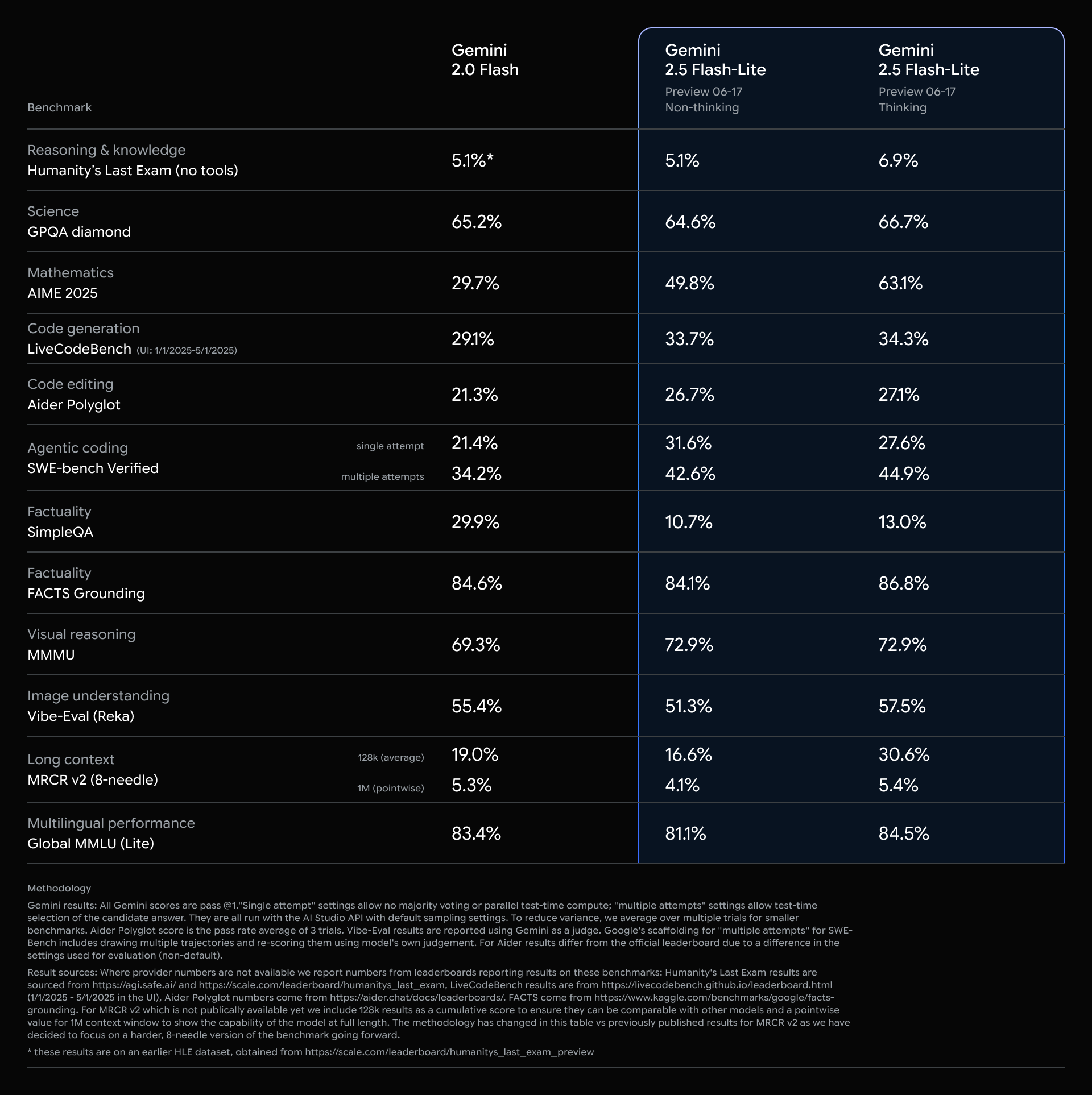
Over the last year, our research teams have continued to push the pareto frontier with our Flash model series. When 2.5 Flash was initially announced, we had not yet finalized the capabilities for 2.5 Flash-Lite. We also launched with a “thinking” and “non-thinking price”, which led to developer confusion.
With the stable version of Gemini 2.5 Flash rolling out (which is the same 05-20 model preview we made available at Google I/O), and the incredible performance of 2.5 Flash, we are updating the pricing for 2.5 Flash:
While we strive to maintain consistent pricing between preview and stable releases to minimize disruption, this is a specific adjustment reflecting Flash’s exceptional value, still offering the best cost-per-intelligence available.
And with Gemini 2.5 Flash-Lite, we now have an even lower cost option (with or without thinking) for cost and latency sensitive use cases that require less model intelligence.

If you are using the Gemini 2.5 Flash Preview 04-17 , the existing preview pricing will remain in effect until its planned deprecation on July 15, 2025, at which point that model endpoint will be turned off. You can transition to the generally available model “gemini-2.5-flash”, or switch to 2.5 Flash-Lite Preview as a lower cost option.
The growth and demand for Gemini 2.5 Pro continues to be the steepest of any of our models we have ever seen. To allow more customers to build on this model in production, we are making the 06-05 version of the model stable, with the same pareto frontier price point as before.
We expect that cases where you need the highest intelligence and most capabilities are where you will see Pro shine, like coding and agentic tasks. Gemini 2.5 Pro is at the heart of many of the most loved developer tools.

If you are using 2.5 Pro Preview 05-06, the model will remain available until June 19, 2025 and then will be turned off. If you are using 2.5 Pro Preview 06-05, you can simply update your model string to “gemini-2.5-pro”.
We can’t wait to see even more domains benefit from the intelligence of 2.5 Pro and look forward to sharing more about scaling beyond Pro in the near future.

Introducing Gemini 2.5 Flash Image, our state-of-the-art image model
Unlocking Peak Performance on Qualcomm NPU with LiteRT

Architecting efficient context-aware multi-agent framework for production

Beyond the terminal: Gemini CLI comes to Zed

Announcing the Data Commons Gemini CLI extension