
Posted by Paul McCartney, Software Engineer, Vivek Kwatra, Research Scientist, Yu Zhang, Research Scientist, Brian Colonna, Software Engineer, and Mor Miller, Software Engineer

People increasingly look to video as their preferred way to be better informed, to explore their interests, and to be entertained. And yet a video’s spoken language is often a barrier to understanding. For example, a high percentage of YouTube videos are in English but less than 20% of the world's population speaks English as their first or second language. Voice dubbing is increasingly being used to transform video into other languages, by translating and replacing a video’s original spoken dialogue. This is effective in eliminating the language barrier and is also a better accessibility option with regard to both literacy and sightedness in comparison to subtitles.
In today’s post, we share our research for increasing voice dubbing quality using deep learning, providing a viewing experience closer to that of a video produced directly for the target language. Specifically, we describe our work with technologies for cross-lingual voice transfer and lip reanimation, which keeps the voice similar to the original speaker and adjusts the speaker’s lip movements in the video to better match the audio generated in the target language. Both capabilities were developed using TensorFlow, which provides a scalable platform for multimodal machine learning. We share videos produced using our research prototype, which are demonstrably less distracting and - hopefully - more enjoyable for viewers.
Voice casting is the process of finding a suitable voice to represent each person on screen. Maintaining the audience’s suspension of disbelief by having believable voices for speakers is important in producing a quality dub that supports rather than distracts from the video. We achieve this through cross-lingual voice transfer, where we create synthetic voices in the target language that sound like the original speaker voices. For example, the video below uses an English dubbed voice that was created from the speaker’s original Spanish voice.
| Original “Coding TensorFlow” video
clip in Spanish. |
| The “Coding TensorFlow” video clip dubbed from Spanish to English, using cross-lingual voice transfer and lip reanimation. |
Inspired by few-shot learning, we first pre-trained a multilingual TTS model based on our cross-language voice transfer approach. This approach uses an attention-based sequence-to-sequence model to generate a series of log-mel spectrogram frames from a multilingual input text sequence with a variational autoencoder-style residual encoder. Subsequently, we fine-tune the model parameters by retraining the decoder and attention modules with a fixed mixing ratio of the adaptation data and original multilingual data as illustrated in Figure 1.
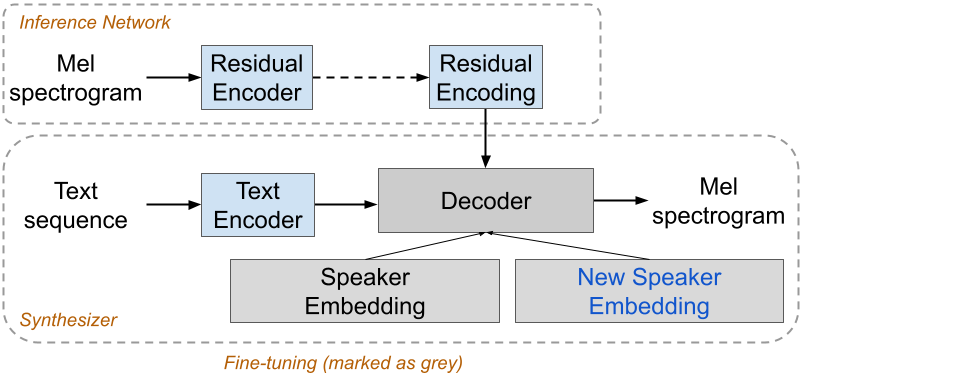 |
| Figure 1: Voice transfer architecture |
Note that voice transfer and lip reanimation is only done when the content owner and speakers give consent for these techniques on their content.
With conventionally dubbed videos, you hear the translated / dubbed voices while seeing the original speakers speaking the original dialogue in the source language. The lip movements that you see in the video generally do not match the newly dubbed words that you hear, making the combined audio/video look unnatural. This can distract viewers from engaging fully with the content. In fact, people often even intentionally look away from the speaker’s mouth while watching dubbed videos as a means to avoid seeing this discrepancy.
