Bulan lalu, kami meluncurkan Gemma 3, generasi terbaru model terbuka kami. Menghadirkan performa tercanggih, Gemma 3 dengan cepat memantapkan dirinya sebagai model terdepan yang mampu berjalan pada satu GPU kelas atas seperti NVIDIA H100 dengan menggunakan BFloat16 (BF16) native yang presisi.
Untuk membuat Gemma 3 semakin mudah diakses, kami mengumumkan versi baru yang dioptimalkan dengan Quantization-Aware Training (QAT) yang secara dramatis mengurangi kebutuhan memori sekaligus mempertahankan kualitas tinggi. Ini memungkinkan Anda menjalankan model yang kuat seperti Gemma 3 27B secara lokal pada GPU kelas konsumen, misalnya NVIDIA RTX 3090.
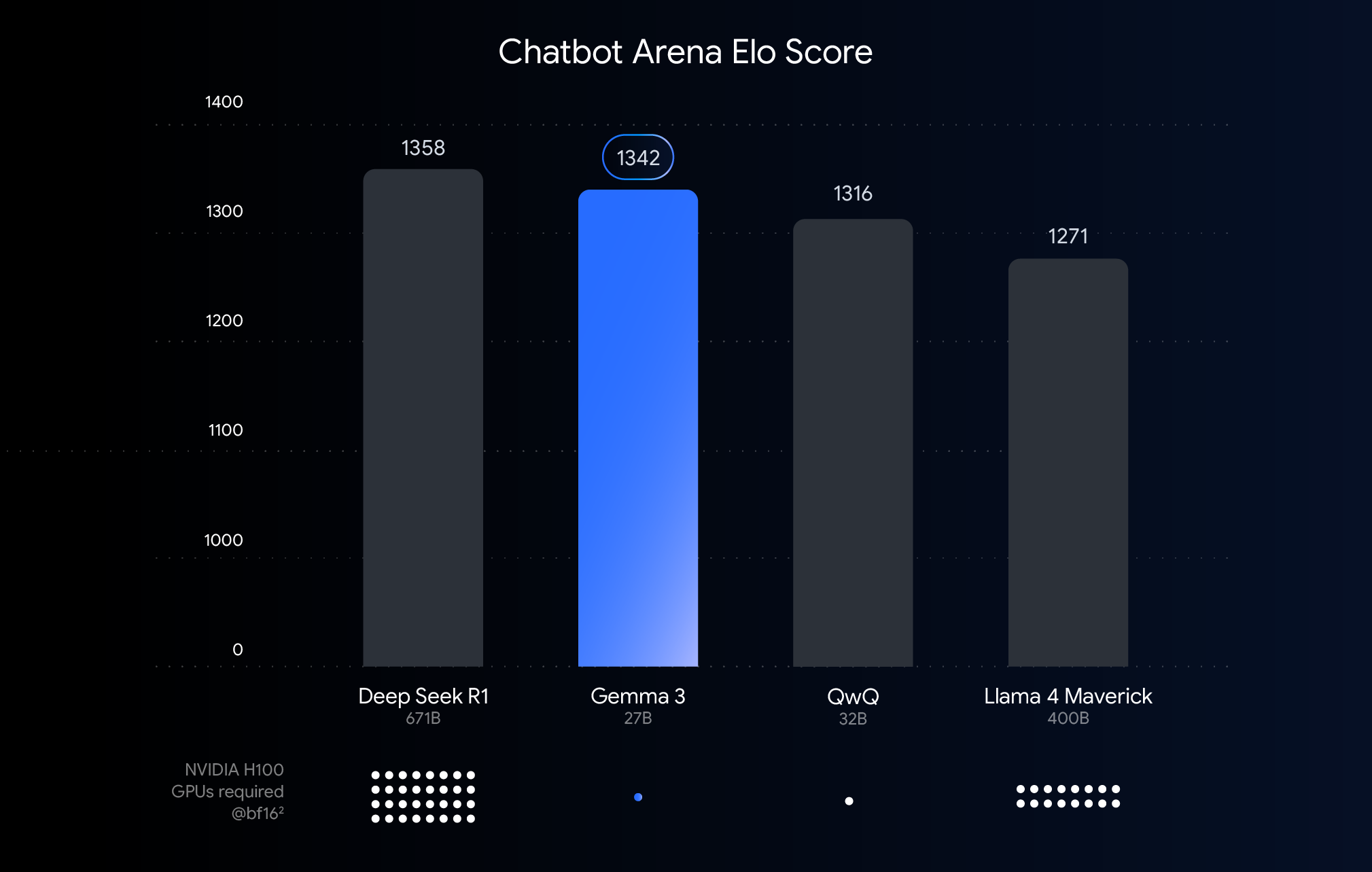
Chart di atas menunjukkan performa (skor Elo) dari model bahasa besar yang baru saja dirilis. Batang yang lebih tinggi berarti performa yang lebih baik saat dibandingkan sebagaimana dinilai oleh manusia yang melihat respons berdampingan dari dua model anonim. Di bawah setiap batang, kami menunjukkan perkiraan jumlah GPU NVIDIA H100 yang dibutuhkan untuk menjalankan model tersebut menggunakan tipe data BF16.
