
VTuber,即虚拟 YouTube 创作者,是指那些利用计算机图形技术生成虚拟形象的网络艺人。这一数字化趋势起源于 2010 年代中期的日本,并逐渐成为一种国际网络娱乐方式。大多数 VTuber 是使用虚拟形象进行活动的英语和日语 YouTube 创作者或直播主播。
日本电信运营商 KDDI 拥有超过 4,000 万客户,该公司希望在其 5G 网络上尝试各种技术应用,但他们发现在实时环境下捕捉准确的动作和逼真的人类面部表情是一项具有挑战性的任务。
在 2023 年 5 月的 Google I/O 大会上,我们公布了 MediaPipe Face Landmarker 解决方案。该方案能够检测面部标记并输出混合形状分数,以渲染与用户匹配的 3D 人脸模型。借助 MediaPipe Face Landmarker 解决方案,KDDI 以及 Google 合作伙伴创新团队成功地使该公司的虚拟形象变得更为逼真。
使用 Mediapipe 强大且高效的 Python 软件包,KDDI 的开发者能够实时检测表演者的面部特征,并提取出 52 种混合形状。
import mediapipe as mp
from mediapipe.tasks import python as mp_python
MP_TASK_FILE = "face_landmarker_with_blendshapes.task"
class FaceMeshDetector:
def __init__(self):
with open(MP_TASK_FILE, mode="rb") as f:
f_buffer = f.read()
base_options = mp_python.BaseOptions(model_asset_buffer=f_buffer)
options = mp_python.vision.FaceLandmarkerOptions(
base_options=base_options,
output_face_blendshapes=True,
output_facial_transformation_matrixes=True,
running_mode=mp.tasks.vision.RunningMode.LIVE_STREAM,
num_faces=1,
result_callback=self.mp_callback)
self.model = mp_python.vision.FaceLandmarker.create_from_options(
options)
self.landmarks = None
self.blendshapes = None
self.latest_time_ms = 0
def mp_callback(self, mp_result, output_image, timestamp_ms: int):
if len(mp_result.face_landmarks) >= 1 and len(
mp_result.face_blendshapes) >= 1:
self.landmarks = mp_result.face_landmarks[0]
self.blendshapes = [b.score for b in mp_result.face_blendshapes[0]]
def update(self, frame):
t_ms = int(time.time() * 1000)
if t_ms <= self.latest_time_ms:
return
frame_mp = mp.Image(image_format=mp.ImageFormat.SRGB, data=frame)
self.model.detect_async(frame_mp, t_ms)
self.latest_time_ms = t_ms
def get_results(self):
return self.landmarks, self.blendshapes
Firebase 实时数据库存储包含 52 个混合形状浮点值的集合。每行对应一种按顺序排列的特定混合形状。
_neutral,
browDownLeft,
browDownRight,
browInnerUp,
browOuterUpLeft,
...
