

Dalam lanskap model bahasa besar (LLM) yang berkembang pesat, sebagian besar sorotan berfokus pada arsitektur hanya-decoder. Meskipun model ini menunjukkan kemampuan yang mengesankan di berbagai tugas pembuatan, arsitektur encoder-decoder klasik, seperti T5 (The Text-to-Text Transfer Transformer), tetap menjadi pilihan populer untuk banyak aplikasi dunia nyata. Model encoder-decoder sering kali unggul dalam peringkasan, penerjemahan, QA, dan lainnya karena efisiensi inferensi yang tinggi, fleksibilitas desain, dan representasi encoder yang lebih kaya untuk memahami input. Namun, arsitektur encoder-decoder yang kuat ini hanya mendapat sedikit perhatian.
Hari ini, kami meninjau kembali arsitektur ini dan memperkenalkan T5Gemma, sebuah koleksi baru LLM encoder-decoder yang dikembangkan melalui konversi model hanya-decoder terlatih menjadi arsitektur encoder-decoder dengan teknik yang disebut adaptasi. T5Gemma dibangun di atas framework Gemma 2, mencakup model Gemma 2 berukuran 2B dan 9B yang telah diadaptasi, serta serangkaian model berukuran T5 yang baru dilatih (Small, Base, Large, dan XL). Kami dengan antusias merilis model T5Gemma versi terlatih dan yang telah disetel berdasarkan instruksi kepada komunitas, untuk membuka peluang baru dalam riset dan pengembangan.
