上个月,我们推出了最新一代的开放模型 Gemma 3。凭借先进的性能,Gemma 3 迅速成为能够使用原生 BFloat16 (BF16) 精度在 NVIDIA H100 等单个高端 GPU 上运行的领先模型。
为使 Gemma 3 更易于使用,我们发布了使用量化感知训练 (QAT) 进行优化的新版本,从而大大降低了内存需求,同时保持高质量。这使您能够在消费级 GPU(如 NVIDIA RTX 3090)上运行 Gemma 3 27B 等强大模型。
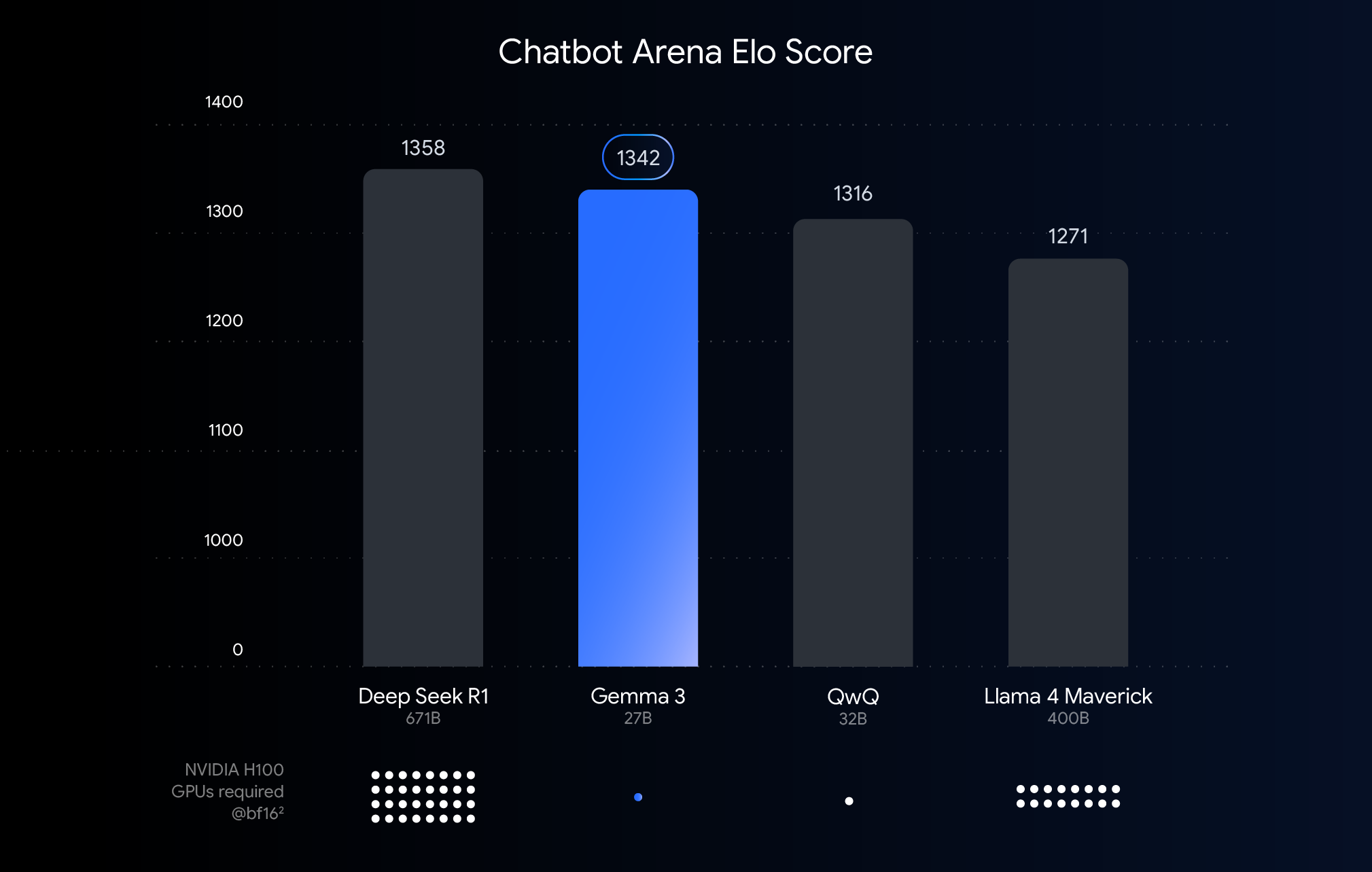
上图显示了最近发布的大语言模型的性能(Elo 评分)。评分基于人类用户对两个匿名模型响应情况的对比观察,条形越高,说明相对性能越好。在每个条形下方,我们展示了使用 BF16 数据类型运行该模型预计所需的 NVIDIA H100 GPU 的数量。
为什么选择 BFloat16 进行对比?BF16 是许多大模型推理过程中常用的数字格式。这意味着模型参数以 16 位的精度表示。对所有模型使用 BF16 有助于我们基于常见的推理设置对模型进行同类比较。如此我们便能够比较模型本身的固有功能,暂不考虑不同硬件之类的变量或量化之类的优化技术,我们接下来会讨论这些因素。
值得注意的是,虽然此图表使用 BF16 以进行公平的比较,但部署最大型的模型通常需要使用 FP8 等低精度格式作为实际必要条件,以减少庞大的硬件要求(如 GPU 数量),因而可能接受性能权衡以取得可行性。
