

Today, we’re releasing two updated production-ready Gemini models: Gemini-1.5-Pro-002 and Gemini-1.5-Flash-002 along with:
These new models build on our latest experimental model releases and include meaningful improvements to the Gemini 1.5 models released at Google I/O in May. Developers can access our latest models for free via Google AI Studio and the Gemini API. For larger organizations and Google Cloud customers, the models are also available on Vertex AI.
The Gemini 1.5 series are models that are designed for general performance across a wide range of text, code, and multimodal tasks. For example, Gemini models can be used to synthesize information from 1000 page PDFs, answer questions about repos containing more than 10 thousand lines of code, take in hour long videos and create useful content from them, and more.
With the latest updates, 1.5 Pro and Flash are now better, faster, and more cost-efficient to build with in production. We see a ~7% increase in MMLU-Pro, a more challenging version of the popular MMLU benchmark. On MATH and HiddenMath (an internal holdout set of competition math problems) benchmarks, both models have made a considerable ~20% improvement. For vision and code use cases, both models also perform better (ranging from ~2-7%) across evals measuring visual understanding and Python code generation.
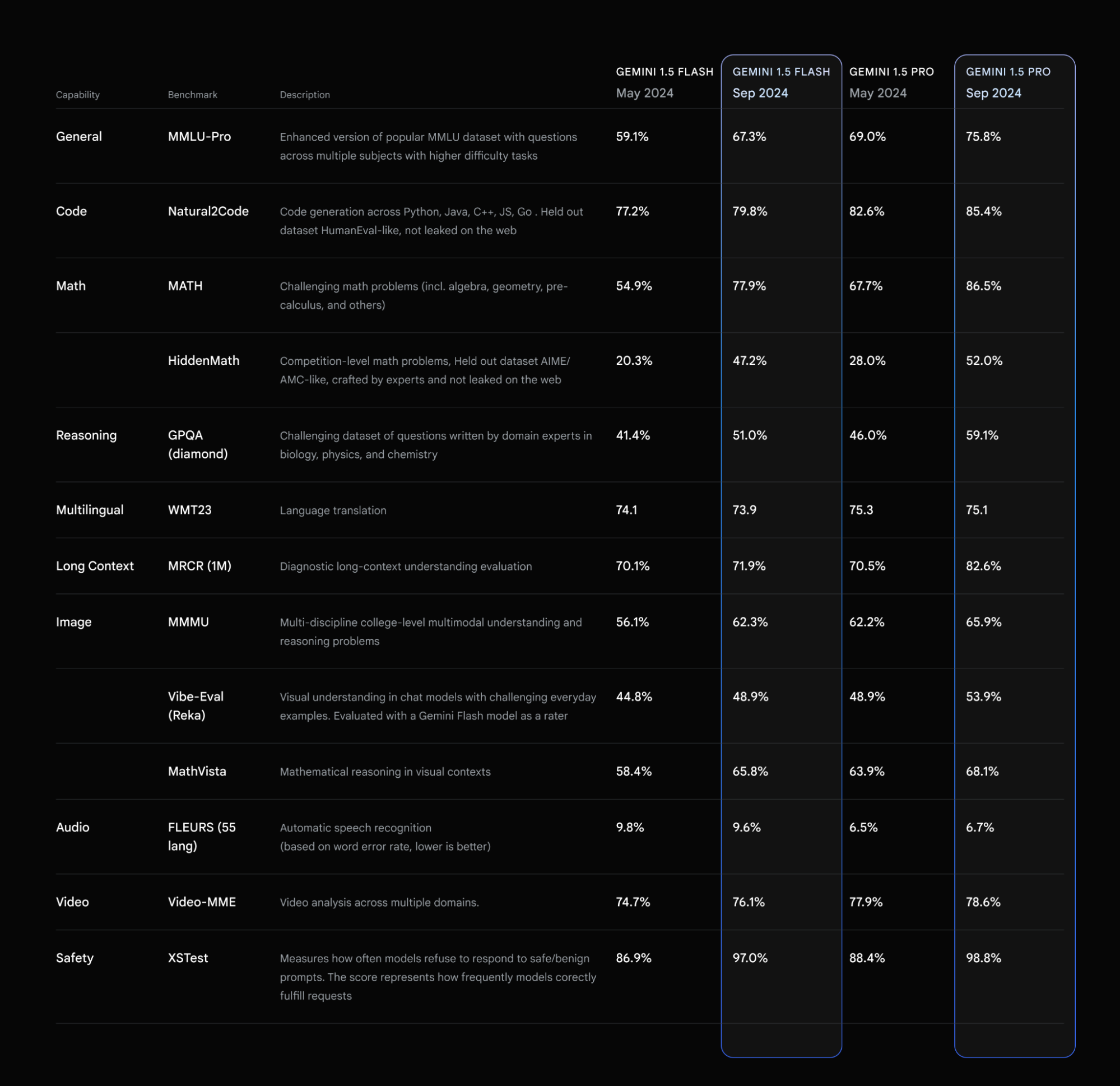
We also improved the overall helpfulness of model responses, while continuing to uphold our content safety policies and standards. This means less punting/fewer refusals and more helpful responses across many topics.
Both models now have a more concise style in response to developer feedback which is intended to make these models easier to use and reduce costs. For use cases like summarization, question answering, and extraction, the default output length of the updated models is ~5-20% shorter than previous models. For chat-based products where users might prefer longer responses by default, you can read our prompting strategies guide to learn more about how to make the models more verbose and conversational.
For more details on migrating to the latest versions of Gemini 1.5 Pro and 1.5 Flash, check out the Gemini API models page.
We continue to be blown away with the creative and useful applications of Gemini 1.5 Pro’s 2 million token long context window and multimodal capabilities. From video understanding to processing 1000 page PDFs, there are so many new use cases still to be built. Today we are announcing a 64% price reduction on input tokens, a 52% price reduction on output tokens, and a 64% price reduction on incremental cached tokens for our strongest 1.5 series model, Gemini 1.5 Pro, effective October 1st, 2024, on prompts less than 128K tokens. Coupled with context caching, this continues to drive the cost of building with Gemini down.