To help with audience engagement, producers of higher quality dubbed videos may put more effort into carefully tailoring the dialogue and voice performance to partially match the new speech with the existing lip motion in video. But this is extremely time consuming and expensive, making it cost prohibitive for many content producers. Furthermore, it requires changes that may slightly degrade the voice performance and translation accuracy.
To provide the same lip synchronization benefit, but without these problems, we developed a lip reanimation architecture for correcting the video to match the dubbed voice. That is, we adjust speaker lip movements in the video to make the lips move in alignment with the new dubbed dialogue. This makes it appear as though the video was shot with people originally speaking the translated / dubbed dialogue. This approach can be applied when permitted by the content owner and speakers.
For example, the following clip shows a video that was dubbed in the conventional way (without lip reanimation):
| "Machine Learning Foundations”
video clip dubbed from English to Spanish, with voice transfer, but without lip
reanimation |
Notice how the speaker’s mouth movements don’t seem to move naturally with the voice. The video below shows the same video with lip reanimation, resulting in lip motion that appears more natural with the translated / dubbed dialogue:
| The dubbed “Machine Learning
Foundations” video clip, with both voice transfer and lip reanimation |
For lip reanimation, we train a personalized multistage model that learns to map audio to lip shapes and facial appearance of the speaker, as shown in Figure 2. Using original videos of the speaker for training, we isolate and represent the faces in a normalized space that decouples 3D geometry, head pose, texture, and lighting, as described in this paper. Taking this approach allows our first stage to focus on synthesizing lip-synced 3D geometry and texture compatible with the dubbed audio, without worrying about pose and lighting. Our second stage employs a conditional GAN-based approach to blend these synthesized textures with the original video to generate faces with consistent pose and lighting. This stage is trained adversarially using multiple discriminators to simultaneously preserve visual quality, temporal smoothness and lip-sync consistency. Finally, we refine the output using a custom super-resolution network to generate a photorealistic lip-reanimated video. The comparison videos shown above can also be viewed here.
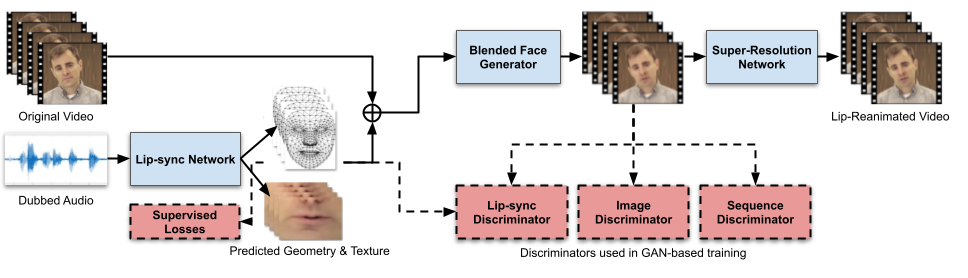 |
| Figure 2: Lip-Reanimation Pipeline: inference blocks in blue, training blocks in red. |
The techniques described here fall into the broader category of synthetic media generation, which has rightfully attracted scrutiny due to its potential for abuse. Photorealistically manipulating videos could be misused to produce fake or misleading information that can create downstream societal harms, and researchers should be aware of these risks. Our use case of video dubbing, however, highlights one potential socially beneficial outcome of these technologies. Our new research in voice dubbing could help make educational lectures, video-blogs, public discourse, and other formats more widely accessible across a global audience. This is also only applied when consent has been given by the content owners and speakers.
We strongly believe that dubbing is a creative process. With these techniques, we strive to make a broader range of content available and enjoyable in a variety of other languages.
We hope that our research inspires the development of new tools that democratize content in a responsible way. To demonstrate its potential, today we are releasing dubbed content for two online educational series, AI for Anyone and Machine Learning Foundations with Tensorflow on the Google Developers LATAM channel.
We have been actively working on expanding our scope to more languages and larger demographics of speakers — we have previously detailed this work, along with a broader discussion, in our research papers on voice transfer and lip reanimation.
