Following our announcement in our launch blog post, we are sharing this developer guide to help you understand, serve and customize this experimental model.
Built on the Gemma 4 backbone, DiffusionGemma introduces several milestones for developer workflows:
Compute-bound parallel generation: Bypasses memory-bandwidth limitations by shifting the bottleneck to compute, delivering up to 4x faster token generation on GPUs (up to 700+ tokens per second on NVIDIA GeForce RTX 5090 and 1000+ tokens per second on a single NVIDIA H100).
Bidirectional context & self-correction: Uses bidirectional attention to evaluate the entire text block simultaneously during generation, enabling real-time error correction and parallel context propagation.
Developer-friendly sizes: Designed as a 26B Mixture of Experts (MoE) model that activates only 3.8B parameters during inference, allowing quantized deployment within 18 GB VRAM limits.
The Architecture
For developers building with traditional LLMs on GPUs, the primary bottleneck is memory bandwidth. Autoregressive language models must repeatedly load model weights from memory to generate text one token at a time. DiffusionGemma bypasses this limitation by shifting the bottleneck from memory bandwidth to compute, generating and refining a 256-token canvas in parallel. By providing the GPU with a large parallel workload, it utilizes tensor cores that would otherwise sit idle during local serving.
Uniform State Diffusion: Instead of predicting tokens sequentially, DiffusionGemma starts with a canvas of random placeholder tokens and iteratively refines them in parallel. Over multiple denoising passes, highly confident tokens help resolve adjacent positions, causing the entire sequence to snap into focus.
Block Autoregressive Diffusion for Variable Length Generation: For sequences longer than 256 tokens, once a 256-token block is fully denoised, the model processes and commits it to the KV cache. The model then transitions to the next block, initializing a fresh 256-token canvas conditioned on the previously committed history. This combines parallel block speed with the sequential stability of autoregressive models.
Showcase: Solving Sudoku with Parallel Denoising
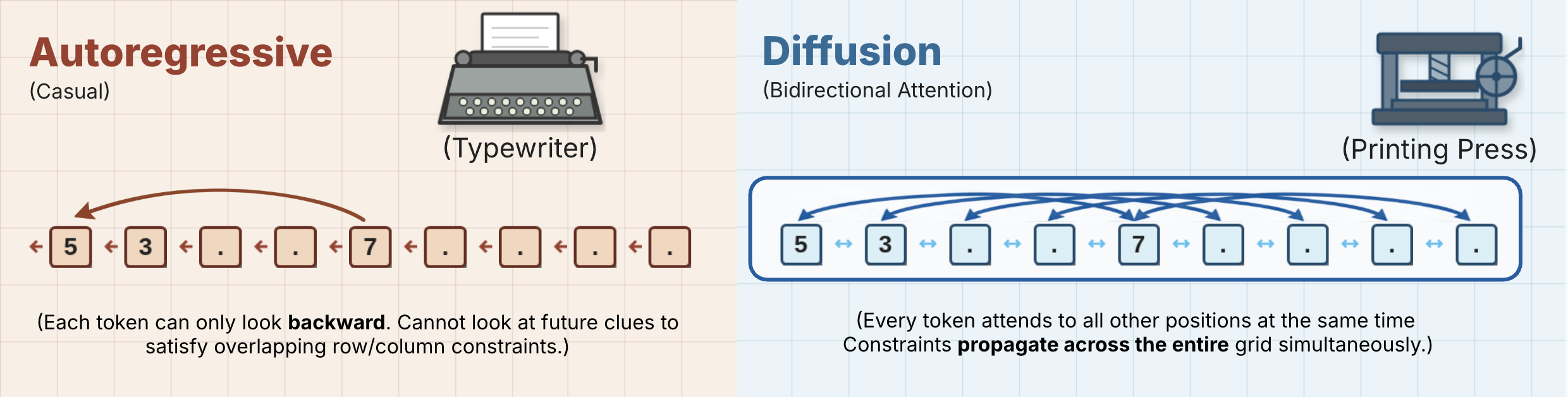
Traditional autoregressive models struggle with strict, multivariable constrained problems like Sudoku. Because they generate text strictly from left to right, they cannot evaluate future placeholders or backtrack.