当相机开启且 FaceMesh 模型运行时,这些混合形状值会持续地实时更新。对于每一帧画面,数据库都会反映最新的混合形状数值,从而捕捉 FaceMesh 模型所检测到的面部表情动态变化。
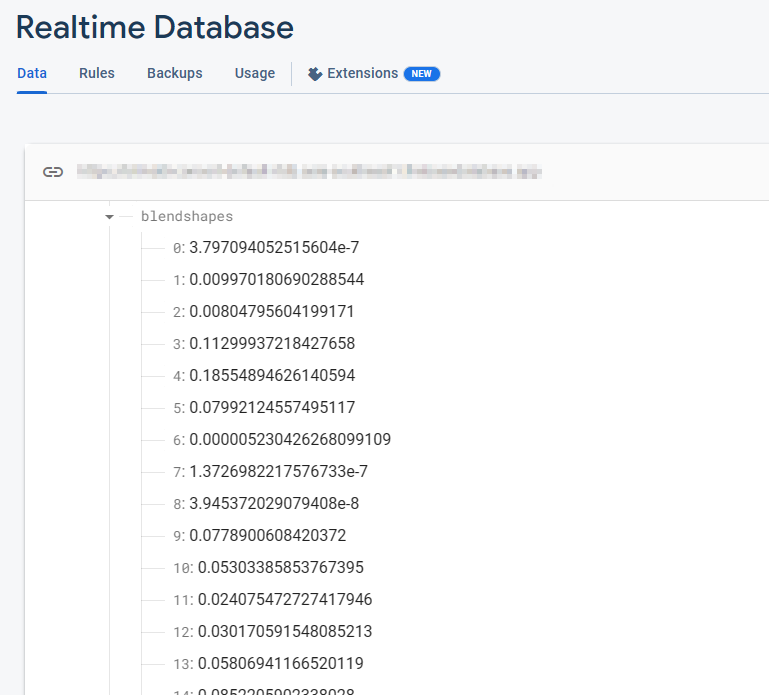
提取混合形状数据后,下一步就是将这些数据传输到 Firebase 实时数据库。这种先进的数据库系统可确保实时数据无缝流向客户端,从而消除对服务器可扩展性的担忧。此外,该系统还有助于 KDDI 专注于提供简化的用户体验。
import concurrent.futures
import time
import cv2
import firebase_admin
import mediapipe as mp
import numpy as np
from firebase_admin import credentials, db
pool = concurrent.futures.ThreadPoolExecutor(max_workers=4)
cred = credentials.Certificate('your-certificate.json')
firebase_admin.initialize_app(
cred, {
'databaseURL': 'https://your-project.firebasedatabase.app/'
})
ref = db.reference('projects/1234/blendshapes')
def main():
facemesh_detector = FaceMeshDetector()
cap = cv2.VideoCapture(0)
while True:
ret, frame = cap.read()
facemesh_detector.update(frame)
landmarks, blendshapes = facemesh_detector.get_results()
if (landmarks is None) or (blendshapes is None):
continue
blendshapes_dict = {k: v for k, v in enumerate(blendshapes)}
exe = pool.submit(ref.set, blendshapes_dict)
cv2.imshow('frame', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
exit()
我们取得了进一步进展,开发者能够无缝地将从 Firebase 实时数据库中获取的混合形状数据实时传输到 Google Cloud 的 XR 沉浸式直播实例。Google Cloud 的 XR 沉浸式直播是一项代管式服务,可在云端运行 Unreal Engine 项目,实时向智能手机和浏览器渲染和流式传输逼真的 3D 沉浸式体验以及增强现实 (AR) 体验。
