

El mes pasado, lanzamos Gemma 3, nuestra generación más reciente de modelos de código abierto. Con su rendimiento de vanguardia, Gemma 3 se estableció rápidamente como un modelo líder capaz de funcionar en una sola GPU de gama alta, como la NVIDIA H100, gracias a la precisión de BFloat16 (BF16) nativo.
Para que Gemma 3 sea aún más accesible, anunciamos nuevas versiones optimizadas con entrenamiento consciente de cuantificación (QAT), que reduce drásticamente los requisitos de memoria a la vez que mantiene una alta calidad. De esta manera, puedes ejecutar modelos potentes como Gemma 3 27B localmente en GPU comerciales, como NVIDIA RTX 3090.
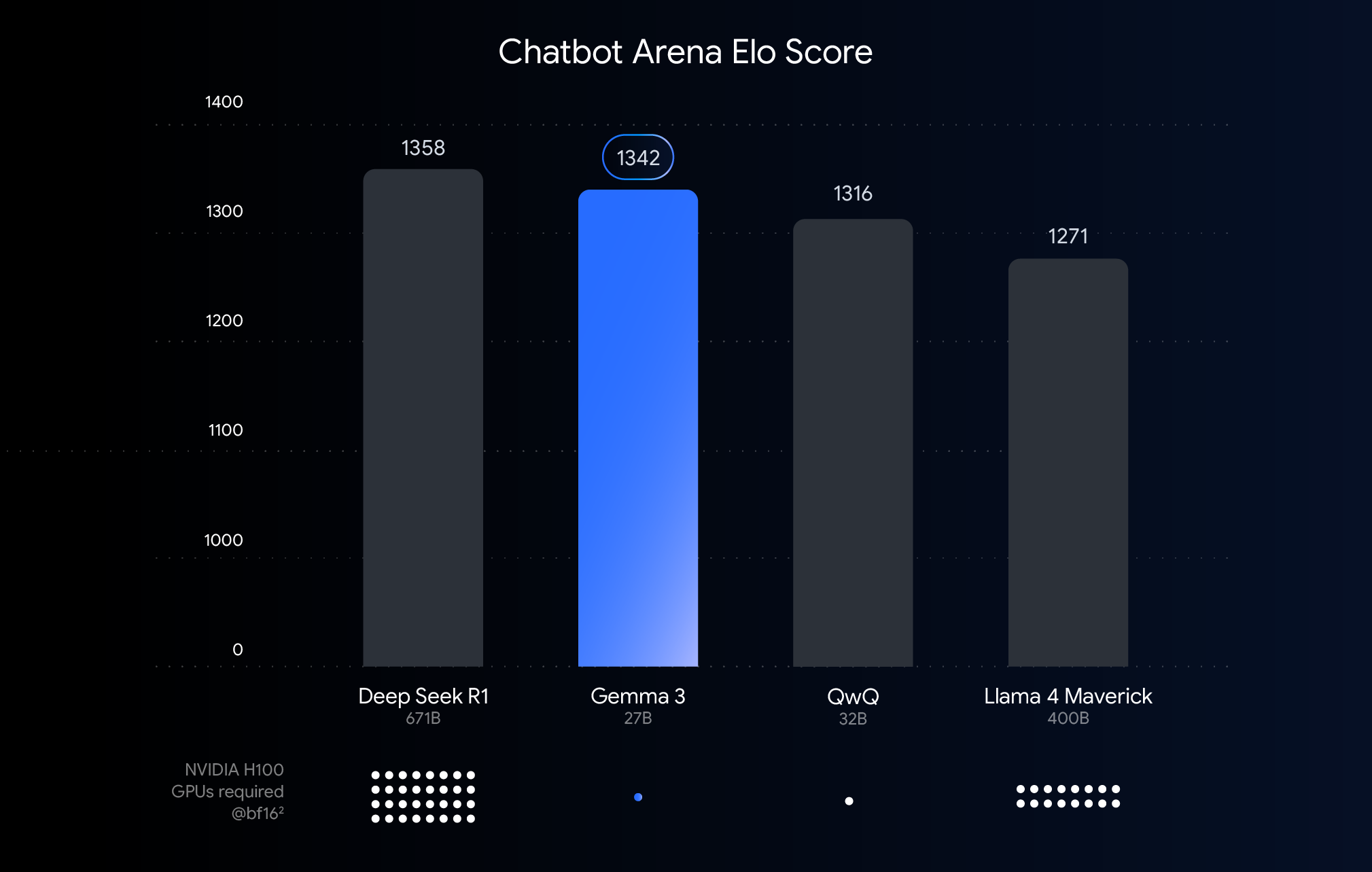
En la tabla anterior, se muestra el rendimiento (puntuación Elo) de los modelos de lenguaje grandes que se lanzaron en los últimos meses. Las barras más altas indican un mejor rendimiento en las comparaciones según la calificación de los humanos que ven las respuestas una al lado de la otra de dos modelos anónimos. Debajo de cada barra, indicamos el número estimado de GPU NVIDIA H100 necesarias para ejecutar ese modelo utilizando el tipo de datos BF16.