Mengapa menggunakan BFloat16 untuk perbandingan ini? BF16 adalah format numerik umum yang digunakan selama inferensi banyak model besar. Ini berarti bahwa parameter model direpresentasikan dengan presisi 16 bit. Menggunakan BF16 untuk semua model membantu kami membuat perbandingan model yang setara dengan model lainnya dalam pengaturan inferensi umum. Ini memungkinkan kami membandingkan kemampuan yang melekat pada model itu sendiri, menghilangkan variabel seperti hardware yang berbeda atau teknik pengoptimalan seperti kuantisasi, yang akan kita bahas berikutnya.
Perlu dicatat bahwa meskipun chart ini menggunakan BF16 untuk perbandingan setara, tetapi penerapan model terbesar sering kali melibatkan penggunaan format dengan presisi yang lebih rendah seperti FP8 sebagai tuntutan praktis untuk mengurangi kebutuhan hardware yang sangat besar (seperti jumlah GPU), sehingga berpotensi menerima kompromi performa untuk kelayakan.
Meskipun performa terbaik pada hardware kelas atas sangat bagus untuk deployment cloud dan penelitian, kami mendengar Anda dengan sangat jelas: Anda menginginkan kekuatan Gemma 3 pada hardware yang sudah Anda miliki. Kami berkomitmen untuk membuat AI kuat yang dapat diakses, dan itu berarti memungkinkan performa yang efisien pada GPU kelas konsumen yang ditemukan di desktop, laptop, dan bahkan ponsel.
Di sinilah kuantisasi berperan. Dalam model AI, kuantisasi mengurangi presisi angka (parameter model) yang disimpan dan digunakan untuk menghitung respons. Bayangkan kuantisasi seperti mengompresi gambar dengan mengurangi jumlah warna yang digunakan. Alih-alih menggunakan 16 bit per angka (BFloat16), kita dapat menggunakan bit yang lebih sedikit, seperti 8 (int8) atau bahkan 4 (int4).
Menggunakan int4 berarti setiap angka direpresentasikan hanya dengan 4 bit – pengurangan ukuran data sebesar 4x dibandingkan dengan BF16. Kuantisasi sering kali menyebabkan penurunan performa, jadi kami sangat senang dapat merilis model Gemma 3 yang andal untuk kuantisasi. Kami merilis beberapa varian yang dikuantisasi untuk setiap model Gemma 3 yang memungkinkan inferensi dengan mesin inferensi favorit Anda, seperti Q4_0 (format kuantisasi umum) untuk Ollama, llama.cpp, dan MLX.
Bagaimana kami menjaga kualitas? Kami menggunakan QAT. Alih-alih hanya melakukan kuantisasi model setelah dilatih sepenuhnya, QAT menggabungkan proses kuantisasi selama pelatihan. QAT menyimulasikan operasi presisi rendah selama pelatihan untuk memungkinkan kuantisasi dengan degradasi yang lebih kecil setelahnya untuk model yang lebih kecil dan cepat sekaligus mempertahankan akurasi. Lebih dalam lagi, kami menerapkan QAT pada ~5.000 langkah dengan menggunakan probabilitas dari titik pemeriksaan yang tidak dikuantisasi sebagai target. Kami mengurangi penurunan kerancuan sebesar 54% (menggunakan evaluasi kerancuan llama.cpp) ketika mengkuantisasi hingga Q4_0.