Di T5Gemma, kami mengajukan pertanyaan berikut: Dapatkah kita membangun model encoder-decoder tingkat atas berdasarkan model hanya-decoder terlatih? Kami menjawab pertanyaan ini dengan mengeksplorasi teknik yang disebut adaptasi model. Ide intinya adalah melakukan inisialiasi parameter model encoder-decoder dengan bobot dari model hanya-decoder yang sudah terlatih, kemudian mengadaptasinya lebih lanjut melalui tahap pra-pelatihan berbasis UL2 atau PrefixLM.
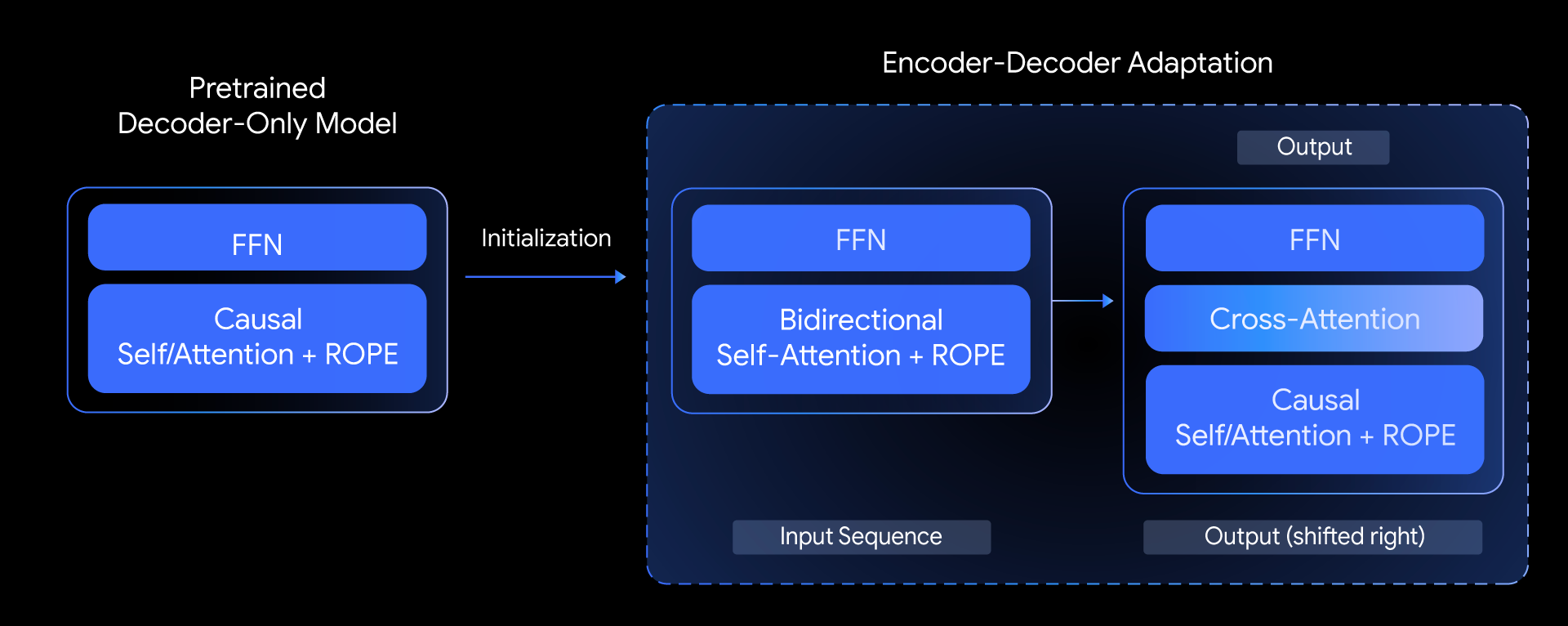
Metode adaptasi ini sangat fleksibel, memungkinkan kombinasi ukuran model yang kreatif. Sebagai contoh, kami bisa memasangkan encoder besar dengan decoder kecil (mis., encoder 9B dengan decoder 2B) untuk membuat model yang “tidak seimbang”. Hal ini memungkinkan kami menyesuaikan keseimbangan kualitas-efisiensi untuk tugas tertentu, seperti peringkasan, ketika pemahaman yang mendalam tentang input lebih penting daripada kompleksitas output yang dihasilkan.
Seperti apa performa T5Gemma?