¿Por qué se usó BFloat16 para esta comparación? BF16 es un formato numérico común que se utiliza durante la inferencia de muchos modelos grandes. Indica que los parámetros del modelo se representan con 16 bits de precisión. El uso de BF16 en todos los modelos nos ayuda a hacer una comparación entre modelos equivalentes en una configuración de inferencia común. De esta manera, podemos comparar las capacidades inherentes de los propios modelos y eliminar variables, como diferentes hardware, o técnicas de optimización, como la cuantificación, que analizaremos a continuación.
Es importante tener en cuenta que, si bien este gráfico utiliza el formato BF16 para establecer una comparación justa, la implementación de los modelos más grandes suele involucrar formatos de menor precisión, como FP8, como una necesidad práctica para reducir los inmensos requisitos de hardware (como la cantidad de GPU), de modo que se puede aceptar una compensación de rendimiento por viabilidad.
Si bien el rendimiento máximo en hardware de alta gama es excelente para las implementaciones e investigaciones en la nube, tuvimos en cuenta los comentarios de los desarrolladores, que buscan la potencia de Gemma 3 en el hardware que ya tienen. Nos comprometemos a hacer que la IA poderosa sea accesible y eso significa ofrecer un rendimiento eficiente en las GPU de nivel comercial que se encuentran en computadoras de escritorio, computadoras portátiles e incluso teléfonos.
Es en este punto donde entra en juego la cuantificación. En los modelos de IA, la cuantificación reduce la precisión de los números (los parámetros del modelo) que almacena y utiliza para calcular las respuestas. Se podría decir que la cuantificación es como comprimir una imagen reduciendo el número de colores. En lugar de usar 16 bits por número (BFloat16), podemos usar menos bits, como 8 (int8) o incluso 4 (int4).
Si utilizamos int4, cada número se representa usando solo 4 bits, es decir, una reducción de 4 veces en el tamaño de los datos en comparación con BF16. La cuantificación suele generar una reducción del rendimiento, por lo que nos entusiasma lanzar modelos de Gemma 3 que son sólidos para la cuantificación. Lanzamos diversas variantes cuantificadas para cada modelo de Gemma 3 a fin de permitir la inferencia con tu motor de inferencia favorito, como Q4_0 (un formato de cuantificación común) para Ollama, llama.cpp y MLX.
¿Cómo mantenemos la calidad? Utilizamos QAT. En lugar de simplemente cuantificar el modelo después de que esté completamente entrenado, QAT incorpora el proceso de cuantificación durante el entrenamiento. QAT simula operaciones de baja precisión durante el entrenamiento para permitir la cuantificación con menos reducción posterior del rendimiento en modelos más pequeños y rápidos, mientras se mantiene la precisión. Además, aplicamos QAT en ~5000 pasos utilizando probabilidades del punto de control no cuantificado como objetivos. Reducimos la caída de perplejidad un 54% (utilizando la evaluación de perplejidad llama.cpp) al cuantificar hasta Q4_0.