To demonstrate customization of DiffusionGemma, we are releasing a fine-tuning recipe and results using Hackable Diffusion, a modular JAX research toolbox. This training setup focuses on a classic multi-variable grid task: the Sudoku Solver.
Why Sudoku is Interesting for Diffusion
In an 81-character Sudoku string representation (where empty cells are marked with periods), every digit is bound by strict intersecting horizontal, vertical, and 9x9 grid constraints.
Bidirectional Context Propagation: Unlike autoregressive models, DiffusionGemma’s denoising step allows every canvas query to attend to all positions in parallel. Information flows symmetrically across the board, resolving global dependencies in each step.
Error Correction via Re-Noising: Under Uniform State Diffusion, the model evaluates the entire board simultaneously. If confidence drops, the sampler replaces digits with random ones, allowing for continuous self-correction.
Efficient Early Stopping: Fine-tuning on Sudoku shows that adapters enhance early stopping. The SFT-tuned model stabilizes faster than the base model, allowing the engine to halt sooner, reducing latency and compute costs.
Left: DiffusionGemma generating Sudoku output. The base model is unable to solve the Sudoku after 48 steps. Right: Fine-tuned (SFT) DiffusionGemma solves the puzzle after 12 steps. It is able to complete early thanks to adaptive stopping.
The Performance Impact: While the base DiffusionGemma model is not specifically trained to solve Sudoku puzzles (~0% success rate), applying the simple JAX SFT recipe on a Sudoku dataset raises correctness to 80% success, while decreasing the overall inference step count.
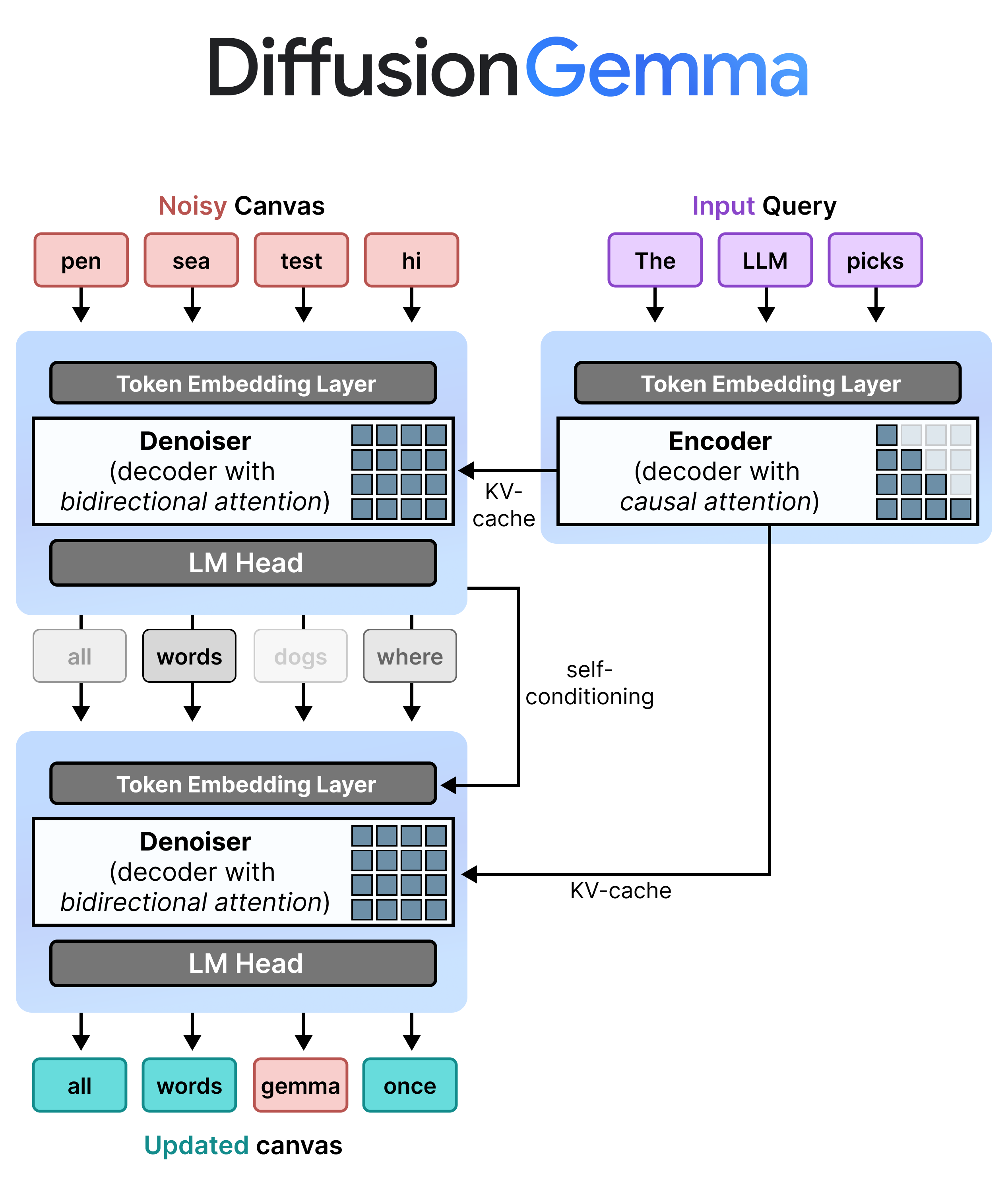
Block Autoregressive Denoising
To enable block autoregressive denoising, DiffusionGemma alternates between incremental prefill and denoising during inference:
Prefill / Incremental Prefill (Causal): Uses causal attention to ingest the prompt context and write to the KV cache. This runs once to prefill the initial context and then once per block to append each finalized 256-token canvas to the KV cache before proceeding to denoising the next canvas.