Dalam eksperimen kami, model T5Gemma mencapai performa yang setara atau lebih baik daripada model Gemma yang hanya menggunakan decoder, nyaris mendominasi batas pareto efisiensi kualitas-inferensi di beberapa tolok ukur, seperti SuperGLUE yang mengukur kualitas representasi yang dipelajari.
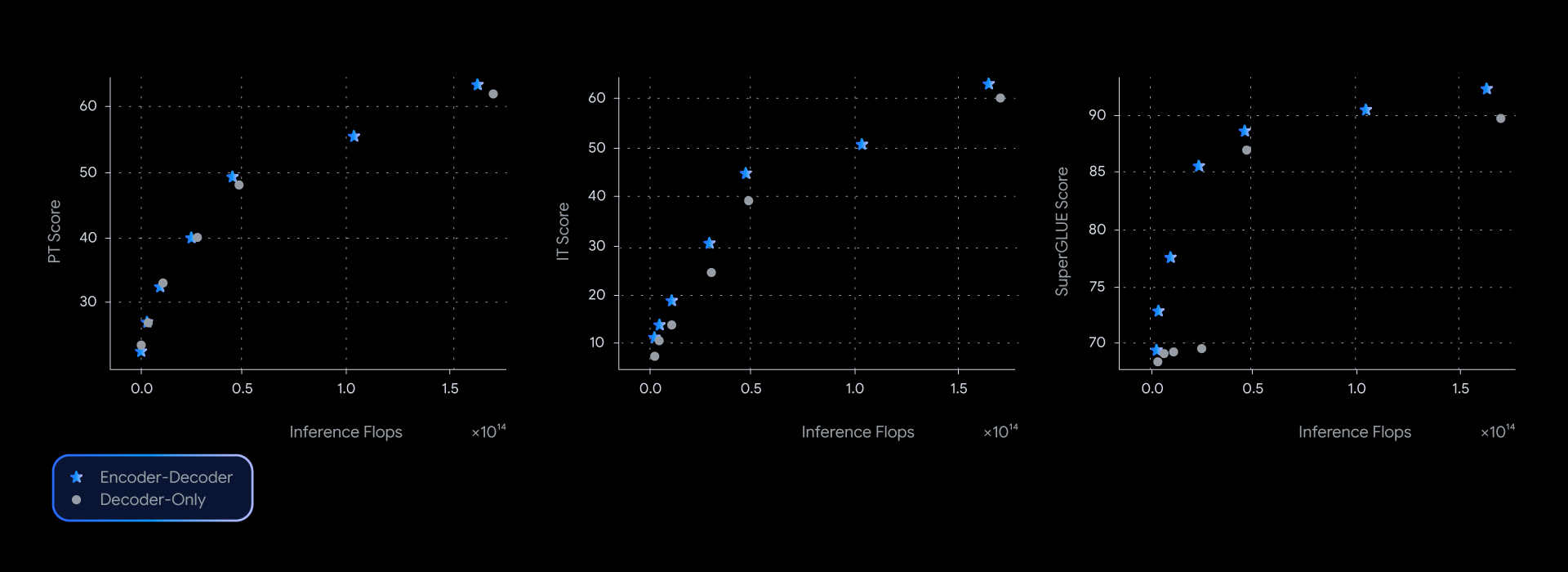
Keunggulan performa ini bukan hanya teoritis; tetapi juga diterjemahkan ke dalam kualitas dan kecepatan di dunia nyata. Ketika mengukur latensi aktual untuk GSM8K (penalaran matematika), T5Gemma memberikan kemenangan yang jelas. Sebagai contoh, T5Gemma 9B-9B mencapai akurasi yang lebih tinggi daripada Gemma 2 9B tetapi dengan latensi yang sama. Yang lebih mengesankan lagi, T5Gemma 9B-2B memberikan lonjakan akurasi signifikan dibandingkan model 2B-2B, dengan latensi yang hampir setara dengan model Gemma 2 2B yang ukurannya jauh lebih kecil. Pada akhirnya, eksperimen ini menunjukkan bahwa adaptasi encoder-decoder menawarkan cara yang fleksibel dan andal untuk menyeimbangkan kualitas dan kecepatan inferensi.
Dapatkah LLM encoder-decoder memiliki kemampuan yang setara dengan model hanya-decoder?