El impacto de la cuantificación con int4 es muy grande. Observa la VRAM (memoria de GPU) necesaria solo para cargar los pesos del modelo:
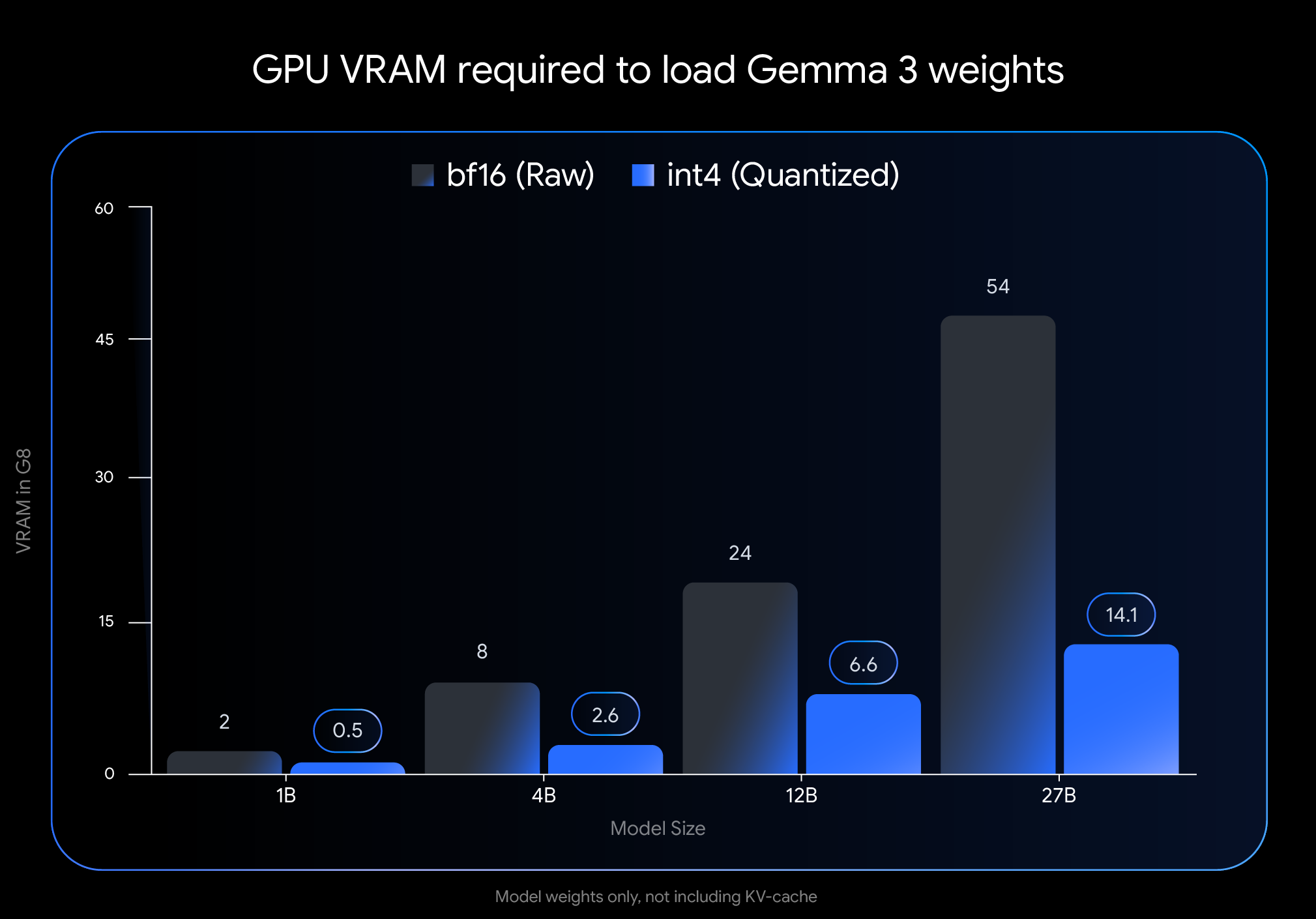
Nota: En esta imagen, solo se representa la VRAM necesaria para cargar los pesos del modelo. La ejecución del modelo también requiere VRAM adicional para la caché de KV, que almacena información sobre la conversación en curso y depende de la duración del contexto.
Estas enormes reducciones ofrecen la capacidad de ejecutar modelos más grandes y potentes en hardware comercial ampliamente disponible:
Queremos que puedas usar estos modelos fácilmente dentro de tu flujo de trabajo preferido. Nuestros modelos QAT sin cuantificar con INT4 y Q4_0 oficiales están disponibles en Hugging Face y Kaggle. Nos asociamos con creadores de herramientas para desarrolladores populares que permiten probar sin problemas los puntos de control cuantificados basados en QAT:
Nuestros modelos oficiales de entrenamiento consciente de cuantificación (QAT) proporcionan una línea de base de alta calidad, pero el vibrante Gemmaverso ofrece muchas alternativas. Estas suelen utilizar la cuantificación posterior al entrenamiento (PTQ), y hay contribuciones importantes de miembros como Bartowski, Unsloth y GGML disponibles en Hugging Face. Si analizas estas opciones de la comunidad, tendrás un espectro más amplio de las compensaciones de tamaño, velocidad y calidad para satisfacer necesidades específicas.
Obtener el rendimiento de la IA de vanguardia en hardware accesible es un paso clave para democratizar el desarrollo de la IA. Con los modelos de Gemma 3, optimizados a través de QAT, ahora puedes aprovechar las capacidades de vanguardia en tu propia computadora de escritorio o laptop.
Explora los modelos cuantificados y comienza a compilar:
¡Tenemos muchas ganas de ver lo que creas con Gemma 3 en tu dispositivo!

Advancing the frontier of video understanding with Gemini 2.5

Presentamos TxGemma: modelos de código abierto para mejorar el desarrollo de terapias

Gemini 2.5 Models now support implicit caching
Todo sobre Gemma: novedades de Gemma 3