Dampak dari kuantisasi int4 sangatlah dramatis. Lihatlah VRAM (memori GPU) yang diperlukan hanya untuk memuat bobot model:
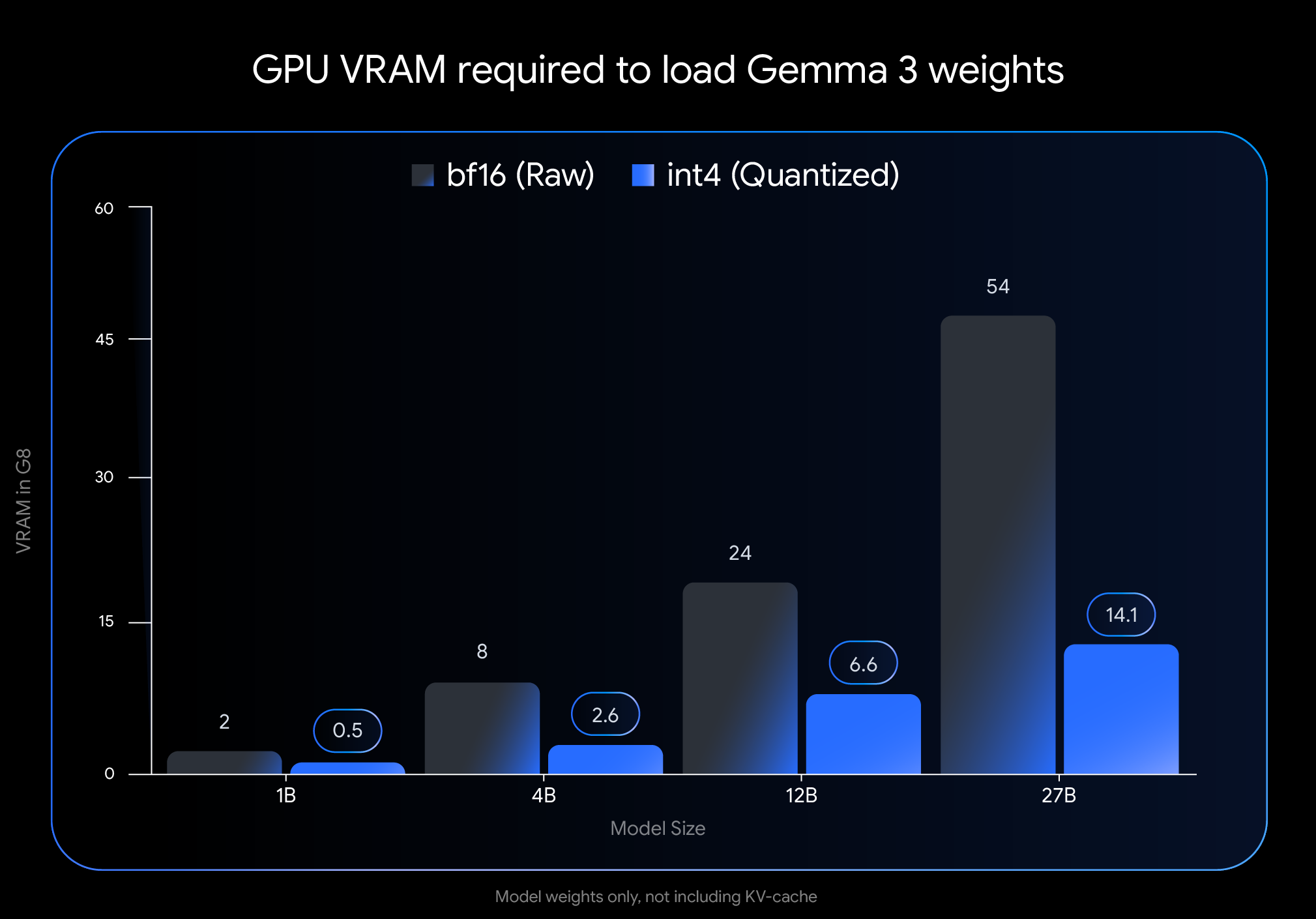
Catatan: Gambar ini hanya menunjukkan VRAM yang dibutuhkan untuk memuat bobot model. Menjalankan model juga membutuhkan VRAM tambahan untuk cache KV, yang menyimpan informasi tentang percakapan yang sedang berlangsung dan bergantung pada panjang konteks
Pengurangan dramatis ini membuka kemampuan untuk menjalankan model yang lebih besar dan bertenaga pada hardware konsumen yang tersedia secara luas:
Kami ingin Anda dapat menggunakan model-model ini secara mudah dalam alur kerja favorit Anda. Model QAT tak terkuantisasi int4 dan Q4_0 resmi kami tersedia di Hugging Face dan Kaggle. Kami bermitra dengan alat developer populer yang memungkinkan Anda mencoba titik pemeriksaan terkuantisasi berbasis QAT dengan lancar:
Model Quantization Aware Trained (QAT) resmi kami memberikan dasar berkualitas tinggi, tetapi Gemmaverse yang dinamis menawarkan banyak alternatif. Model ini sering kali menggunakan Post-Training Quantization (PTQ), dengan kontribusi yang signifikan dari anggota, seperti Bartowski, Unsloth, dan GGML yang tersedia di Hugging Face. Menjelajahi opsi komunitas ini memberikan spektrum yang lebih luas terkait kompromi ukuran, kecepatan, dan kualitas untuk menyesuaikan dengan kebutuhan khusus.
Menghadirkan performa AI termutakhir ke hardware yang dapat diakses adalah langkah penting dalam mendemokratisasi pengembangan AI. Dengan model Gemma 3, yang dioptimalkan melalui QAT, kini Anda bisa memanfaatkan kemampuan tercanggih di desktop atau laptop Anda.
Jelajahi model yang dikuantisasi dan mulailah membangun:
Kami tak sabar ingin segera melihat kreasi Anda dengan Gemma 3 yang berjalan secara lokal!