Ya, T5Gemma menunjukkan kemampuan yang menjanjikan, baik sebelum maupun sesudah penyetelan instruksi.
Setelah pra-pelatihan, T5Gemma mencapai hasil yang mengesankan pada tugas kompleks yang membutuhkan penalaran. Sebagai contoh, T5Gemma 9B-9B mendapatkan skor lebih dari 9 poin lebih tinggi pada GSM8K (penalaran matematika) dan 4 poin lebih tinggi pada DROP (pemahaman bacaan) daripada model Gemma 2 9B asli. Pola ini menunjukkan bahwa arsitektur encoder-decoder, ketika diinisialisasi melalui adaptasi, memiliki potensi untuk menciptakan model dasar yang lebih mumpuni dan berkinerja baik.
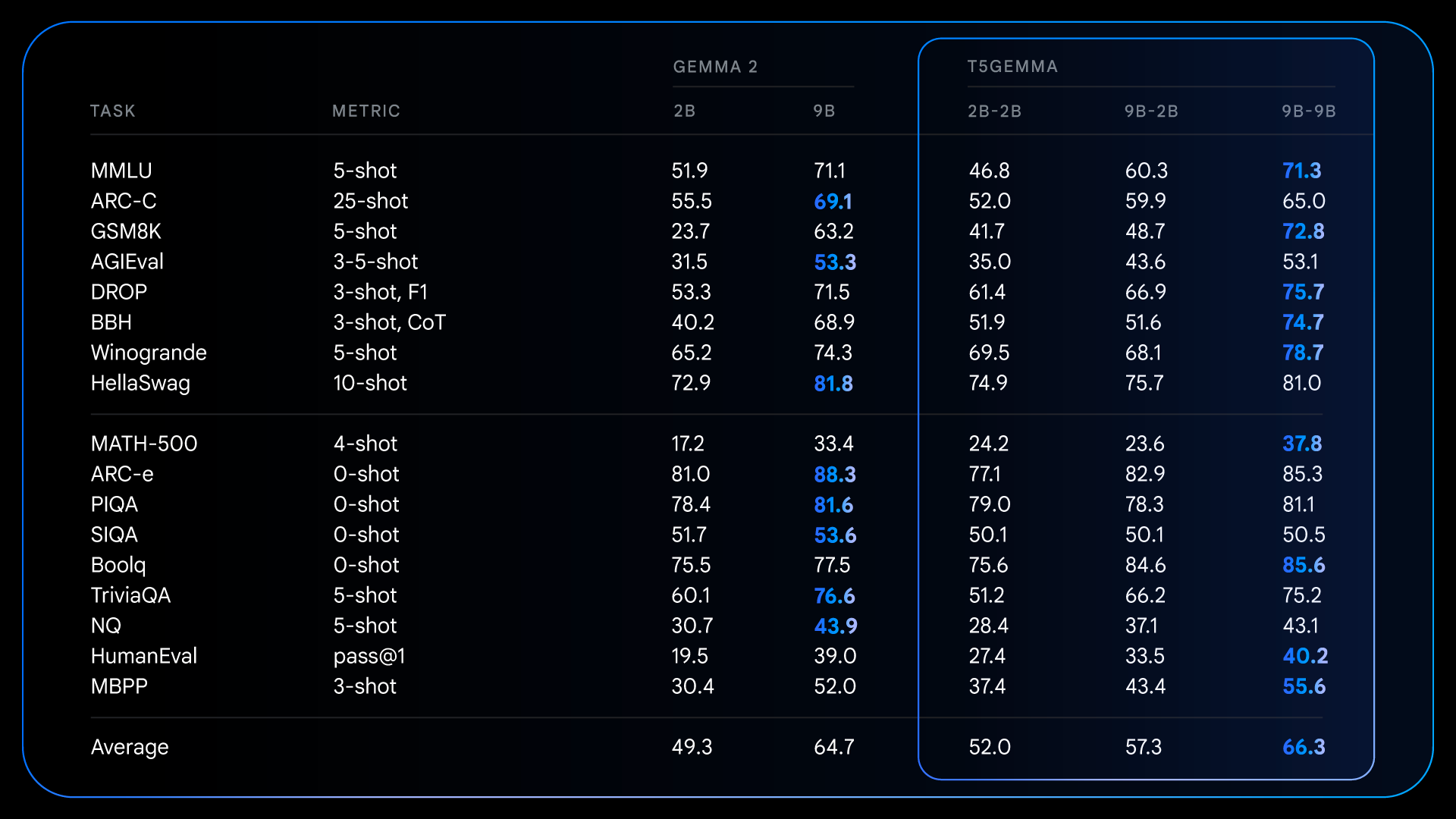
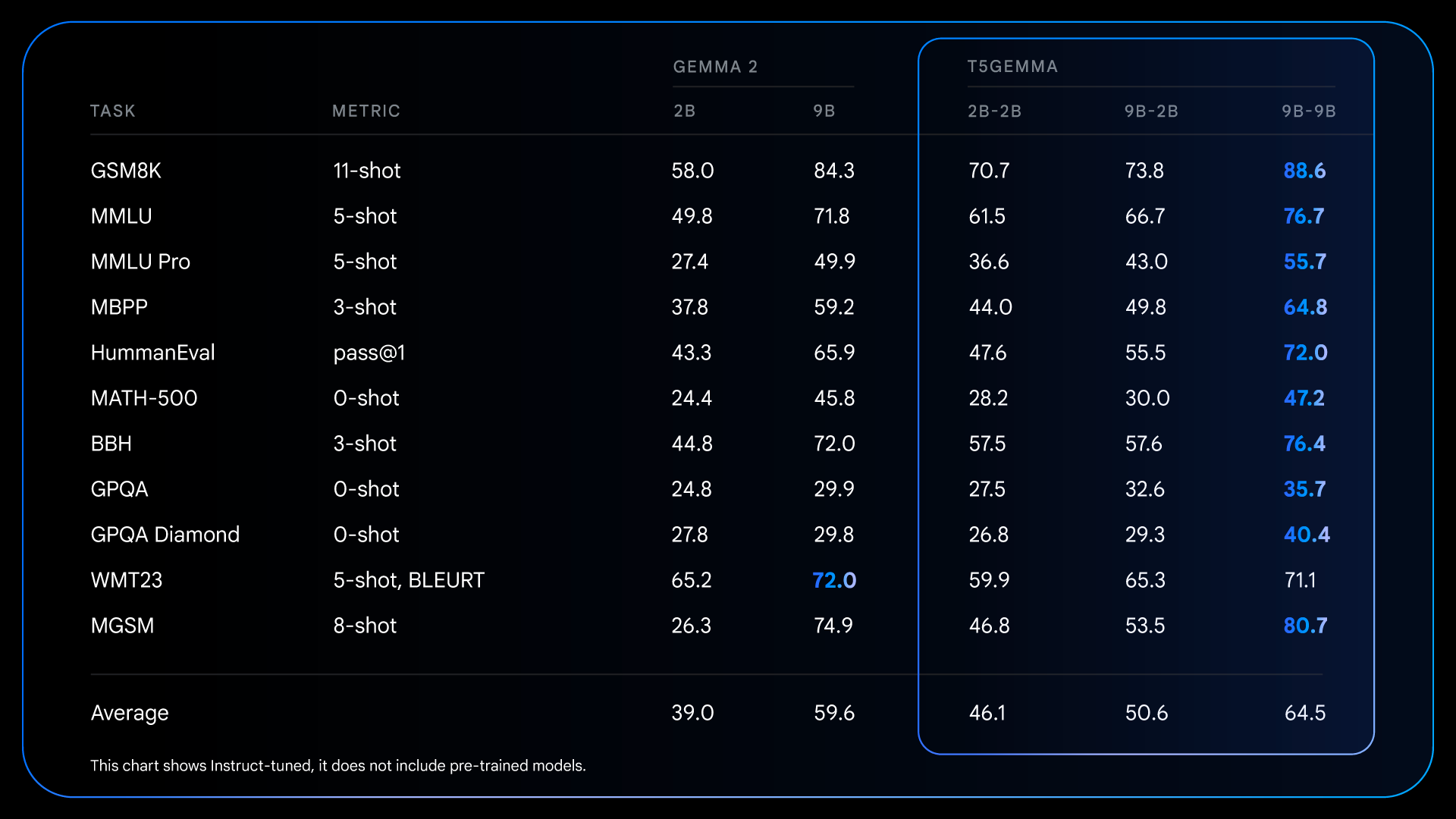
Peningkatan mendasar dari tahap pra-pelatihan ini menjadi landasan bagi pencapaian yang lebih signifikan setelah proses penyetelan instruksi. Sebagai contoh, dengan membandingkan Gemma 2 IT dengan T5Gemma IT, kesenjangan performa melebar secara signifikan di seluruh bagian. T5Gemma 2B-2B IT mengalami lonjakan skor MMLU hampir 12 poin dibandingkan Gemma 2 2B, dan skor GSM8K meningkat dari 58,0% menjadi 70,7%. Arsitektur hasil adaptasi ini tidak hanya berpotensi memberikan titik awal