Denoising (Bidirectional): Uses bidirectional attention to iteratively denoise the canvas. Query tokens at any position on the canvas can attend to all other canvas tokens (as well as KV cache), letting the model process context bidirectionally.
This architectural choice makes the following possible:
Global Context Awareness: Unlike autoregressive (AR) models that only "look backward," the Denoiser's bidirectional attention allows every token on the canvas to attend to every other token. This makes the model much more effective at solving non-sequential problems, such as Sudoku, where a digit in the first cell must respect constraints in the last cell.
Self-Correction: Because the model iteratively refines the whole canvas, it can "fix" earlier mistakes. If a token's confidence drops during a pass, the sampler can re-noise and replace it. This is a capability AR models lack since they are "stuck" with a token once it is generated, especially during long output sequences.
Efficient Long-Context Scaling: The "block-autoregressive" approach allows the model to handle long sequences. It combines the parallel speed of diffusion for blocks with the proven sequential stability of AR models for long-form text.
Simplified Deployment: Using the same architecture as the Gemma 4 26B A4B model means developers only need to implement a denoising step, making it easier to integrate into existing serving frameworks like vLLM.
Serving DiffusionGemma
To serve this experimental architecture efficiently, we worked with the vLLM team to implement DiffusionGemma into vLLM. This integration allows the engine to run the iterative parallel denoising loops efficiently across batched request streams.
Developers can deploy DiffusionGemma out of the box using vLLM's standard OpenAI-compatible local server.
Deploy Your Way: Instantly deploy on Google Cloud using Model Garden or via NVIDIA NIM. The model is optimized natively across the hardware stack from consumer RTX 4090 and 5090 cards to enterprise Hopper and Blackwell servers.