To make it even easier for developers to build with Gemini, we are increasing the paid tier rate limits for 1.5 Flash to 2,000 RPM and increasing 1.5 Pro to 1,000 RPM, up from 1,000 and 360, respectively. In the coming weeks, we expect to continue to increase the Gemini API rate limits so developers can build more with Gemini.
Along with core improvements to our latest models, over the last few weeks we have driven down the latency with 1.5 Flash and significantly increased the output tokens per second, enabling new use cases with our most powerful models.

Since the first launch of Gemini in December of 2023, building a safe and reliable model has been a key focus. With the latest versions of Gemini (-002 models), we’ve made improvements to the model's ability to follow user instructions while balancing safety. We will continue to offer a suite of safety filters that developers may apply to Google’s models. For the models released today, the filters will not be applied by default so that developers can determine the configuration best suited for their use case.
We are releasing a further improved version of the Gemini 1.5 model we announced in August called “Gemini-1.5-Flash-8B-Exp-0924.” This improved version includes significant performance increases across both text and multimodal use cases. It is available now via Google AI Studio and the Gemini API.
The overwhelmingly positive feedback developers have shared about 1.5 Flash-8B has been incredible to see, and we will continue to shape our experimental to production release pipeline based on developer feedback.
We're excited about these updates and can't wait to see what you'll build with the new Gemini models! And for Gemini Advanced users, you will soon be able to access a chat optimized version of Gemini 1.5 Pro-002.

Bridging the Domain Gap: AI Race Coach built with Antigravity and Gemini

Turn creative prompts into interactive XR experiences with Gemini

LiteRT.js, Google's high performance Web AI Inference

How we built the Google I/O 2026 Save the Date experience

We terminated a TPU mid-training and it recovered in seconds: Introduction to elastic training with MaxText