yang lebih baik, tetapi juga menunjukkan respons yang lebih efektif terhadap penyetelan instruksi, sehingga menghasilkan model akhir yang jauh lebih unggul dan bermanfaat.
Kami sangat bersemangat memperkenalkan metode baru ini untuk membangun model encoder-decoder serbaguna yang kuat dengan mengadaptasi dari LLM hanya-decoder terlatih seperti Gemma 2. Untuk membantu mempercepat penelitian lanjutan dan memungkinkan komunitas mengembangkan pekerjaan ini, kami sangat senang dapat merilis rangkaian checkpoint T5Gemma kami.
Rilis ini mencakup:
Kami berharap checkpoint ini akan memberikan sumber daya yang berharga untuk menginvestigasi arsitektur, efisiensi, dan performa model.
Kami tidak sabar ingin segera melihat kreasi Anda dengan T5Gemma. Untuk informasi lebih lanjut, silakan lihat link berikut:

Memperkenalkan Gemma 3n: Panduan developer

Gemini Embedding: Powering RAG and context engineering
Inovasi multibahasa dalam LLM: Bagaimana model terbuka membantu membuka komunikasi global
Introducing LangExtract: A Gemini powered information extraction library
Memperkenalkan Opal: deskripsikan, buat, dan bagikan aplikasi mini AI Anda