TensorFlow Benchmarks and a New High-Performance Guide
Posted by Josh
Gordon on behalf of the TensorFlow
team
We recently published a collection of performance
benchmarks that
highlight TensorFlow's speed and scalability when training image classification
models, like
InceptionV3 and
ResNet, on a variety of hardware and
configurations.
To help you build highly scalable models, we've also added a new
High-Performance
Models guide to the
performance site on
tensorflow.org. Together with the guide, we
hope these benchmarks and associated scripts will serve as a reference point as
you tune your code, and help you get the most performance from your new and
existing hardware.
When running benchmarks, we tested using both real and synthetic data. We feel
this is important to show, as it exercises both the compute and input pipelines,
and is more representative of real-world performance numbers than testing with
synthetic data alone. For transparency, we've also shared our scripts and
methodology.
Collected below are highlights of TensorFlow's performance when training with an
NVIDIA®
DGX-1™, as well as with 64 NVIDIA® Tesla® K80 GPUs running in a distributed
configuration. In-depth results, including details like batch-size and
configurations used for the various platforms we tested, are available on the
benchmarks site.
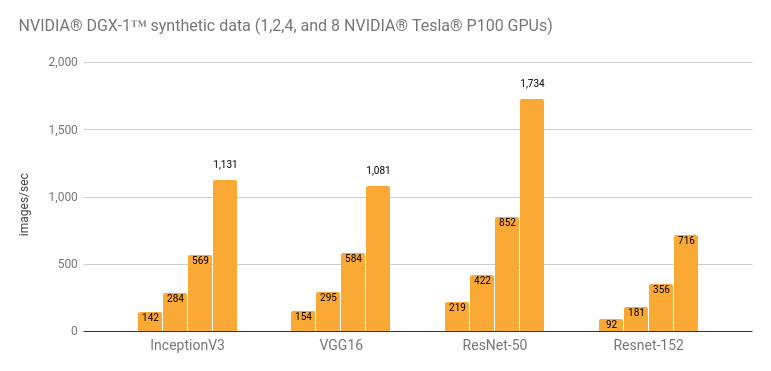
Training with NVIDIA® DGX-1™ (8 NVIDIA® Tesla® P100s)
Our benchmarks show that TensorFlow has nearly
linear scaling on an
NVIDIA® DGX-1™
for training image classification models with synthetic data. With 8 NVIDIA
Tesla P100s, we report a speedup of 7.99x (99% efficiency) for InceptionV3 and
7.91x (98% efficiency) for ResNet-50, compared to using a single GPU.
The following are results comparing training with synthetic and real data. The
benchmark results show a small difference between training data placed
statically on the GPU (synthetic) and executing the full input pipeline with
data from ImageNet. One strength of TensorFlow is the ability of its input
pipeline to saturate state-of-the-art compute units with large inputs.
Training with NVIDIA® Tesla® K80 (Single server, 8
GPUs)
With 8 NVIDIA® Tesla® K80s in a single-server configuration, TensorFlow has a
7.4x speedup on Inception v3 (93% efficiency) and a 7.4x speedup on ResNet-50,
compared to a single GPU. For this benchmark, we used Google Compute Engine
instances.
Distributed Training with NVIDIA® Tesla® K80 (up to 64
GPUs)
With 64 Tesla K80s running on Amazon EC2
instances
in a distributed configuration, TensorFlow has a 59x speedup (92% efficiency)
for InceptionV3 and a 52x speedup (82% efficiency) for ResNet-50 using synthetic
data.
Discussion
During our testing of the DGX-1 and other platforms, we explored a variety of
configurations using
NCCL,
a collective communications library, part
of the
NVIDIA Deep
Learning SDK. Our hypothesis before testing
began was that replicating the variables across GPUs and syncing them with NCCL
would be the optimal approach. The results were not always as expected. Optimal
configurations varied depending not only on the GPU, but also on the platform
and model tested. On the DGX-1, for example, VGG16 and AlexNet performed best
when replicating the variables on each of the GPUs and updating them using NCCL,
while InceptionV3 and ResNet performed best when placing the shared variable on
the CPU. These intricacies highlight the need for comprehensive benchmarking.
Models have to be tuned for each platform, and a one size fits all approach is
likely to result in suboptimal performance in many cases.
To get peak performance, it is necessary to benchmark with a mix of settings to
determine which ones are likely to perform best on each platform. The script
that accompanies the article on creating
High-Performance
Models was created not only to illustrate how to achieve the highest
performance, but also as a tool to benchmark a platform with a variety of
settings. The benchmarks page lists the configurations that we found which
provided optimal performance for the platforms tested.
As many people have pointed out in response to various benchmarks that have been
performed on other platforms, increases to samples per second does not
necessarily correlate to faster convergence, and as batch sizes increase it can
be more difficult to converge to the highest accuracy levels.
As a team, we hope to do future tests that focus on time to convergence to high
levels of accuracy. We hope these numbers and the guide will prove useful to you
as you tune your code for performance.
We'd like to thank NVIDIA for sharing a DGX-1 for benchmark testing and for
their technical assistance. We're looking forward to NVIDIA's upcoming
Volta
architecture, and to working closely with them to optimize TensorFlow's
performance there, and to expand support for FP16.
Thanks for reading, and as always, we look forward to working with you on forums
like
GitHub
issues,
Stack
Overflow, the
discuss@tensorflow.org
list, and
@TensorFlow.