
Following the announcement in our launch blog, we are releasing Gemma 4 12B, a dense multimodal model with a unified, encoder-free architecture.
Gemma 4 12B introduces several milestones for local AI:
Traditional multimodal models rely on frozen, separate vision encoders (e.g., Gemma 4 uses a 150M parameter vision model for edge sizes and 550M for medium-sized models) and audio encoders (300M parameters for Gemma 4 E2B and E4B). Processing multimodal inputs with multiple separate encoders before feeding them to the LLM leads to increased latency and fragmented memory footprints.
Gemma 4 12B solves these issues by utilizing a single decoder-only transformer containing the same advanced decoder structure as the Gemma 4 31B Dense model.
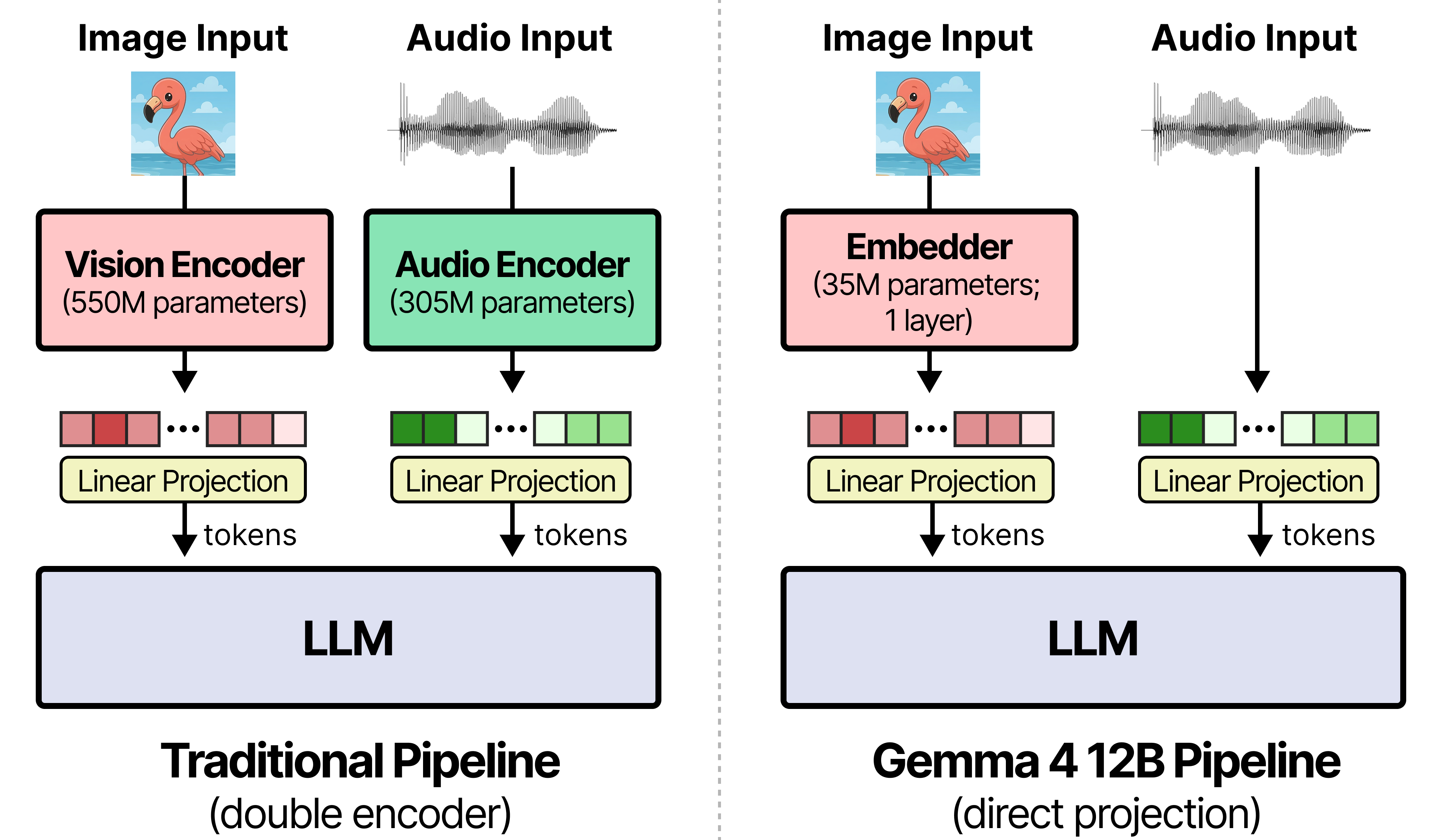
For a more in-depth overview of how this encoder-free architecture works, check out A Visual Guide to Gemma 4 12B.
Gemma 4 12B achieves outstanding performance, with capabilities such as automatic speech recognition, agentic reasoning, diarization, video understanding, coding, and more.
See below examples for a demonstration of the model's agentic and multimodal capabilities:
Thanks to its agentic and multimodal understanding capabilities, Gemma 4 12B can be easily used with existing agent harnesses like OpenCode. In this example, we served it locally using llama.cpp using the gemma-skills to code a Gradio app that helped the user process images. This app was powered by the same Gemma 4 12B model that built it!
We used Gemma 4 12B to analyse a part from the Google IO Keynote moment from May 19, specifically the 5 minutes between 00:15:32 and 00:20:45. To do that, we extracted all the frames of that segment (at 1 FPS), plus the prompt and the audio from the video:
Link to Youtube Video (visible only when JS is disabled)
Prompt:
"what happens when the man takes a selfie?"When the man takes a "selfie" or is shown holding a smartphone in front of his face in these demonstration videos, it is a clever way to visually represent how the AI models can take existing media—like a personal photo or a video clip—and "reimagine" it. In these specific clips, the model is taking a selfie and using it as a base to generate various scenarios (like a person in a space station, or walking through a forest).
Essentially, the man is not actually taking a selfie; rather, he is **acting out a visual metaphor for the AI's capability to take one specific input (a "selfie") and generate a whole world of new content based on it.** This is part of the "Swap" and "Build worlds" demonstrations of the Gemini Omni model, showing its ability to perform complex, multi-modal reasoning and creative generation.
In tandem with the Gemma 4 12B launch, we are officially introducing powerful on-device developer integrations powered by LiteRT-LM, bringing zero-latency local AI execution natively to standard desktop environments:
1.Native MacOS Apps: The mobile Google AI Edge Gallery is officially expanding to desktop platforms, running Gemma 4 12B offline, natively on Apple Silicon GPUs. It comes with a secure sandboxed Python execution loop to write, execute, and plot scientific charts inside the chat bubble. In parallel, the Google AI Edge Eloquent app on Mac launches support for Gemma 12B to power Voice Edit conversational inputs.
2. Drop-in Local API Servers (litert-lm serve): Run Gemma 4 12B as a local, OpenAI-compatible API server using the new litert-lm serve CLI command. Seamlessly connect standard integrations (e.g., Continue, Aider, OpenClaw, Hermes or OpenCode), leveraging stateless prefix caching in memory to match context history and instantly bypass prefill latency.
litert-lm import --from-huggingface-repo=litert-community/gemma-4-12B-it-litert-lm gemma-4-12B-it.litertlm gemma4-12b
# Start the OpenAI-compatible server
litert-lm serveFind a deep dive about it on the Google AI Edge Gallery blog.
Ready to build local multimodal agents with the first encoder-free architecture of the Gemma family? Here is how you can jump in today