虽然高端硬件的顶级性能非常适合云部署和研究,但我们非常清楚您的诉求:您希望在已有的硬件上拥有 Gemma 3 的强大功能。我们致力于实现强大的 AI 可用性,这意味着在台式机、笔记本电脑甚至手机中的消费级 GPU 上实现高性能。
这正是量化的用武之地。在 AI 模型中,量化降低了其存储并用于计算响应的数字(模型参数)的精度。可以将量化视为减少图像使用的颜色数量来压缩图像。我们可以使用更少的位,例如 8 位 (int8) 甚至 4 位 (int4),而不是每个数字使用 16 位 (BFloat16)。
使用 int4 意味着每个数字仅使用 4 位表示,也就是说,与 BF16 相比,数据大小减少了 4 倍。量化通常会导致性能下降,因此我们很高兴发布对量化具有鲁棒性的 Gemma 3 模型。我们为各个 Gemma 3 模型发布了几个量化变体,以便您使用自己最喜欢的推理引擎进行推理,例如适用于 Ollama、llama.cpp 和 MLX 的 Q4_0(一种常见的量化格式)。
我们如何保持质量?我们使用 QAT。QAT 在训练过程中融入了量化过程,而不是仅仅在模型得到完全训练后再对其进行量化。QAT 在训练期间模拟低精度操作,以便在保持精度的同时,对更小、更快的模型进行量化并减少退化。我们还进行了更深入的研究,使用来自非量化检查点的概率作为目标,将 QAT 应用于约 5,000 个步骤。当量化到 Q4_0 时,我们将困惑度降低了 54% (使用 llama.cpp 困惑度评估)。