通过这种集成,KDDI 能够以最小的延迟驱动角色的面部动画并实现该动画的实时流式传输,从而确保为用户提供沉浸式体验。
在由 XR 沉浸式直播驱动的 Unreal Engine 端,我们使用 Firebase C++ SDK 来无缝地从 Firebase 获取数据。通过建立数据库监听器,每当 Firebase 实时数据库表中有更新时,我们便能立即获取混合形状值。这种集成方式使得我们可以实时访问最新的混合形状数据,从而在 Unreal Engine 项目中实现动态和响应式面部动画。
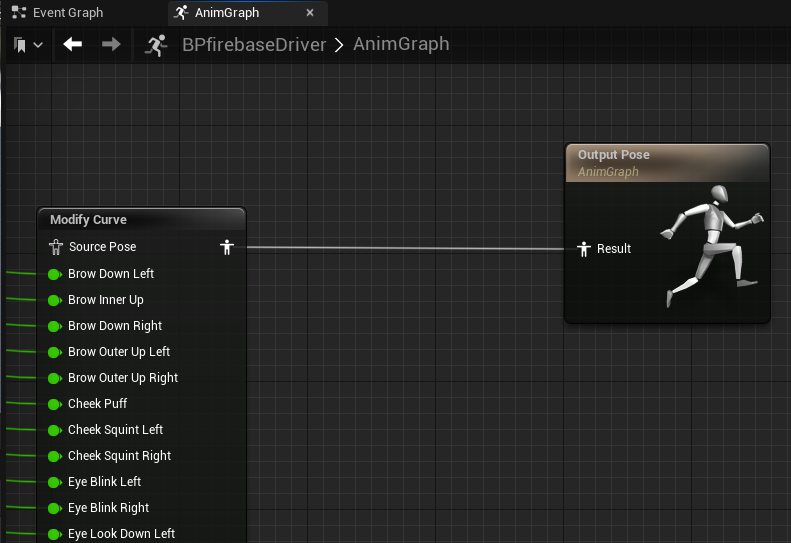
从 Firebase SDK 获取混合形状值之后,我们可以在 Unreal Engine 中通过动画蓝图中的“修改曲线”节点来驱动角色的面部动画。每个混合形状值都会在每个帧上单独分配给角色,从而实现对角色面部表情的精确且实时控制。
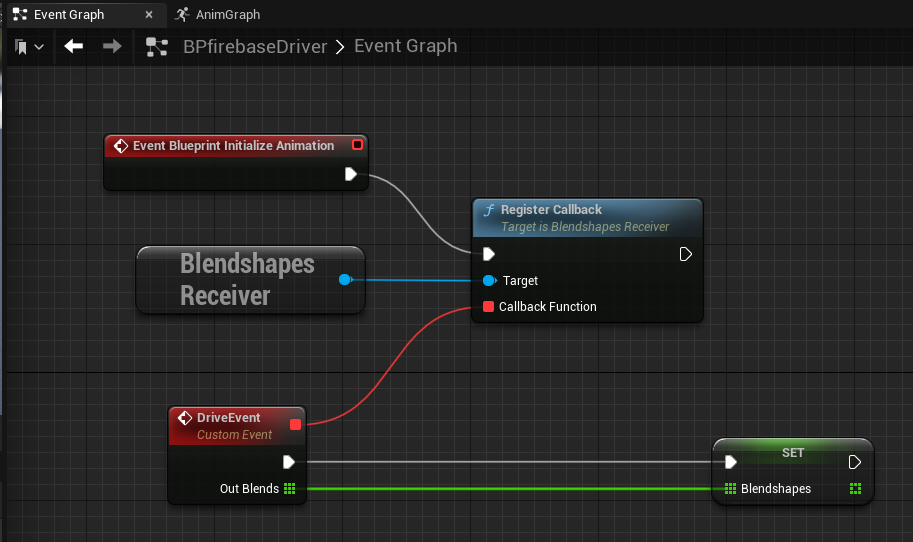
利用 GameInstance Subsystem 可以有效地在 Unreal Engine 中实现实时数据库监听。GameInstance Subsystem 起着替代单例模式的作用。这样一来,开发者可以创建一个专门的 BlendshapesReceiver 实例,以负责在后台处理数据库连接、身份验证和连续数据接收任务。
通过利用 GameInstance Subsystem,我们可以在整个游戏会话期间创建并维护 BlendshapesReceiver 实例,从而确保实例能够与数据库持续连接。与此同时,动画蓝图可以根据接收到的混合形状数据读取并驱动面部动画。
通过在本地 PC 上运行 MediaPipe,KDDI 成功捕捉了真人表演者的面部表情和动作,并实时生成了高质量的 3D 重新目标动画。
KDDI 正在与 Adastria Co., Ltd. 等元宇宙动漫时尚开发商合作。
如需了解更多信息,请观看 2023 年 Google I/O 大会课程:使用 MediaPipe 轻松实现设备端机器学习、使用机器学习和 MediaPipe 增强 Web 应用,以及机器学习的新功能,并查看 developers.google.com/mediapipe 上的官方文档。
MediaPipe 的整合应用是 KDDI 消除现实与虚拟世界之间界限的一个示例。通过这种方式,用户可以随时随地享受到诸如参加现场音乐会、欣赏艺术作品、与朋友交谈以及购物等日常体验。
KDDI 的“αU”服务专为 Web3 时代设计,涵盖了诸如元宇宙、直播和虚拟购物等多个领域。该服务旨在塑造一个任何人都可以成为内容创作者的生态系统,使新一代用户可以在现实世界与虚拟世界之间无缝切换。