int4 量化的影响非常可观。请看仅加载模型权重所需的 VRAM(GPU 内存):
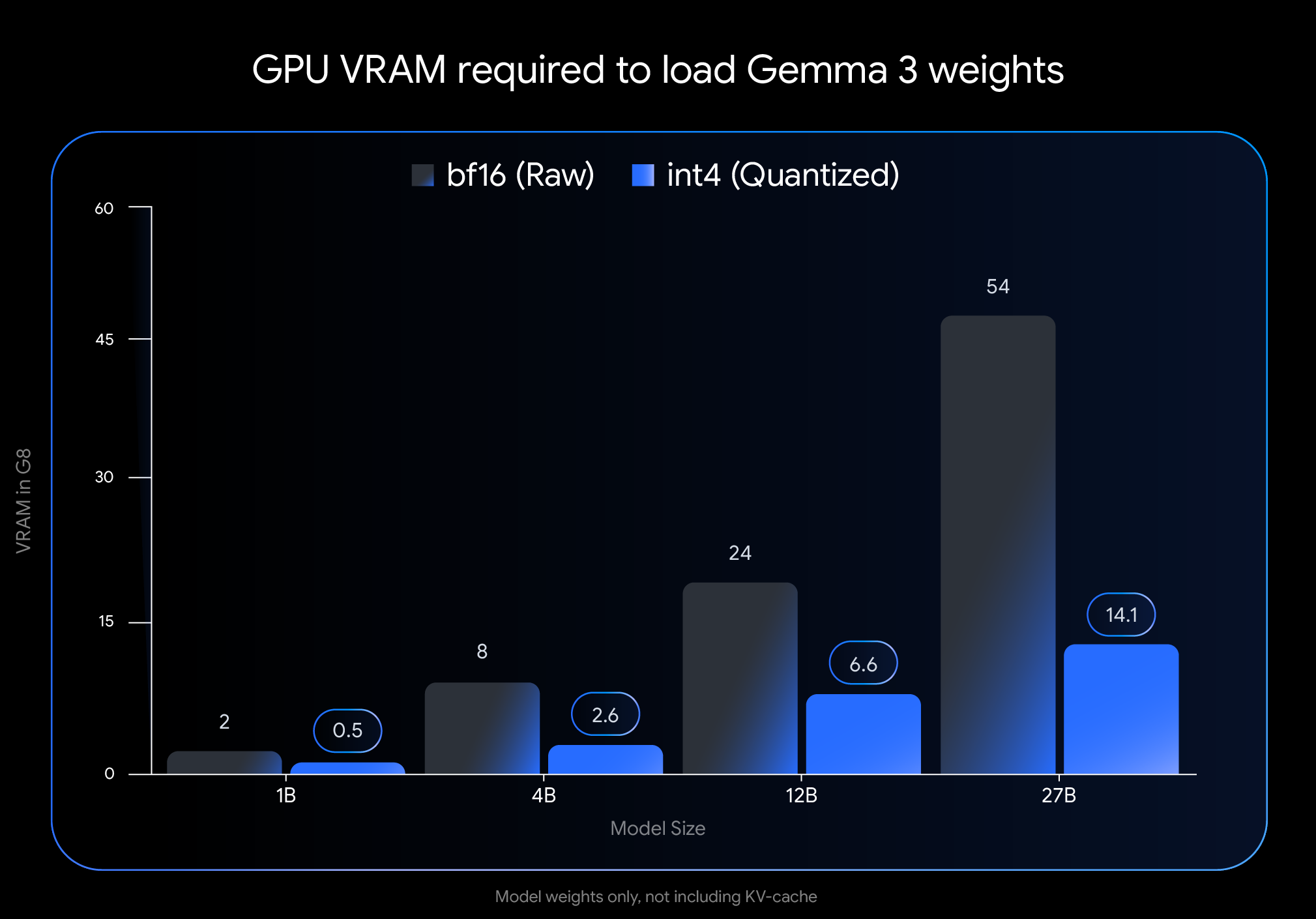
注意: 此图仅表示加载模型权重所需的 VRAM。运行该模型还需要为 KV 缓存提供额外的 VRAM,该缓存存储有关正在进行的对话的信息,并且受上下文长度影响
显著的内存节省使得我们可以在广泛使用的消费级硬件上运行更大型、更强大模型:
我们希望您能够在首选工作流程中轻松使用这些模型。我们的官方 int4 和 Q4_0 非量化 QAT 型号可在 Hugging Face 和 Kaggle 上使用。我们与热门开发者工具合作,可以无缝尝试基于 QAT 的量化检查点:
我们的官方量化感知训练 (QAT) 模型提供了高质量的基准,但充满活力的 Gemmaverse 还提供了许多替代方案。这些方案通常使用训练后量化 (PTQ),可在 Hugging Face 上轻松获取,Bartowski、Unsloth 和 GGML 等社区成员为此作出了巨大贡献。探索这些社区选项可实现更广泛的规模、速度和质量权衡,以满足特定需求。
将先进的 AI 性能引入无障碍硬件是实现 AI 开发普及的关键一步。借助经 QAT 优化的 Gemma 3 模型,您现在可以在自己的台式机或笔记本电脑上利用尖端功能。
探索量化模型并开始构建:
我们迫不及待地想看看您会用本地运行的 Gemma 3 构建什么!